

Schicke Frontends wollen beim Umgang mit der OCR-Engine Tesseract helfen. Wie gut das gelingt, zeigt ein Test.
Das entwickeln einer Zeichenerkennungssoftware gehört zu den schwierigsten Aufgaben beim Programmieren von Applikation. Obwohl solche Tools im Büroalltag vor allem beim professionellen Dokumentenmanagement schon aufgrund gesetzlicher Vorschriften nahezu unentbehrlich sind, gibt es nur wenige ausgereifte Applikationen in dieser Disziplin. Unter Linux herrschte beim Thema OCR-Software lange Zeit eisiges Schweigen. Mittlerweile schicken sich verschiedene Projekte mit unterschiedlichen Schwerpunkten und innovativen Technologien an, um zu den gängigen Industriestandards aufzuschließen. Zu den ältesten OCR-Programmen, dessen Anfänge bis in das Jahr 1985 zurückreichen, gehört Tesseract [1]. Die ursprünglich vom US-Computerriesen Hewlett-Packard entwickelte Software steht nach einer wechselvollen Geschichte nunmehr unter der Obhut von Google und dient unter anderem als Grundlage für den Dienst Google Books.
Installation mit Hürden
Da sich die Software bereits bei praktisch allen gängigen Linux-Distributionen in den Repositories befindet, ist eine schnelle Installation über die grafische Oberfläche mithilfe von Synaptics, dem Kontrollzentrum von Mandriva oder YaST möglich. Durch den modularen Aufbau des Programms benötigen Sie jedoch – sofern Sie andere als englischsprachige Texte bearbeiten wollen – mindestens ein entsprechendes zusätzliches Sprachmodul.
Tesseract bietet solche Module für alle Weltsprachen an. Als besonderes Alleinstellungsmerkmal liegt außerdem ein Sprachmodul für deutsche Frakturschriften vor, welches zu den Kandidaten in diesem Test gehört. Allerdings handhaben die Linux-Distributionen die Installation der Sprachmodule etwas unterschiedlich: Während Mandriva 2010.1 sofort eine Liste mit den vorhandenen Idiomen zur Auswahl anbot, lief bei einem frisch aufgesetzten Ubuntu 10.04 die Installation ohne einen entsprechenden Hinweis durch. In der Folge kam es zu katastrophalen Testergebnissen beim ersten Arbeiten.
Dieser Mangel in Ubuntus Installationsroutine führt zu einer ebenfalls mangelhaften Modulauswahl bei Tesseract. Ubuntu-Nutzer sollten daher gleich nach dem frischen Aufsetzen des Betriebssystems die Lokalisierung vervollständigen, um anschließend Software entsprechend den regionalen Bedingungen optimal zu installieren. Haben Sie die entsprechenden Module auf die Platte gehoben, ist Tesseract einsatzbereit für die Arbeit mit deutschen Texten.
Kapriziöse GUI
Die Entwickler haben Tesseract auf das Einlesen und Erkennen von großen Textmengen hin optimiert – ähnlich wie Cuneiform. Da die Software verfügt über keine grafische Benutzeroberfläche und erlaubt zudem den unbeaufsichtigen Einsatz im Batch-Betrieb. Wie beim Konkurrenten Cuneiform gibt es jedoch für Anwender, die nicht automatisiert ganze Bibliotheken digitalisieren möchten, mehrere grafische Aufsätze zu Tesseract.
Als erster Kandidat kommt im Test die noch sehr junge Oberfläche OCRGui zum Einsatz, die im Netz [2] oder auf der Heft-DVD als RPM-Paket oder Tar.gz-Archiv erhältlich ist und eine ähnliche Oberfläche bietet, wie Yagf für Cuneiform. Die Installation unter Mandriva 2010.1 verlief ohne Probleme, beim Aufruf des Programms führte jedoch das Anklicken des Einstellungsdialogs wiederholt zum sofortigen Absturz der Software, so dass es nicht möglich war, die nötigen Angaben zu Pfaden, Schriften und der OCR-Engine Tesseract vorzunehmen. Unter Ubuntu 10.04 ließen permanente Abstürze von OCRGui ebenfalls keine rechte Freude aufkommen, so dass der Kandidat an dieser Stelle wieder aus dem Test ausschied.
OCRFeeder
Als zweiten Kandidat trat OCRFeeder [3] an die Startlinie. Das Programm setzt als OCR-Engine ebenfalls Tesseract voraus und integriert über die Software Unpaper [4] Optionen, um schlechte Vorlagen zu verbessern. Neben den DEB-Paketen und Tar.gz-Archiven, die Sie auf der Projektseite finden, stehen auch vorkompilierte RPM-Pakete für Mandriva und PCLinuxOS bereit ([5],[6]).
