
Dieser Teil der Serie über die Bash stellt die Grundlagen für die Arbeit mit mehreren und verketteten Befehlen auf der Bash zusammen.
Ein Überblick
Kleine Programme, die auf einer Shell ausgeführt werden, heißen “Befehle” (“Commands”). So unterschiedlich ihre Funktionen auch sind, weisen sie doch gewolltermaßen und prinzipiell viele Ähnlichkeiten auf. So verfügt jeder Befehl über drei Ein- und Ausgänge, die für bestimmte festgelegte Aufgaben eingesetzt werden, die Standardkanäle. Befehle können in den Befehlszeilen einzeln, zu mehreren oder in verketteter Form eingegeben werden. Alle Formen haben bestimmte Vorteile und Eigenheiten.
Befehle und Standardkanäle
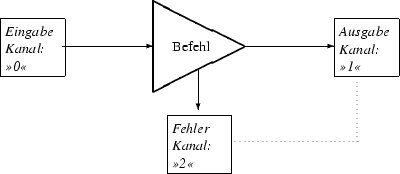
Abbildung 1: Datenfluss und Standardkanäle
Einer der Befehlskanäle stellt dem Befehl ein Tor für Eingaben zur Verfügung. Über ihn liest ein Programm Daten aus einer Datei oder einer Pipe (siehe unten) ein. Dieser Kanal wird daher als “Standardeingabe” (standard input) bezeichnet. Analog gibt es einen Ausgabekanal, die “Standardausgabe” (standard output). Der dritte Kanal (“Standardfehlerausgabe” – standard error) hat eine besondere Funktion: über ihn werden Fehlermeldungen, die der Befehl generiert, ausgegeben. Diese Fehlermeldungen haben unter Linux eine wichtige Funktion, da sie oft Hinweise enthalten, wie ein Problem zu lösen ist. Ein Beispiel: Mit den Befehl grep werden Texte nach bestimmten Zeichenketten durchsucht. Der Befehl muss dazu die Textdaten aus den Dateien erhalten (via Standardeingabekanal). Zeilen, die den entsprechenden Text enthalten, werden ausgegeben (via Standardausgabekanal) und in Fällen, wo ein Problem auftritt – weil etwa eine nicht lesbare Datei angegeben wurde – muss der Befehl dies über die Standardfehlerausgabe melden. Abbildung 1 verdeutlicht die Zusammenhänge. Die Zahlen “0”, “1” und “2” dienen zur Kennzeichnung dieser Kanäle und werden als Datei-Descriptoren bezeichnet. In der Befehlszeile sieht der Anwender nur wenig von diesen Zusammenhängen:
$> grep muster textdatei* grep: textdatei: Ist ein Verzeichnis textdatei1.tex: ein Beispiel "muster" ...
Dieses Beispiel zeigt verschiedene Aspekte auf: Zum einen verwenden viele Befehle (wie auch grep) einige Argumente in der Befehlszeile für Eingaben. Derartige Befehle verwenden meistens das Terminal zur Eingabe, wenn keine entsprechende Eingabedatei beim Befehlsaufruf angegeben wurde.
$> grep geh Das Lesen vom Terminal[RETURN] geht so! geht so! [Strg-d]
(“geht” wird als Suchmuster interpretiert. Mit [Strg][d] wird das Dateiende gekennzeichnet und so die Eingabe beendet.)
Zum anderen wird in dem Beispiel oben das letzte Argument in der Befehlszeile (textdatei*) als Name der Eingabedatei interpretiert. Da der Dateiname ein Sternchen enthält, ersetzt die Shell ihn durch alle passenden Dateinamen (beispielsweise textdatei1.tex, textdatei2.tex, …). Da es auch ein Verzeichnis mit dem Namen “textdatei” gibt, versucht grep zunächst auf dieses zuzugreifen, ein Versuch, der zum Scheitern verurteilt ist und die in der ersten Ausgabezeile dargestellte Fehlermeldung verursacht. Im folgenden sieht man, dass die Textausgaben (also die Zeilen, auf die das angegebene Muster zutraf) auch auf dem Terminal erscheinen. Grund für dieses Verhalten ist die Tatsache, dass normalerweise sowohl Standardausgabe- als auch Standardfehlerkanal auf das Terminal geleitet werden. Das muss aber nicht so sein. Über die Datei-Descriptoren sind beide Kanäle getrennt zugänglich.
