
RAID verspricht rasante Plattenzugriffe und optimale Datensicherheit. Mit Linux ist das auch auf dem Desktop kein Problem.
In den letzten 15 Jahren hat sich die Festplattenkapazität fast vertausendfacht. Waren es zu jener Zeit noch 300 bis 500 MByte, bietet eine handelsübliche Scheibe nun schon 300 bis 500 GByte Platz – und das zu vergleichbaren Kosten. Zwei oder mehr Festplatten in einem Standard-PC stellen keine Seltenheit mehr dar. Damit kann sich der Heimanwender inzwischen leisten, was früher nur für die Server von Unternehmen bezahlbar war: Datensicherheit im laufenden Betrieb oder doppelte Performance für schnellen Plattenzugriff. Die Technik, die das möglich macht, heißt RAID.
RAID – Eine Einführung
Das Konzept für RAID [1] wurde vor knapp 20 Jahren von den drei Berkley-Doktoranden D. Patterson, G. Gibson und R. Katz entwickelt. RAID war die Lösung einer kniffelige Frage: Benötigte man damals große Datenkapazitäten, hatte man die Wahl zwischen einer einzelnen, sehr groß dimensionierten und relativ ausfallsicheren Festplatte und vielen kleinen, relativ unzuverlässigen Platten. Eine große Einzelplatte war exorbitant teuer, die kleinen Neuentwicklungen dagegen relativ preiswert.
Beim Ersetzen einer großen Festplatte durch mehrere kleine fiel allerdings ein unangemessener hoher Verwaltungsaufwand an. Die drei Doktoranden traten diesem Problem mit einem Konzept entgegen, bei dem sich der Verbund von vielen Festplatten als eine Einheit ansprechen ließ. Gleichzeitig schlugen sie Verfahren vor, die bei einem Ausfall einer einzelnen Platte des Verbundes das Risiko des Datenverlustes deutlich reduzierten. Das Papier der Drei trug den Titel “A Case for Redundant Array of Inexpensive Disks (RAID)”, zu deutsch etwa: “Argumente für einen redundant speichernden Verbund preiswerter Festplatten”. Als später die kostspieligen großen Festplatten bedeutungslos wurden, ersetzte man das “Inexpensive” durch “Independent” (unabhängig).
Im einfachsten Fall kann man eine bestimmte Anzahl von Festplatten zu einer Einheit zusammenfassen und sie der Anwendungsschicht als eine einzige logische Festplatte präsentieren. Damit erhält man, was Techniker im Jargon gerne als JBOD (“Just a Bundle of Disks”) umschreiben. RAID leistet allerdings weit mehr: Als Verwaltungsschicht zwischen Dateisystem und Hardware geschaltet, ermöglicht es, die physikalischen Eigenschaften eines Plattenverbundes geschickt auszunutzten. Dabei erlauben verschiedene Varianten, das Ergebnis in Richtung höherer Performance oder geringerem Ausfallrisiko zu optimieren.
Die verschiedenen Techniken des RAID-Konzepts bezeichnet man als RAID-Level. Das spiegelt jedoch keineswegs eine Art Hierarchie wider, bei den Levels handelt es sich um voneinander unabhängige Konzepte. Es gibt im wesentlichen sieben RAID-Level, die man als RAID 0 bis RAID 7 durchnummeriert. Der Kasten “RAID-Level im Überblick” stellt die einzelnen Level näher vor.
RAID-Level im Überblick
Neben den bekanntesten RAID-Leveln 0 und 1 gibt es eine Vielzahl weiterer Konzepte. Die Originalarbeit von Patterson, Gibson und Katz umfasste die Level 1 bis 5. Später kamen 0 und 6, sowie verschiedene proprietäre Lösungen hinzu. Die RAID-Level 2 bis 4 und 6 sowie 7 sind weniger verbreitet bzw. nahezu bedeutungslos geworden. Aus der Kombination verschiedener Konzepte entstanden die Level 0+1, 10, 30, 15, 50, 51, 55 und RAID-Z. Im folgenden finden Sie einen Überblick zur Funktionsweise der grundlegenden RAID-Level.