Unter Mandriva 2010.1 legt die Installationsroutine einen Starter im Gnome-Menü Anwendungen | Büroprogramme an. Die OCRFeeder-Entwickler haben sich optisch und unter der Haube stark an Gnome orientiert, und daher integriert sich die Software bestens in die GTK-basierte Oberfläche.
Nach einem sehr zügigen Start des Programms finden Sie ein sehr spartanisch anmutendes Programmfenster vor: Eine Menüleiste mit lediglich sechs Untermenüs sowie eine Buttonleiste mit fünf Schaltflächen machen die einzigen Bedienelemente der Software aus. Das Programm zeigt das einzulesende Bild im unteren Bereich des Fensters mittig an. Bei mehrseitigen Dokumenten sehen Sie links die einzelnen Seiten in einer verkleinerten Ansicht.
Ein Blick in die Menüs und auf die Buttonleiste fördert einige Besonderheiten zutage: So liest die Software PDF-Dateien ein, obwohl Tesseract als Basis in der Variante für die Kommandozeile ausschließlich mit Grafiken im TIF-Format zurechtkommt. Eine Schaltlfäche ermöglicht zudem den Export des extrahierten Textes in das ODT-Format. So haben Sie die Möglichkeit, die Datei anschließend ohne weiteres Konvertieren im Writer-Modul des freien Büropakets weiterzuverarbeiten.
Zunächst müssen Sie jedoch eine Datei öffnen, was Sie durch Anklicken der Schaltfläche mit dem Pluszeichen oben links in der Buttonleiste erledigen. Ein Bild direkt zu öffnen, gelingt nur, wenn dieses zwingend im TIF-Format vorliegt und darf nur das Suffix .tif aufweisen. Möchten Sie ein PDF-Dokument einlesen, so tun Sie dies über Anklicken des Menüpunktes Datei | PDF importieren.
Nach dem Einlesen der Bilddatei klicken Sie auf den zweiten Button von links Automatische Detektion und Erkennung. OCRFeeder analysiert das Dokument und bildet um die einzelnen Teile farbige Rahmen. Texte hinterlegt es hellblau; Bilder oder Elemente mit bildlichem Inhalt in einem hellen Grünton (Abbildung 1).

Abbildung 1: Selbst komplexe PDF-Dokumente analysiert OCRFeeder eingehend und zuverlässig.
OCRFeeder fügt dem Ansichtsfenster nun rechts einen zusätzlichen dritten Bereich hinzu, in dem er die Analyseergebnisse anzeigt. Im Test mit einem mehrseitigen, sehr komplexen bebilderten Dokument erwies sich die Analyse und das Erkennen der einzelnen Seitenelemente als höchst zuverlässig. Ein Klick auf die einzelnen Farbrahmen im mittleren Ansichtsbereich zeigt anschließend rechts im Programmfenster die jeweiligen Analyseergebnisse an.
Damit nicht die Software beim Erkennen der Texte durch Bildelemente aus dem Konzept gerät, blenden Sie Elemente, die die Software als Bilder erkannt hat, aus. Dies geschieht, indem Sie auf den entsprechenden Farbrahmen klicken und im Funktionsmenü den Eintrag Dokument | Ausgewählte Bereiche löschen wählen. Sie dürfen selbstverständlich mehrere Rahmen markieren. Das tun Sie, indem Sie diese bei gleichzeitigem Drücken von [Umschalt] anklicken.
OCRFeeder entfernt nun um die ausgewählten Bereiche die Rahmen und deaktiviert sie somit. Ein Klick auf den Button OCR rechts mittig im Programmfenster startet nach eventueller Rahmenauswahl die eigentliche Arbeit. Bei Bedarf korrigieren Sie das Ergebnis anschließend unten rechts im Fenster oder speichern es gleich speichern durch Aufrufen des Menüpunktes Datei | Speichern. Die Software legt das Dokument sodann im programmeigenen OCRF-Format auf die Platte.
Wollen Sie das Dokument im Writer-Format ablegen, klicken Sie lediglich in der Buttonleiste auf den OpenOffice-Schaltknopf und geben im sich öffnenden Fenster Pfad und Dateinamen an. Bei mehrseitigen Dokumenten fragt OCRFeeder vor dem Speichern noch ab, ob Sie das gesamte Dokument oder nur die aktuelle Seite speichern möchten.