Ein- und Ausgabeumleitungen
Der Zugriff auf die Standardkanäle erfolgt über sogenannte “Redirections”- (Umleitungs-) Operatoren. In ihrer einfachsten Form werden sie durch die Zeichen “<” und “>” repräsentiert.
$> befehl < Eingabe befehl > Ausgabe
Im ersten Beispiel erhält der Befehl seine Eingabe über den Standardeingabekanal aus der Datei Eingabe, im zweiten wird die Ausgabe via Standardausgabekanal in die Datei Ausgabe geleitet. Dies sind nur zwei einfache Beispiele für den Einsatz von Datei-Descriptoren und Redirections. Bei grep bietet sich z.B. folgende Konstruktion an:
$> grep muster textdatei* 1>ausgabe 2>fehler
Mit dieser Befehlszeile werden Standardausgabe und Standardfehler in zwei getrennte Dateien geleitet, oft ist es das, was der Anwender will. Datei-Descriptor “1” repräsentiert den Ausgabekanal, “2” den Standardfehlerkanal. (Der Standardeingabekanal wird entsprechend durch “0” repräsentiert.) Voreingestellt ist für die Ausgabe die Verwendung des Datei-Descriptors 1. Daher kann die Angabe dieser Nummer entfallen, beide Zeilen in folgendem Beispiel sind identisch.
$> grep muster textdatei* > Ausgabe grep muster textdatei* 1> Ausgabe
Ganz allgemein können die Nummern von Datei-Descriptoren vor dem Umleitungsoperator angegeben werden. Die Umleitung bezieht sich dann auf den durch den Operator beschriebenen Kanal.
Anmerkung: Wird ein Datei-Descriptor explizit angegeben, so muss der Nummer das Operatorzeichen unmittelbar folgen. Leerzeichen dazwischen sind verboten! Für die Eingabe gilt entsprechendes: Voreingestellt ist der Kanal 0, dessen Nummer nicht explizit genannt werden muss. Zwei Kanäle (üblicherweise Standardfehler und Standardausgabe) lassen sich auch so zusammenschalten, dass sie einen gemeinsamen Datenstrom erzeugen:
grep muster textdatei* 2&>1 grep muster textdatei* 2> 1&> gesam grep muster textdatei* 2&> gesam grep muster textdatei* &> gesam
In der ersten Zeile erfolgt die Ausgabe via Standardfehlerkanal (“2”) dahin, wohin auch Standardausgabe (“1”) geleitet wird. In der zweiten Zeile werden explizit beide Kanäle in die Datei gesamt geleitet. Die dritte Zeile zeigt eine oft verwendete Variante, bei der der Datei-Descriptor für den Standardausgabekanal weggelassen wurde. Das ist korrekt, da diese Angabe voreingestellt ist. Entsprechendes gilt auch für die letzte Variante, hier wurde zusätzlich der Datei-Descriptor für den Standardfehlerkanal eingespart.
Es gibt noch eine Reihe von weiteren Möglichkeiten, Datei-Descriptoren auf der Bash einzusetzen. So können mit dem (eingebauten) Bashbefehl exec zusätzliche Dateien über neue Datei-Descriptoren zugänglich gemacht werden.
$> exec 3> Ausgabe cat textdatei* >&3 cat: textdatei: Ist ein Verzeichnis exec 3>&-
In der ersten Zeile wird eine neue Datei über den Datei-Descriptor “3” geöffnet. Dann wird in diese Datei der Inhalt aller Textdateien, deren Namen das Muster erfüllen, geschrieben (das erledigt der cat-Befehl). Ab jetzt kann auf die Ausgabedatei zugegriffen werden. Abschließend wird die Datei wieder geschlossen.
