
Der tägliche Umgang mit Dateien und Texten kann fernab von Datei-Managern oft einfacher und besser auf der Kommandozeile realisiert werden, sofern man die richtigen Utilities kennt.
Obwohl Programme wie Konqueror oder Nautilus sehr komplett und durchdacht sind, gibt es doch bestimmte Funktionen, die sich im täglichen Unix-Alltag als umständlich erweisen oder gänzlich fehlen. In vielen Fällen ist es wesentlich einfacher, sich die Syntax eines alteingesessenen und oft auch antiquiert anmutenden Unix-Utilities zu merken, als zum x-ten Mal denselben Dialog mit “Ja, ich bin wirklich sicher!” zu bestätigen.
Lesen und Erzeugen von Dateien
Eine der häufigsten Aktionen ist sicherlich das Lesen von Dateien. Das Kommando cat (engl. concatenate) dient zum Anzeigen und Zusammenfügen von Textdateien, dass heißt es erwartet mindestens ein Argument als Eingabe:
cat README.txt
Durch diesen Befehl bekommen Sie auf unspektakuläre Weise den Inhalt von README.txt zu Gesicht. Doch wie sieht das mit mehreren Dateien aus? Der Befehl echo leistet wichtige Dienste, um unkompliziert mehrere Dateien zu erstellen und diese dann mit cat zusammenzuführen.
echo "Unix Text-Utilities" > teil1.txt echo "sind wirklich hilfreich." > teil2.txt
Setzen Sie diese beiden Befehle auf der Text-Konsole ab, so erhalten Sie zwei neue Dateien mit den Namen teil1.txt und teil2.txt. Diese enthalten “Unix Text-Utilities” und “sind wirklich hilfreich.” Mit cat haben Sie einen Befehl zur Hand, um die beiden Teile zu einer einzelnen, neuen Datei zu verschmelzen:
cat teil1.txt teil2.txt > neu.txt
Dabei haben Sie sich einen typischen Unix-Mechanismus zu Nutze gemacht: die Umleitung durch >. Genau genommen bedeutet die einfache spitze Klammer, dass die Ausgabe von der Standardkonsole auf ein anderes Medium umgeleitet wird.
Bei Wiederholung des Befehls wird allerdings jedesmal neu.txt überschrieben. Es existiert ein zweiter Umleitungsoperator >>, der die Inhalte lediglich an ein bestehendes Ziel angehängt, ohne es vorher zu löschen. In der Tat müssten Sie sehr flinke Finger und eine schnelle Textverarbeitung haben, um damit genauso schnell Dateien zu erstellen und zusammenzufügen.
Pipes
Ein weiteres wichtiges Unix-Konzept sind die Pipes, also Leitungen, die Daten zwischen Prozessen transportieren. Auf der Textkonsole setzen Sie dafür einen senkrechten Strich [AltGr+<] ab. Dass dies ungemein nützlich ist, soll das folgende kurze Beispiel demonstrieren:
ls -al | less
Dieser Einzeiler veranlasst, dass die ausführliche Verzeichnisausgabe nicht einfach über den Bildschirm rast, sondern an den Text-Viewer less übergeben wird. Dadurch blättern Sie in langen Verzeichnissen bequem vorwärts und rückwärts, bis ein gesuchter Eintrag gefunden ist.
Nicht nur hilfreich für Autoren ist das Kommando wc (engl. word count). Wollen Sie zum Beispiel wissen, wieviele Wörter die Datei artikel.txt enthält, so würden Sie folgenden Befehl absetzen:
cat artikel.txt | wc -w
Das gleiche gilt, wenn Sie daran interessiert sind, aus einem Verzeichnis die größten Unterverzeichnisse zu selektieren. Dazu kombiniert man am besten die Kommandos du (engl. disk usage) und sort.