Not really amused
Die Ergebnisse mit OCRFeeder taugen für deutsche Anwender nur sehr bedingt, was umso mehr erstaunt, weil das Programm im Test komplexe PDF-Dokumente zuverlässig analysierte. Die eigentliche Texterkennung selbst lässt jedoch viele Wünsche offen. So kommt OCRFeeder trotz installiertem Ocropus nicht mit dem in Zeitschriften und Fachmagazinen üblichen Spaltensatz zurecht. Folglich war das Ergebnis trotz eigentlich guter Erkennungsrate nicht zu gebrauchen.
Ein weiteres Manko liegt in der Tatsache, dass die Software keine komfortable Möglichkeit zum Umschalten der Sprache beinhaltet, wie beispielsweise Yagf oder Cuneiform-Qt, so dass stets das englische Sprachmodul von Tesseract zum Einsatz kommt. Dadurch ließt die Applikation jegliche deutschen Umlaute und Sonderzeichen falsch aus. Wer englischsprachige Fließtexte ohne Spalten mit OCRFeeder bearbeitet, findet allerdings bei entsprechend guten Vorlagen kaum Fehler. Für deutsche Anwender ist die Software jedoch in den meisten Fällen weniger hilfreich.
Tesseract-gui
Der dritte Kandidat ist Tesseract-gui. Das kleine Programm erhalten Sie in verschiedenen Versionen als Tar-Archiv und als DEB-Paket im Web [7] oder von der Heft-DVD. RPM-Pakete ließen sich auch auf den gängigen Suchseiten im Internet nicht finden, so dass es notwendig war, für den Test das aktuellste DEB-Paket mithilfe des im Terminal eingegebenen Befehls alien -r tesseract-gui_2.7-2_all.deb in ein RPM-Paket zu konvertieren. Damit ließ sich Tesseract-gui ohne Murren unter Mandriva 2010.1 installieren, wobei die Routine einen entsprechenden Starter TesseractGUI im Gnome-Menü Anwendungen | Büroprogramme anlegt.
Der nachfolgende Start der Software verlief ebenso rasant wie problemlos. Tesseract-gui bietet eine ungewöhnliche Oberfläche: Sowohl die von den meisten Anwendungen her bekannte Menüleiste als auch die Buttonleiste zum Schnellzugriff auf Funktionen per Schaltlfäche fehlen komplett. Stattdessen kommt die Software mit einem lediglich zweigeteilten Fenster. Während Sie im linken Bereich Einstellungen wie Pfadangaben und Dateinamen sowie Modifikationen zum Verbessern der Bildvorlagen vornehmen, ist der ungleich größere rechte Fensterbereich zunächst komplett leer.
Um das korrekte Bedienen des Programms sicherzustellen, deaktiviert die Software kontextsensitiv nicht vorhandene Funktionen. Zunächst gilt es, mithilfe eines Klicks auf die Schaltfläche Select image files eine Bilddatei zu öffnen. Die Software erweitert dabei die einlesbaren Dokumente um die Dateiformate JPEG und PNG. Das zur Texterkennung vorgesehene Bild positioniert das Programm zunächst links mittig in einem Listenfenster mit Pfadangabe. Ein Klick auf den Dateinamen liest die Bilddatei sodann ein. Nach dem Laden stehen im linken Fensterbereich alle Funktionen bereit.
Testfall Fraktur
Gleich im ersten Testdurchlauf sah sich Tesseract-gui mit einer schlecht eingescannten Buchseite mit Frakturschrift konfrontiert. Das Ergebnis, abgelegt in einer reinen Textdatei ohne Formatierungen, war erwartungsgemäß nicht zu gebrauchen. Tesseract-gui bietet jedoch im linken Fensterbereich mehrere Optionen, um ungeeignete Vorlagen aufzubessern, wobei Sie die Möglichkeit haben, das Ergebnis der Modifikationen gleich im rechten Fensterbereich zu überprüfen.
Es ist somit oft nicht mehr nötig, mithilfe einer externen Bildbearbeitung wie Gimp Vorlagen zu verbessern. Durch ein Setzen eines Häkchens bei Contrast entfernt die Software die bei Graustufenscans unvermeidlichen Schatten und Hintergründe aus der Bildvorlage. Ein Setzen des Häkchens vor der Option Denoise erhöht die Bildschärfe, wobei Sie diesen Parameter bei Bedarf durch einen Schieberegler individuell anpassen.
Enthält der Text Spalten und Rahmen, die die Trefferrate verschlechtern, wählen Sie mithilfe einer sogenannten Crop-Funktion explizit die Bereiche der Datei aus, die Sie mit Tesseract bearbeitet wollen. Dazu fahren Sie mit dem Mauszeiger über die Bilddatei. Der Zeiger verändert sich jetzt zu einem roten Quadrat. Sobald Sie die linke Maustaste gedrückt halten, können Sie ein Rechteck aufziehen, das einen rot-gestrichelten Rahmen hat (Abbildung 2). Nur jene Textteile, die sich innerhalb des Rahmens befinden, analysiert die Software nach einem Klick auf den Button Ausführen im unteren linken Segment des Fensters.