Bei Verwendung dieser Operatoren werden immer neue Dateien angelegt. Bestehende Dateien mit demselben Namen werden daher kommentarlos gelöscht und ihr Inhalt durch den der neuen Ausgabe überschrieben. Beim Einsatz der Redirection Operatoren handelt es sich also um relativ gefährliche Aktionen. Die Bash kennt daher Mechanismen, das Risiko des Datenverlustes durch Überschreiben zu minimieren.
Zunächst einmal können neue Ausgaben an bestehende Dateien durch das Verdoppeln des Ausgabeoperators an das Ende der bestehenden Datei angehängt werden:
$> grep muster textdatei* 2>>gesamtFehler
Außerdem verfügt die Bash über eine interne Option mit dem Namen “noclobber”, die verhindert, daß vorhandene Dateien durch Redirections überschrieben werden. Diese Option kann bei einer interaktiven Bash durch den eingebauten set-Befehl aktiviert werden:
$> set -o noclobber cat textdatei* > gesam bash: gesamt: cannot overwrite existing file
Alternativ kann diese Option bereits beim Start einer Bash entweder durch die Option -C oder -noclobber eingeschaltet werden. Deaktiviert wird sie durch folgende Befehlszeile:
$> set +o noclobber
Keine Regel ohne Ausnahme: Mit den “Spezial”-Operator “>” können die durch -noclobber gesperrten Dateien überschrieben werden.
Einige Anmerkungen zu den Redirections: Es ist natürlich auch möglich, gleichzeitig sowohl die Standardausgabe als auch die Standardeingabe umzuleiten:
$> tr \ Eingabedatei -s -d '\012' > Ausgabedatei
Der tr-Befehl (translate) liest vom Standardeingabekanal einen Datenstrom, vertauscht (oder löscht) Zeichen in diesem Strom und schreibt das Ergebnis in den Standardausgabekanal. Beide Datenströme (Ein- und Ausgabe) können dabei mittels Redirections in Dateien umgeleitet werden. Von besonderer Bedeutung ist für viele GNU-Befehle der Dateiname “-“. Dieser wird von vielen Befehlen als Standardeingabekanal interpretiert, wenn es keine Datei mit diesem Namen gibt:
$> cat - as[RETURN] as gk[RETURN] gk zuiu[RETURN] zuiu[Strg][d]
Normalerweise wird diese Abkürzung in Dateinamensmustern verwendet, die sowohl aus existierenden Dateien als auch der Standardeingabe bestehen:
$> grep muster textdatei* - textdatei.tex:muster textdatei* ... hallo muster (Standardeingabe):hallo muster
Eine kleine Anmerkung am Rande: Unter Linux können die Standardkanäle auch über Gerätedateien angesprochen werden. Für die Standardeingabe existiert die Datei /dev/stdin, für die Standardausgabe /dev/stdout, und der Fehlerkanal ist über das Gerät /dev/stderr erreichbar.
Die Bash kennt noch zwei weitere spezielle Redirection-Operatoren: Der Operator “\” wird nur in ganz wenigen Fällen eingesetzt. Dieser Operator öffnet die angegebene Datei gleichzeitig zur Ein- und Ausgabe, wie dies manchmal bei Gerätedateien notwendig ist.
Speziell für die Eingaben von einem Terminal wurde der sogenannte “Here Document”-Operator entwickelt, der folgende Form hat: “\\”. Sein Haupteinsatz findet innerhalb von Scripten statt. Die Funktion ist einfach: Der gesamte Text einer Eingabe wird eingelesen, bis eine bestimmte, vorher vereinbarte, Zeichenkette auftritt. Ihr Auftreten beendet die Eingabe dann automatisch.
$> cat \\ Diese Eingabe wird erst durch das Auftreten eines Dollarzeichens beendet!