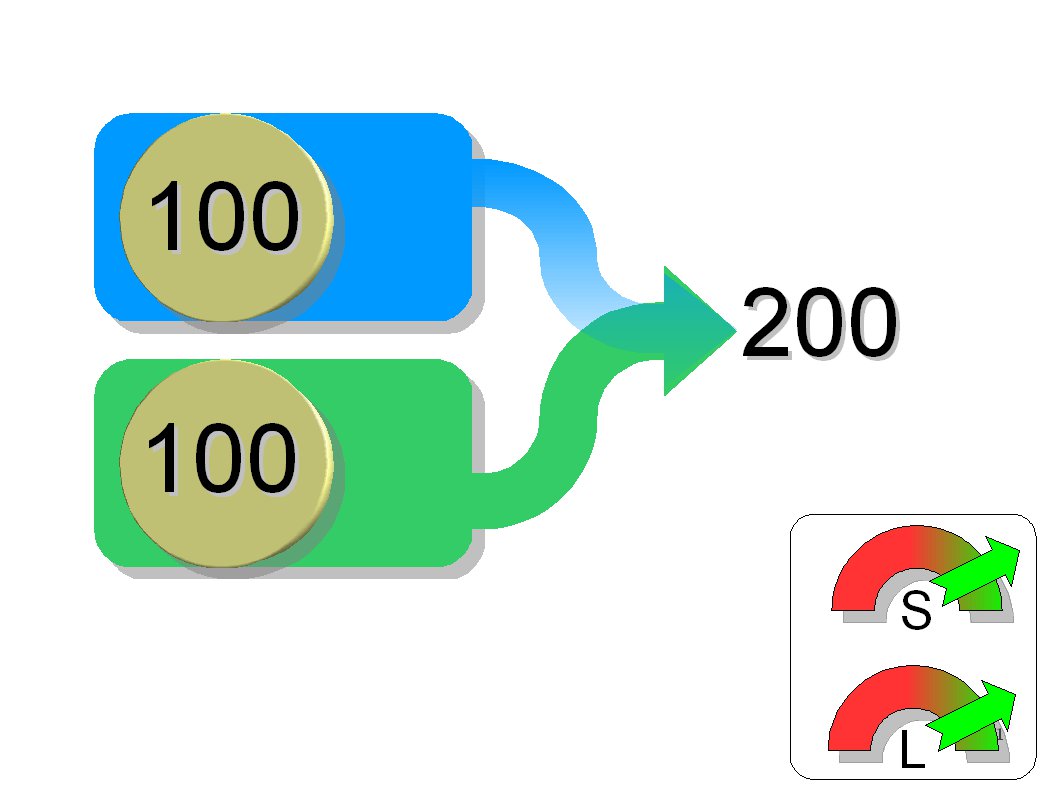
RAID 0: Beschleunigung durch Parallelbetrieb
RAID 0 schließt die Platten zusammen und teilt die Arbeit unter den Platten parallel auf. Das beschleunigt die Zugriffe deutlich. Die Gesamtkapazität des Arrays entspricht der Summe der Kapazitäten beider Platten. Auf Grund fehlender Redundanz besteht jedoch ein relativ hohes Ausfallrisiko.
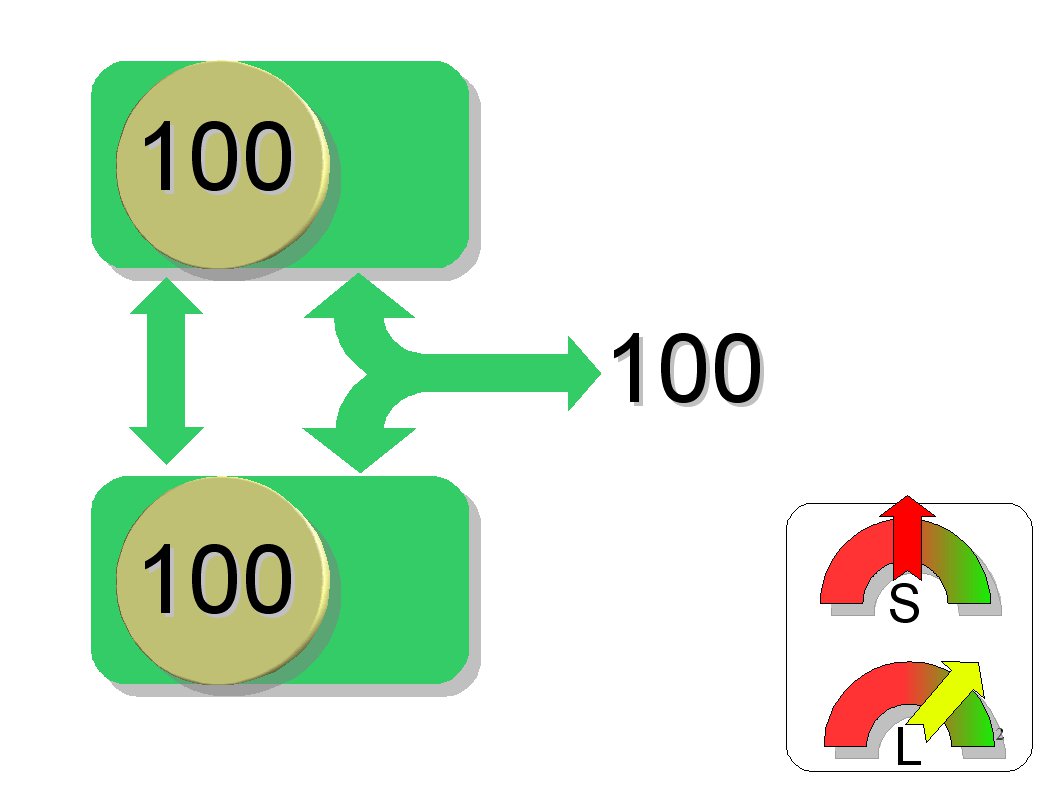
RAID 1: Sicherheit durch Spiegelung
RAID 1 beschreibt alle Festplatten des Verbundes parallel mit identischen Daten. Die Gesamtkapazität des Verbundes entspricht der einer einzigen