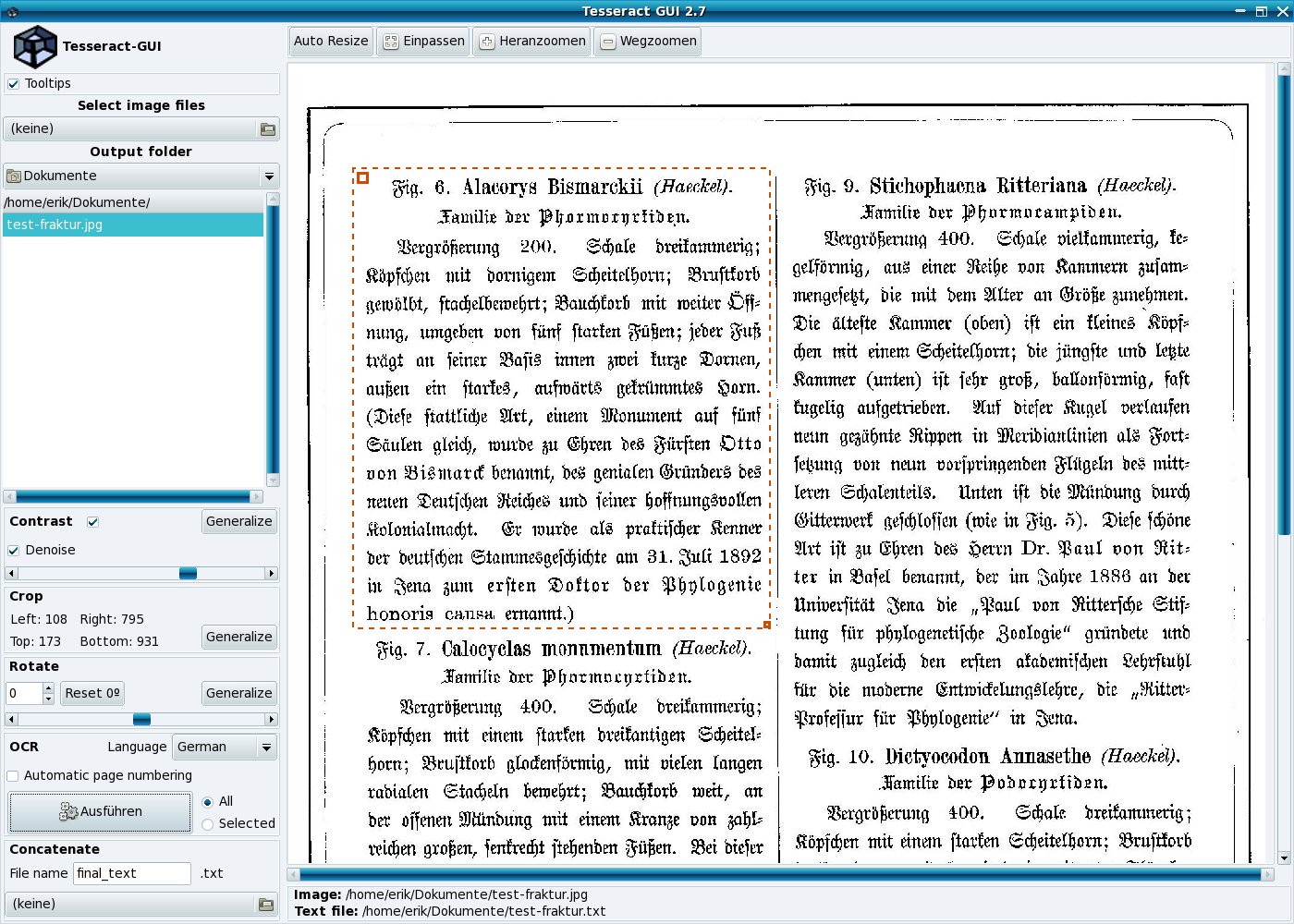
Abbildung 2: Spalten verlieren ihren Schrecken dank der Crop-Funktion.
Die Analyseergebnisse legt Tesseract-gui im vordefinierten Verzeichnis ab, wobei es einfache Textdateien generiert. Zur Information zeigt die Applikation Ein- und Ausgabedatei mitsamt dem vollständigen Pfad während des Bearbeitens ganz unten mittig im Programmfenster an.