Als letzter Punkt zu den Umleitungen soll hier noch der (externe) tee-Befehl vorgestellt werden. tee (sprich: tee) steht für ein T-Stück, wie Klempner es zur Verzweigung von Rohrleitungen einsetzen. Zum einen leitet dieses T-Stück die Eingaben direkt an den Ausgang weiter (Abbildung 2), gleichzeitig werden sie aber (unverändert) zusätzlich an einen zweiten Ausgang geführt. Damit verdoppelt tee praktisch die Datenströme. Warum? Der Haupteinsatz liegt in der Zwischenspeicherung von Teilergebnissen, wie sie in einer Befehlskette entstehen.
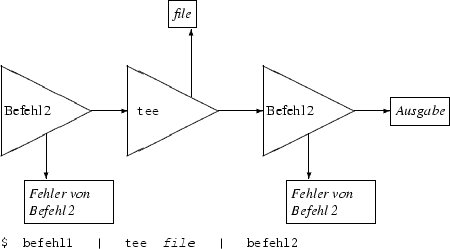
Abbildung 2: Ein T-Stück in den Datenstrom einfügen
Dies führt uns direkt zu den Pipes.
Pipes
Pipes (die Kurzform von Pipelines) heißen die Verbindungen, über die Befehle auf unkomplizierte Art Daten austauschen. Die Ausgabe vom ersten Befehl wird durch eine Pipe direkt mit der Eingabe eines anderen Befehls verbunden. Auf diese Weise werden zusätzliche Dateien, die die Ausgaben sonst zwischenspeichern müssten, vermieden. Der Einsatz von Pipes ist einfach und schnell, wird daher gern und oft benutzt. Als Pipe-Operator wird das “|”-Zeichen verwendet:
$> grep muster textdatei* | less
In diesem Beispiel ist alles wie oben, mit einer Ausnahme: Die von grep erzeugten Ausgaben werden an das Anzeige-(Pager)-Programm less weitergereicht. Der Vorteil liegt dabei auf der Hand: Zur Anzeige stehen die Features von less zur Verfügung, also die Möglichkeit, in den Ausgaben seitenweise vor- und zurückzublättern, Suchfunktionen zu verwenden und vieles mehr. In der Praxis werden derartige Befehlskombinationen recht oft eingesetzt, z.B. wenn es darum geht, den Inhalt von Verzeichnissen aufzulisten:
$> ls -l --color | less -r
Beispiele wie diese werfen auch einen neuen Blick auf den Einsatz von tee. Das erste Programm erzeugt Daten (Ausgabe von grep oder ls), ein weiteres bearbeitet sie und ein drittes wird zur Anzeige verwendet. Die Anzahl der Programme ist dabei im Prinzip nicht beschränkt. Tritt nun in einer solchen Befehlskombination ein Fehler auf, können mit tee an beliebiger Stelle Zwischenergebnisse in temporären Dateien gespeichert werden. Funktioniert alles wie gewünscht, so werden die tee’s entfernt.
Zwei Anmerkungen zu tee: Die unter Linux üblicherweise verwendete GNU-Version von tee kennt zwei wichtige Optionen: -a (-append) bewirkt, dass tee die Daten des Nebenausgangs ans Ende einer bereits bestehenden Datei schreibt. Ohne diese Option wird diese Datei bei jeder neuen Ausgabe überschrieben und enthält entsprechend nur den Inhalt des letzten Datenflusses (der letzten Datei). Mit -i (-ignore-interrupts) kann verhindert werden, dass sich tee beim Auftreten eines Interrupts [Strg-c] im Datenstrom beendet.