Platte. Die Lesezugriffe erfolgen in der Regel schneller, die Schreibzugriffe in etwa gleich schnell wie auf einer einzelnen Platte.
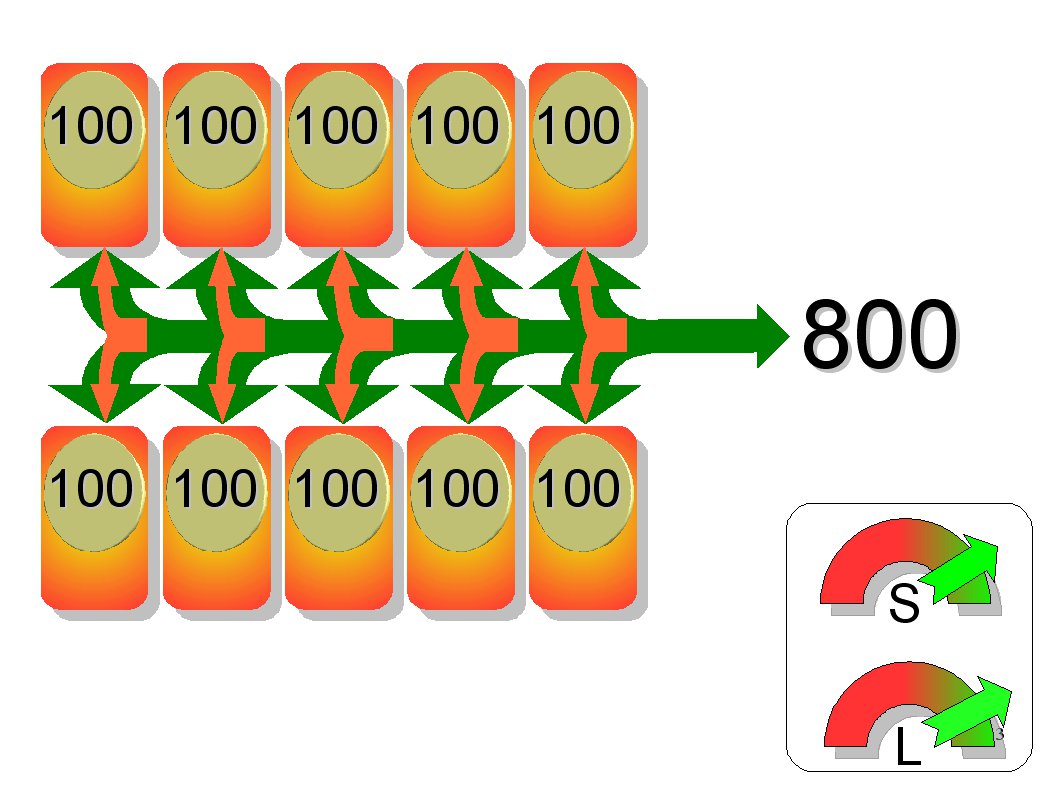
RAID 2: Plattenbausiedlung
RAID 2 wurde früher auf Großrechnern implementiert und ist heute nahezu bedeutungslos. Die Mindestgröße eines RAID-2-Verbunds liegt bei 10 Festplatten. Durch die elegante Art der Fehlerprüfung lassen sich neben einem Totalausfall einer Platte auch Schreibfehler entdecken. Bei 10 Platten liegt das Verhältnis der Zugriffszeiten von Schreiben zu Lesen bei 1 zu 8 gegenüber einer Einzelplatte.