Sprachprobleme
Tesseract-gui zeigte zunächst ebenfalls unbefriedigende Ergebnisse. Das Optionsfeld Language im linken unteren Bereich des Einstellungsfensters war trotz korrekt installierter Sprachmodule von Tesseract ausgegraut. Nach eingehender Inspektion des Sachverhalts offenbarte sich ein Fehler im Installationsskript, das die Sprachmodule an einem falschen Ort erwartet: Während das Kommandozeilenprogramm Tesseract seine linguistischen Dateien im Unterverzeichnis /usr/share/tessdata ablegt, erwartet Tesseract-gui die Module im Unterverzeichnis /usr/share/tesseract-ocr/tessdata.
Ohne einen entsprechenden Softlink oder das Kopieren der Sprachdateien in das meist eigens anzulegende Unterverzeichnis /usr/share/tesseract-ocr ist die grafische Oberfläche auf die englische Sprache eingestellt und erbringt daher in allen anderen Idiomen unbrauchbare Ergebnisse. Nach dem Anpassen der Pfade und einem Neuaufruf des Programms ließ sich problemlos die benötigte Sprache einstellen.
Durchwachsenes
Bei mehreren Testläufen überzeugte Tesseract-gui teilweise: Die Software schaffte es nicht, die Bildvorlagen in Frakturschrift unabhängig vom verwendeten Bildformat und trotz eingehendem Bearbeiten sowohl durch Gimp als auch durch die eigenen, in Tesseract-gui integrierten Werkzeuge, den Text in ein brauchbares Ergebnis umzusetzen.
Völlig anders stellte sich die Situation mit einer unscharf vergrößerten Bildvorlage in englischer Sprache dar: Hier erbrachte das Programm herausragende Ergebnisse bei sehr gutem Datendurchsatz trotz fehlender Nachbearbeitung. Eine ebenfalls unbearbeitete deutschsprachige Textseite setzte es mit einer Erkennungsquote von annähernd hundert Prozent gleich im ersten Durchlauf um (Abbildung 3 und Abbildung 4).

Abbildung 3: Eine nur durchschnittliche Vorlage…

Abbildung 4: …erbringt durchaus gute Ergebnisse.
Im Falle dieser Seite zeigte sich zudem, dass ein nachträgliches Bearbeiten der Bilddatei in manchen Fällen negative Folgen hat: In einem zweiten Durchlauf nach erheblichem Schärfen des Bildes und verstärktem Kontrast häuften sich Erkennungsfehler. Weniger positiv fielen dagegen Vorlagen auf, deren Text sich auf zwei oder mehrere Spalten verteilt. Hier ist es unbedingt nötig, mithilfe der Crop-Funktion die Spalten einzeln einzulesen. Dann erbringt Tesseract-gui gute Ergebnisse.
Fazit
Das Einlesen gescannter Vorlagen mit Tesseract und den grafischen Aufsätzen will sorgfältig vorbereitet und ausgetestet sein. Da die GUIs zum größten Teil noch erheblich hinter den Standards herhinken und teilweise bislang kaum über das Alpha-Stadium hinausgekommen sind, müssen Sie mit unangenehmen Überraschungen rechnen. Als einziger Kandidat, der die Tests befriedigend absolvierte, ließe sich Tesseract-gui empfehlen, wenn Sie gelegentlich einzelne Bilddateien mit Fließtext in Textdateien umsetzen möchten.
Das Frakturmodul hat derzeit noch keinen brauchbaren Standard erreicht, und das Bearbeiten von Texten im Spaltensatz gestaltet sich eher umständlich. Besser sind Sie derzeit für den häuslichen Gebrauch noch mit dem Duo Cuneiform/Yagf beraten, das nicht nur erheblich mehr Sprachen unterstützt, sondern bei erfreulich guten Erkennungsquoten eine für Gelegenheitsanwender bestens geeignete Oberfläche bietet.
Infos
[1] Tesseract: http://code.google.com/p/tesseract-ocr/
[2] OCRGui: http://sourceforge.net/projects/ocrgui/files/
[3] OCRFeeder: http://live.gnome.org/OCRFeeder
[4] Unpaper: http://unpaper.berlios.de
[5] OCRFeeder für Mandriva: http://people.igalia.com/jrocha/ocrfeeder/
[6] OCRFeeder für PCLinuxOS: http://rpm.pbone.net
[7] Tesseract-gui: http://sourceforge.net/projects/tesseract-gui/files/tesseract-gui/
[8] Cuneiform/Yagf: Erik Bärwaldt, “Alphabetisierung”, LinuxUser 04/2011, S. 48, https://www.linux-community.de/22836