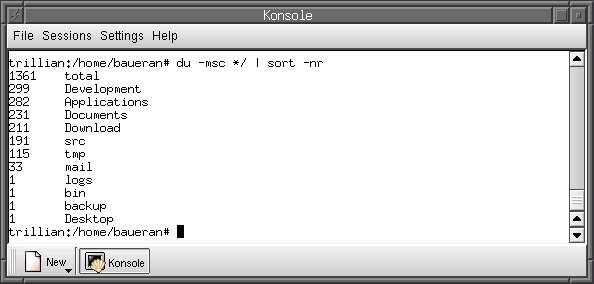
Abbildung 1: Das Home-Verzeichnis der Größe nach sortiert
Selbstverständlich lassen sich diese Beispiele beliebig fortführen, denn Befehle sind nicht nur auf einen einzigen Operator beschränkt. Denkbar wäre zum Beispiel auch:
history | grep cat | wc -l
Ausgegeben wird eine Zahl, die Ihnen anzeigt, wie oft Sie bereits den Befehl cat verwendet haben. Das Ergebnis setzt sich dabei wie folgt zusammen: history liefert alle zuletzt eingegebenen Befehle durch die Pipe an grep. Mit grep wird dieser Textstrom schließlich nach dem Wort “cat” gefiltert und die übrigen Zeilen mit wc gezählt.
Tabelle 1: Wichtige wc-Schalter
| -c | Anzahl Buchstaben |
| -l | Anzahl Zeilen |
| -w | Anzahl Worte |
Suchen mit Regulären Ausdrücken
Unentbehrlich im Umgang mit Texten und Dateien sind Reguläre Ausdrücke. Viele Kommandos und Befehle wären nicht einmal halb so nützlich, würden Unix-Systeme (und folglich auch Linux) keine Unterstützung für Reguläre Ausdrücke bieten. Im wesentlichen dienen sie dazu, Zeichenketten und Suchanfragen zu spezifizieren.
Leider ist der Umgang mit diesem Werkzeug nicht ganz trivial, so dass es dutzende Bücher zum Thema gibt, auf die man ruhig einmal den einen oder anderen Blick werfen sollte. In der Ausgabe 08/02 des LinuxUsers ist das Thema ebenfalls ausführlich behandelt worden. Aber auch im Web gibt es zahlreiche Hilfestellungen, so zum Beispiel auch unter [1] oder [2].
Wie ungemein praktisch Reguläre Ausdrücke sind, erkennt man an folgender Anwendung. Stellen Sie sich vor, Sie wollen aus Ihren alten Mailbox-Archiven die Adresse eines Hans Schmidt in Erfahrung bringen. Sie wissen, dass er Ihnen im Jahr 2001 eine Nachricht zukommen ließ, können sich aber nicht mehr an die entsprechende Mailbox erinnern. Kein Problem, denn mit grep können Sie in allen Boxen blitzschnell Herrn Schmidt ausfindig machen. Wechseln Sie in Ihr Archiv von 2001 und geben Sie den folgenden Befehl ein:
grep Hans.Schmidt @L: *
Der Stern veranlasst grep, in allen Dateien des aktuellen Verzeichnisses nach dem Ausdruck Hans.Schmidt zu suchen, wobei der Punkt zwischen dem Namen ein beliebiges Zeichen repräsentiert. Es könnte ja auch sein, dass nicht Hans Schmidt, sondern tatsächlich Hans.Schmidt oder Hans_Schmidt gefunden wird.
Genauso gut könnten Sie natürlich nach ^From:.@L: *Hans.Schmidt suchen, wenn Sie sicher sind, dass dies so im Kopf einer Nachricht steht. Zudem enthält der Ausdruck zwei weitere Features regulärer Ausdrücke: Das Caret-Zeichen oder Dach zu Anfang markiert den Zeilenbeginn und die Kombination aus Punkt und Stern markiert eine beliebige Zeichenkette zwischen From und Hans.Schmidt.
Sie sehen, die Möglichkeiten sind noch lange nicht erschöpft und es lohnt sich wirklich, die entsprechenden Anleitungen und Beispiele zu studieren.
Tabelle 2: Wichtige grep-Schalter
| -E | Verwendung erweiterter Regulärer Ausdrücke, an Stelle der “einfachen” Variante (für Profis) |
| -i | Groß- und Kleinschreibung ignorieren |
| -l | Anzeige von Dateinamen, an Stelle von Textpassagen |
Richtig mächtig wird grep allerdings erst in Verbindung mit dem Kommando find. Dazu spinnen wir unser Beispiel weiter und vermuten, dass das Mail-Archiv aus dem Jahr 2001 in verschiedene Unterverzeichnisse aufgeteilt ist, so dass der ursprüngliche Befehl versagt hätte. Mit find lässt sich der Inhalt von Unterverzeichnissen durchsuchen.
find . -exec grep "Hans.Schmidt" '{}' \; -print
Der einleitende Punkt veranlasst find, im aktuellen Verzeichnis mit der Suche zu beginnen und dann auf jede Datei die exec-Direktive anzuwenden, also grep. Mit dem Klammersymbol “{}” wird jede gefundene Datei als Argument für grep eingefügt und “\;” beendet schließlich die Anweisung.