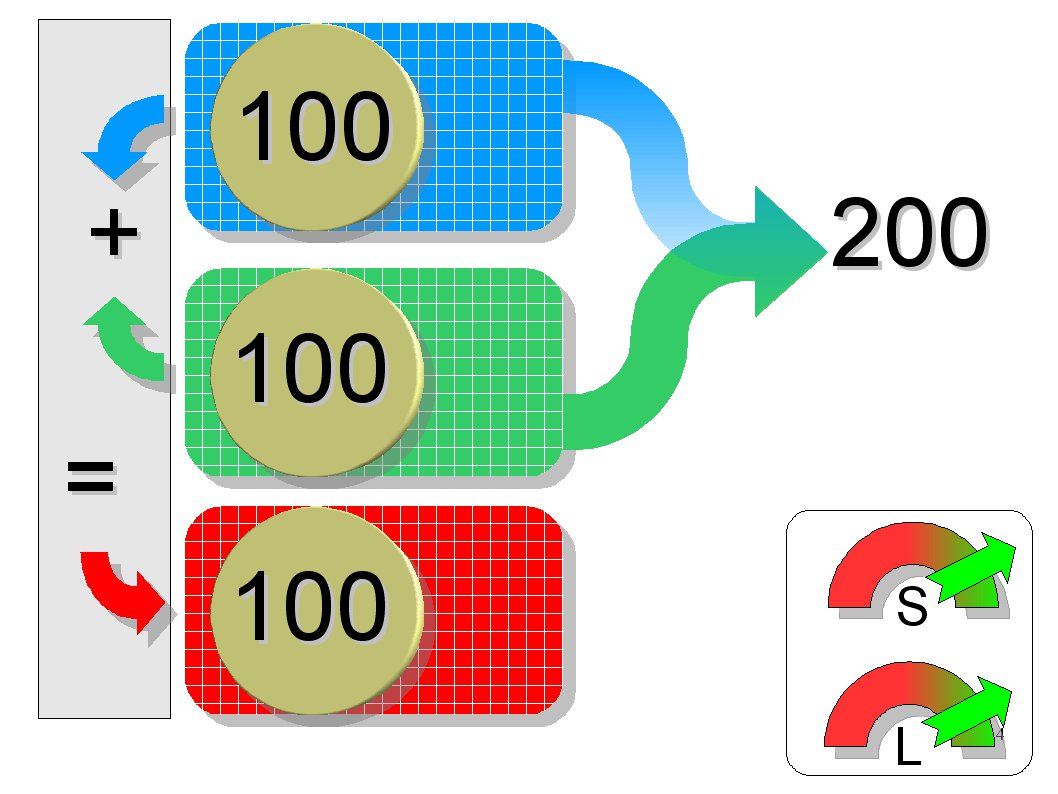
RAID 3: Striping mit Kontrolle
Indem man die Daten der Festplatten bitweise miteinander addiert und das Ergebnis speichert, kann man die Daten einer ausgefallenen Festplatte aus den noch vorhandenen Daten und den Additionsergebnissen rekonstruieren. Das Additionsergebnis nennt man Parität. RAID 3 lagert die Paritätsdaten des Verbundes auf einer eigenen Festplatte. Diese Paritätsfestplatte wird ungleich mehr beansprucht als die Datenplatten, statistisch fällt sie daher zuerst aus.