Das oben beschriebene Verfahren für die Zusammenlegung von Standardausgabe- und Standardfehlerkanal funktioniert auch mit Pipes:
$> grep muster textdatei* 2>&1 | less
So schön Pipes sind, sie haben ihre Grenzen. Die oben beschriebenen “einfachen Pipes” (oder “unbenannte Pipes”) können nur zwischen Befehlen einer Shell (genauer: zwischen Programmen identischer Eltern) eingesetzt werden. Was kann man dann machen, um dieses Verfahren auch für Prozesse zwischen mehreren Shells oder sogar zwischen verschiedenen Usern anzuwenden? Für diesen Fall unterstützt Linux das Konzept der “benannten Pipes” (named pipes). Ein spezieller Dateityp mit Namen “FIFO” (first in first out) steht für diese Aufgaben zur Verfügung. FIFOs müssen vor dem Einsatz zunächst angelegt werden. Das Programm mkfifo erzeugt eine derartige Datei:
$> mkfifo myfifo
Beim Anlegen der FIFO können noch bestimmte Zugriffsrechte (Permissions) als Argumente der Option -m (-mode) angegeben und damit eingestellt werden. Sehen Sie sich die so erzeugte Datei einmal mit ls an:
$> ls -l myfifo prw-r--r-- 1 work kg 0 Jul 7 12:31 myfifo
Nach dem Anlegen einer FIFO kann ein Programm in diese Datei schreiben, ein anderes kann die Daten lesen und weiterverarbeiten.
$> ls > myfifo
(Sender, erzeugt eine Ausgabe, die an die FIFO geleitet wird)
$> sort < myfifo
(Empfänger, sortiert die Eingabe aus der FIFO und stellt sie dar) FIFOs sind von einem speziellen Dateityp “p” (für Pipe). Nach dem Zugriff auf diese Datei sind bis zu 4096 Bytes in ihr enthalten:
$> head myfifo ls -l myfifo prw-r--r-- 1 work kg 4096 Jul 7 12:31 myfifo
Die Zugriffsrechte spielen beim Erzeugen von FIFOs eine wichtige Rolle. Solange diese Rechte nicht eingeschränkt werden, besteht die Gefahr, dass andere Programme unerwünscht Daten aus dem Datenstrom entnehmen, wie folgendes Experiment zeigt: Erzeugen Sie eine FIFO mit mkfifo /tmp/myfifo. In drei (oder mehr) Terminals lesen Sie diese FIFO aus cat /tmp/myfifo. Jetzt starten Sie in einem vierten Terminal einen Prozess, der Daten in die FIFO schreibt ls -R / > /tmp/myfifo. Vergleichen Sie die Ausgabe in den drei Terminals. Wiederholen Sie das Experiment, leiten Sie dabei die Ausgaben aber in Dateien um. Vergleichen Sie die Dateien auf Größe und Inhalt.
Verkettete Befehle
Pipes sind nur zwischen mehreren, miteinander in Beziehung stehenden Befehlen sinnvoll. Aufgrund der Struktur und dem Konzept der Befehle unter Linux ist das bei sehr vielen (fast allen) Aufgabenstellungen ähnlich. Die einzelnen Shell-Befehle stellen kleine, einfache Bearbeitungsmodule dar, die nach Bedarf kombiniert und ersetzt werden können. Gerade diese Eigenschaften machen die Leistungsfähigkeit und den Reiz bei der Arbeit mit der Shell aus. Es gibt eine Reihe von Befehlen, die ausschließlich für den Einsatz in durch Pipes verbundenen Befehlsketten konzipiert sind, die sogenannten “Filter”. Derartige Befehle verfügen über keine Option, mit der sie Daten direkt aus einer Datei lesen oder in eine Datei schreiben können. Die gesamte Kommunikation wird über die Standardkanäle abgewickelt. Typische Filter sind z.B. tr, uniq, colrm, … Betrachtet man die Anwendung von Befehlsketten genauer, so treten einige typische Fälle immer wieder auf:
- mehrere Befehle werden nacheinander ausgeführ
- mehrere Befehle werden parallel zueinander ausgeführ
- mehrere Befehle werden abhängig vom vorherigen Befehl ausgeführ
- identische Befehlsgruppen werden in unterschiedlichem Kontext ausgeführ
Normalerweise werden Befehle einzeln in einer Befehlszeile eingegeben und ausgeführt. Manchmal ist es aber übersichtlicher, mehrere, eng zusammenarbeitende Befehle in einer Befehlszeile einzugeben und diese dann gemeinsam ausführen zu lassen. Die Bash verwendet das Semikolon für die Abgrenzung der einzelnen Befehle (bzw. -szeilen). Ein Beispiel:
$> cd find . -print > find.tmp less find.tmp cd -
Der cd-Befehl bewirkt, ohne dass ein Argument angegeben wird, den Wechsel in das Homeverzeichnis des Anwenders. Dort erstellt find eine Liste aller Dateien, die in find.tmp gespeichert wird. less wird als Pager zur Anzeige (und zum Suchen in dieser Datei) verwendet. Abschließend wechselt cd mit dem Argument “–” zurück in das ursprüngliche Verzeichnis.