Sind Sie dagegen sicher, dass sich Hans Schmidt bei Ihnen über eine KDE-Mailing-Liste gemeldet hat, so können Sie die Suche zusätzlich verfeinern:
find . -name "KDE@L: *" -exec grep "Hans.Schmidt" '{}' \; -print > ergebnisse.txt
Die abschließende Umleitung ist sinnvoll, wenn die Suche sehr viele Treffer aufweist. Diese Ergebnisliste ließe sich erneut durch Text-Utilities filtern.
Anzumerken ist außerdem, dass die vorgestellten Befehle ohne die tiefere Kenntnis von regulären Ausdrücken zu verwenden sind. Selbst die triviale Zeichenreihe Hans Schmidt legt bereits einen grep-Ausdruck fest. Und selbstverständlich funktioniert find ohne eine exec-Anweisung. Die Man-Pages der Befehle erklären das im Detail, teilweise sogar an Hand von Beispielen.
Tabelle 3: Nützliche Reguläre Ausdrücke
| [A-Za-z]+ | Eine Reihe von Groß- und Kleinbuchstaben, zum Beispiel “Mustertext” |
| Wart(en|end|ung) | Trifft zu auf “Warten”, “Wartend” und “Wartung” |
| (ftp|http|https|mailto|news)://[^ >)]+ | Internet URLs, zum Beispiel “http://www.linux-user.de/” |
| [A-Za-z0-9._-]+@[[A-Za-z0-9.-]+ | e-Mail Adressen, zum Beispiel “info@linux-user.de” |
Der Abfalleimer
Wenn man über Text-Utilities spricht, sollte das Shell-Pendant zum Abfalleimer-Icon nicht unerwähnt bleiben: /dev/null. Anstatt Inhalte mit der Maus über einen Papierkorb zu ziehen, leiten Sie alternativ ganze Textströme in das Verzeichnis /dev/null um. Das ist zu Zeiten ungemein nützlich, wenn Sie zum Beispiel unnötige Programmausgaben umgehen wollen. Wie das funktioniert, sehen Sie hier:
ls > /dev/null
Die Ausgabe von ls wandert unwiderruflich ins Leere. Und auch dieser Mechanismus lässt sich prima mit den bereits vorgestellten Kommandos kombinieren.
Stellen Sie sich vor, Sie wollen wissen, welche Konfigurationsdateien im Verzeichnis /etc die Environment-Variable PATH setzen. Der folgende einfache Befehl gibt darüber Auskunft:
grep -l PATH /etc/@L: * 2>/dev/null
Durch grep -l teilen wir dem Befehl mit, nur die Dateinamen zurückzuliefern, jedoch nicht die gefundenen Textstellen. Das abschließende 2>/dev/null filtert die auftretenden Fehlerausgaben heraus, da grep nur auf Dateien anwendbar ist, nicht aber auf Verzeichnisse. Würden Sie die 2 durch eine 1 ersetzen, so bekämen Sie ausschließlich die Fehlermeldungen zu Gesicht. Dahinter verbirgt sich ein wichtiges Unix-Feature, nämlich die Unterscheidung zwischen normaler Ausgabe und Fehlermeldungen oder Warnungen.
Zum Schluss sei noch angemerkt, dass die Text-Utilities mit den hier vorgestellten Methoden noch sehr lange nicht am Ende sind. Schier endlos sind die Möglichkeiten und es dauert sicherlich eine ganze Weile, bis man sich seine Lieblings-Utilities sinnvoll herausgepickt und zusammengestellt hat. Noch größere Komplexität erhält die Thematik, wenn man die gewonnenen Fähigkeiten in selbstgeschriebenen Skripten unterbringt, doch das ist ein gänzlich eigenes Kapitel und zudem abhängig von der Shell, die auf Ihrem System installiert ist.