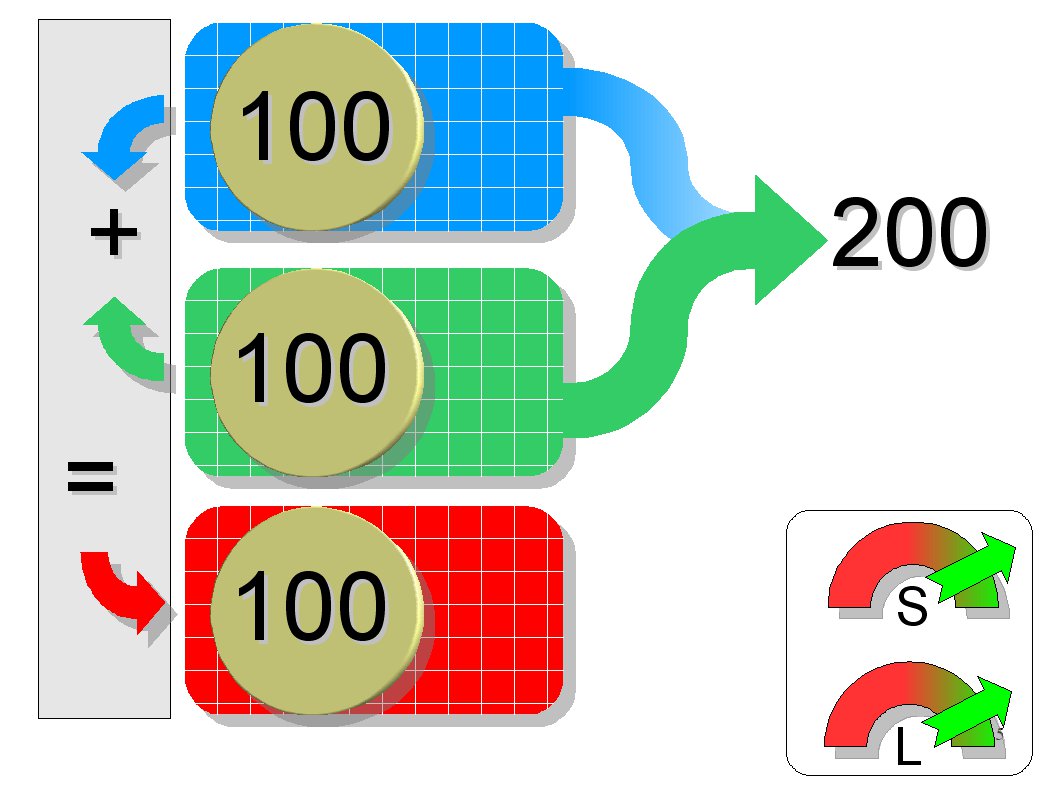
RAID 4: RAID 3 für die Kleinen
RAID-4 stellt eine geringfügige Modifikation von RAID 3 dar: Während RAID 3 mit Byte-weisem Striping operiert, verarbeitet RAID 4 jeweils einen ganzer Nutzdatenblock. Damit kann RAID 4 wesentlich effektiver mit kleinen Dateien umgehen, während RAID 3 erst bei großen zusammenhängenden Dateien Vorteile bringt. RAID 4 verwendet wie RAID 3 eine eigene Festplatte für die Paritätsinformationen.
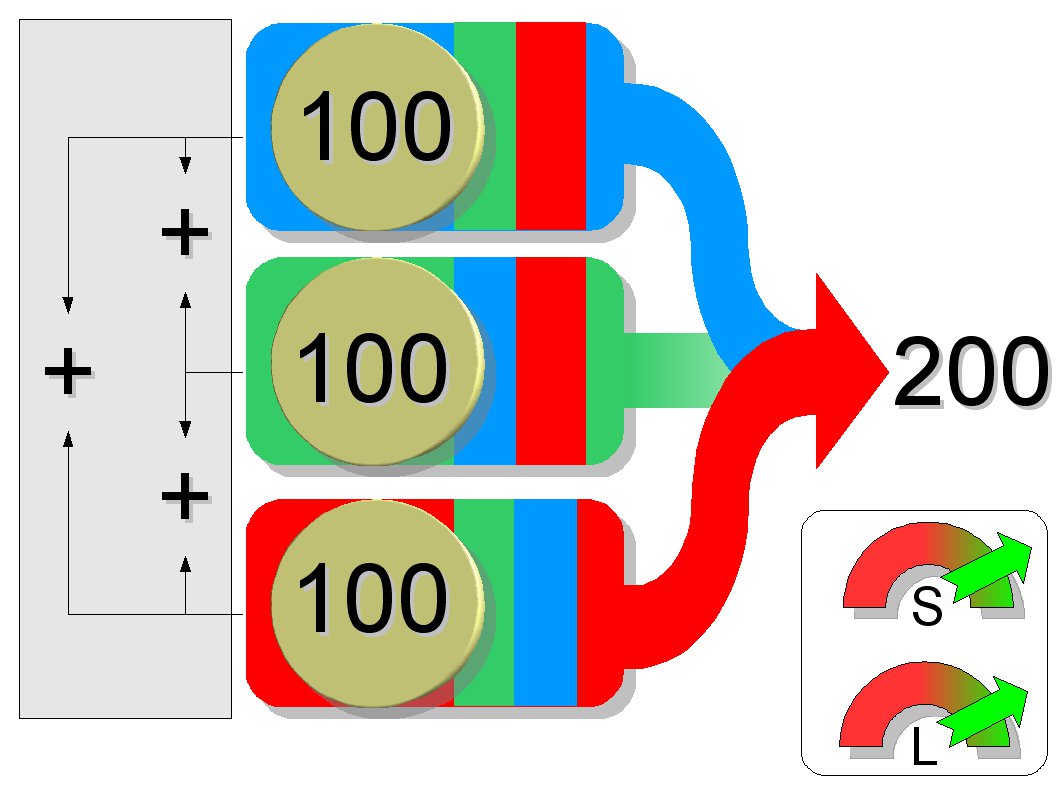
RAID 5: Sichere Lese-Performance
RAID 5 bietet die preiswerteste Variante der redundanten Datenhaltung: Bei mindestens drei Platten im Verbund bietet es 66 Prozent der Gesamtkapazität für Nutzdaten – im Gegensatz zu nur 50 Prozent bei RAID 