Die einfachste Lösung für das Zusammenfassen dieser Befehlszeilen wäre:
$> cd ; find . -print > find.tmp ; less find.tmp ; cd -
Die Leerzeichen vor und hinter einem Semikolon dienen nur der besseren Lesbarkeit, sie können auch entfallen. Diese einfachste Form der Befehlsverkettung hat einige Nachteile: Zunächst einmal ist der abschließende cd-Befehl gar nicht unbedingt notwendig, wenn nämlich die Ausführung dieser Befehle in einer Subshell (einer nur zu diesem Zweck implizit gestarteten Shell) erfolgt. Nach dem Ende der Bearbeitung befindet sich die aufrufende Shell immer noch im selben Verzeichnis wie vorher. Runde Klammern starten auf der Bash eine Subshell:
$> pwd /mydir (cd ; find . -print > find.tmp ; less find.tmp) pwd /mydir
Als nächstes stellt sich die Frage, was geschieht, wenn in der Bearbeitung der Befehlsfolge ein Fehler auftritt. Die Anzeige der durch find erzeugten Datei ist sinnlos, wenn diese beispielsweise aus Platzmangel auf dem Datenträger nicht vollständig erstellt werden konnte.
Die Bash kennt zwei spezielle Operatoren, mit denen Befehle nur in Abhängigkeit vom Ergebnis des vorher ausgeführten gestartet werden. Durch ein doppeltes Ampersand-Zeichen “&&” wird zunächst der links davon stehende Befehl ausgeführt und nur dann, wenn dieser fehlerfrei abgearbeitet werden konnte, der rechts davon stehende:
$> find . -print > find.tmp && less find.tmp
Die Bash wertet zu diesem Zweck den sogenannten “Return Code” (Rückgabewert) des ersten (links stehenden) Befehls aus. Nur wenn dieser gleich Null ist – nur das signalisiert eine fehlerfreie Befehlsausführung – wird der zweite Befehl gestartet.
Achtung: das doppelte Ampersand-Zeichen darf nicht mit dem einfachen verwechselt werden. Dies hat eine ganz andere Funktion: es bewirkt, dass der links davon angegebene Befehl im “Hintergrund” ausgeführt wird. (Mehr dazu in einer der nächsten Folgen dieser Serie.)
Übrigens gibt es auch eine einfache Möglichkeit, auf Fehler bei der Befehlsausführung zu reagieren. Durch ein doppeltes Pipe-Symbol (das auch wiederum nichts mehr mit Pipes zu tun hat), wird der zweite Befehl nur dann ausgeführt, wenn der erste einen von Null verschiedenen Rückgabewert lieferte:
$> ls /root/ || echo Oh no! ls: /root/: Keine Berechtigung Oh no!
Da der User (normalerweise) über keine Berechtigung zum Auslesen des Homeverzeichnisses von Root (/root/) verfügt, kann der ls-Befehl nicht erfolgreich beendet werden. Er erzeugt daher beim Ende einen Rückgabewert von “1”. Dieser veranlasst die Shell, aufgrund des “||”-Operators nun den zweiten Befehl auszuführen. (agr)
Ausblick: Funktionen und Scripts
Die bisher vorgestellten Befehlsfolgen sind noch recht einfacher Natur. Für viele (ca. 70%) aller Probleme reichen sie aber schon aus. In einer der nächsten Folgen dieser Serie werden die weitaus mächtigeren Funktionen und Scripte vorgestellt.