1. Mit steigender Plattenanzahl verbessert sich dieses Verhältnis noch. RAID 5 verteilt Daten und Paritätsinformationen gleichmäßig auf alle beteiligten Platten, sodass alle Disks in etwa gleich beansprucht werden. Ein Wiederaufbau des RAIDs nach einem Defekt einer Platte ist deutlich langsamer als bei RAID 1.
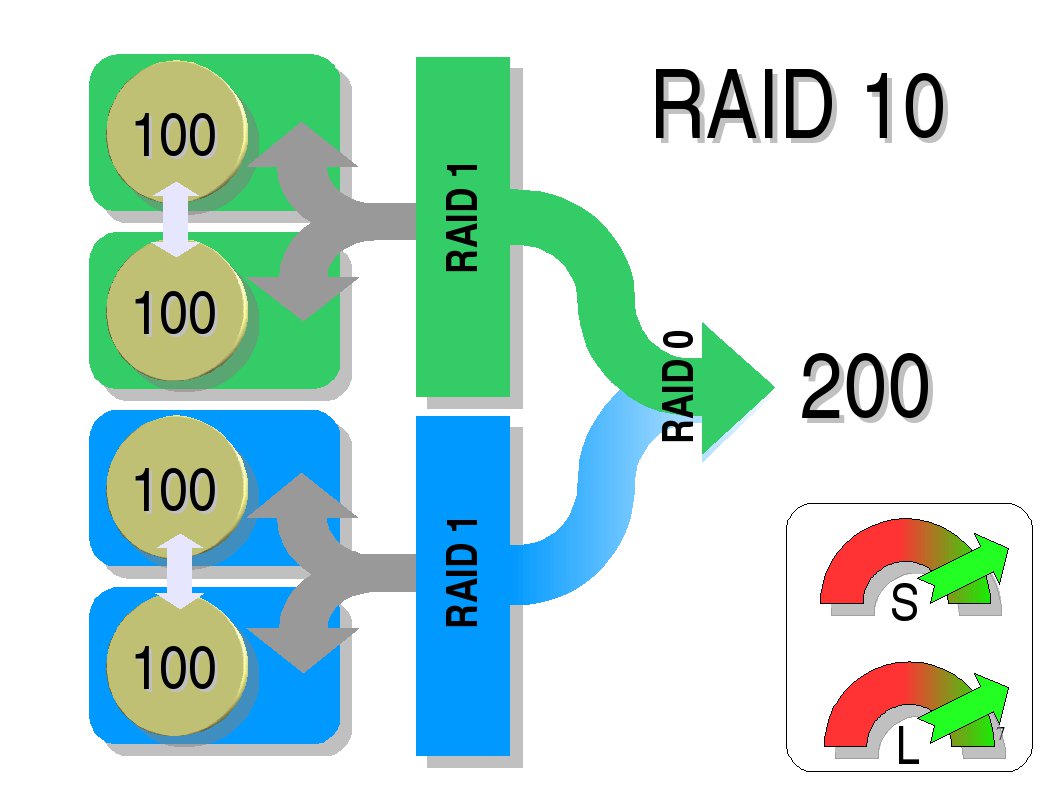
RAID Kombinationen
Je nach Anwendungsfall lassen sich die RAID-Basislevel beinahe beliebig kombinieren. RAID 10 beispielsweise erstellt ein RAID 0 über zwei RAID-1-Verbünde. RAID 1 sorgt dabei durch Redundanz für Datensicherheit durch Redundanz, RAID 0 für Performance. Stehen mindestens sechs Festplatten zur Verfügung, ist eine Kombination von RAID 5 und 0 (RAID 50) noch wirtschaftlicher.
Für den privaten Einsatz sind vor allem die RAID-Level 0 und 1 von Bedeutung. Level 0 bezeichnet man auch als Striping, es steht für maximale Performance. Level 1 deckt den Bedarf nach höherer Ausfallsicherheit und wird als Mirroring bezeichnet. Für Anwender, die sich nicht zwischen Performance und Sicherheit entscheiden können, gibt es noch ein spezielles RAID-Level für den Heimbedarf: RAID 1.5. Es stellt allerdings einen Kompromiss dar: Um die Eigenschaften von Level 0 und Level 1 zu verknüpfen, benötigt man eigentlich mindestens vier Festplatten. RAID 1.5 kombiniert die Level 0 und 1 auf nur zwei Festplatten und bietet der Anwendungsschicht die jeweiligen RAID-Disks separat an. Abbildung 1 stellt die drei Level schematisch dar.
Performance mit Striping
Beim Striping (RAID 0) werden die Festplatten quasi hintereinander aufgereiht und jeweils blockweise (in “Streifen”) abwechselnd angesprochen. Gilt es Daten zu schreiben, dann verteilt der RAID-Controller die Arbeit auf die beteiligten Platten. Da die Schreib- und Lesezugriffe parallel auf allen Platten erfolgen, verkürzen sich die Zugriffszeiten erheblich.
Technisch gesehen, legt der Controller die Daten lediglich beim jeweiligen Festplatten-Cache ab geht sofort zur nächsten Platte über. Ist die erste Platte wieder an der Reihe, hatte sie inzwischen genügend Zeit zur Ausführung der Aufträge und steht mit den Rückgabewerten wieder zur Verfügung. Bei der Verwendung von zwei Festplatten halbiert sich theoretisch die Zugriffszeit.
Teil 1 der Abbildung 1 demonstriert diesen Vorgang anhand der Aufteilung der Zeichen des Satzes “Und sie dreht sich doch!” auf die beiden Festplatten. Auf jeder Platte befindet sich nur ein Teil der Daten. Fällt eine der Disks aus, lassen sich die Daten allerdings nicht wieder herstellen.
RAID 0 nimmt die Aufteilung der Daten auf die einzelnen Platten nicht zeichenweise, sondern in Datenblöcken mit einer gewissen Striping-Granularität vorgenommen. Die Wahrscheinlichkeit eines Ausfalls erhöht sich mit der steigenden Anzahl beteiligter Festplatten. Striping empfiehlt sich daher für Systeme, bei denen es mehr auf Geschwindigkeit als auf Ausfallsicherheit ankommt.
Sicheres Spiegeln
Mirroring (RAID 1) verhält sich genau entgegengesetzt zu Striping. Es schaltet alle Festplatten in Serie und schreibt die Daten auf jede Festplatte im Verbund, spiegelt sie also. Das Vorhalten identischer Datenkopien auf jeder Harddisk führt allerdings dazu, dass die Gesamtkapazität des Verbundes nicht größer ist als die einer einzelnen Festplatte. Verwenden Sie also zwei Festplatten von je 200 GByte, so können Sie statt der Gesamtkapazität von 400 GByte also nur 200 GB nutzen. Während sich an Zugriffszeit für das Schreiben gegenüber einer einzelnen Platte nichts ändert, erfolgen Lesezugriffe deutlich schneller, da der Controller sie auf beiden Platten parallel vornehmen kann.
Der große Vorteil von RAID 1: Beim Ausfall einer Festplatte stehen dennoch alle Daten nach wie vor zum Zugriff bereit. Dies gilt aber nur für physikalische Defekte: Jeder logische Fehler – wie versehentliches Löschen, Ändern oder Überschreiben der Dateien auf Dateisystemebene – nimmt das Mirroring auf allen Festplatten gleichzeitig vor. Es bietet also keinen Schutz gegen Fehler der Anwendung oder des Benutzers.
Kombi: RAID 1.5
Um die Vorzüge der RAID-Level 0 und 1 gleichzeitig zu genießen, müsste man den PC mit vier Festplatten bestücken, um das Kombi-Verfahren RAID 10 (siehe Kasten “RAID-Level im Überblick”) einsetzen zu können – für die meisten Anwender keine gangbare Alternative. Das haben einige Hersteller erkannt und bieten einen eleganten Kompromiss, der mit zwei Harddisks auskommt.
RAID 1.5 – so die Bezeichnung des Verfahrens – teilt jede der zwei Festplatten in jeweils zwei Bereiche auf. Einen davon führt der Controller mit dem gleich großen Gegenstück der Partnerplatte zu einem RAID 1 zusammen, den anderen koppelt er mit dem entsprechenden Bereich der anderen Platte zu einem RAID 0. Der rechte Teil von Abbildung 1 stellt dieses Konzept durch die verschiedenfarbigen Bereiche dar.
Die ersten Motherboards für diese RAID-Variante boten die Hersteller DFI und EPox an. Allerdings handelte es sich dabei zunächst um Etikettenschwindel, tatsächlich betrieben die Boards schlicht ein RAID 1 betrieben. Einen Performance-Gewinn bezog man ausschließlich aus der höheren Lesegeschwindigkeit. Schließlich brachte jedoch Intel mit dem I/O-Controller ICH6R für die neuen Serial-ATA-Festplatten das “Intel Matrix RAID” heraus, das tatsächlich RAID 1.5 realisiert.
Software vs. Hardware
Die verschiedenen RAID-Konzepte wurden zunächst in Software programmiert. Da die Rechenanforderungen einer reinen Software-Lösung die CPUs anfangs überforderten, kam es bald zur Entwicklung von RAID-Controller-Steckkarten, die entsprechend leistungsfähige Hardware zur Verfügung stellen konnten. Diese Art der Implementierung bezeichnet man als Hardware-RAID bezeichnet.
Mit zunehmend leistungsfähigen CPUs konnte man RAID auch wieder in Form von Software realisieren. Dieses preiswerte Software-RAID wurde vor allem mit Hilfe von Linux im privaten Bereich betrieben. Software-RAIDs arbeiten in der Regel allerdings nicht so performant wie ihre Hardware-unterstützten Pendants. Die Belastung der CPU ist im laufenden Betrieb deutlich zu spüren. Die eigentlichen Vorteile, wie zum Beispiel die Parallelisierung von Zugriffen, lassen sich mit Software-Treibern nicht voll ausspielen.
Größere Verbreitung bei den Heimanwendern erfuhr RAID, als es in Form entsprechender Controller-Chips schließlich direkt auf den Motherboards auftauchte. Heute bringt die Mehrzahl moderner Boards, insbesondere solche mit Anschlüssen für die schnellen S-ATA-Festplatten, RAID-Fähigkeiten mit. Die meisten auf die Hauptplatine integrieren Chips erledigen jedoch nur einen Teil der Verwaltung und überlassen den Löwenanteil der Arbeit dem Treiber. Daher gestaltet sich die Nutzung nicht immer ganz einfach.
RAID kennen lernen
Linux bietet in Software implementiertes RAID schon seit langer Zeit an (siehe [2]). Inzwischen bieten die Rechner genug Leistung, um die zusätzliche Verwaltung von Festplatten im Verbund fast transparent abzuwickeln. Tatsächlich gestaltet sich der Leistungsunterschied den erwähnten Motherboard-basierten Lösungen marginal, da auch diese auf tatkräftige Unterstützung durch Software – den Treiber – angewiesen sind.
Um erste Erfahrungen mit RAID zu machen, genügt zu Studienzwecken die Installation eines Software-RAID. Zu entsprechenden Experimenten benötigen Sie lediglich Root-Rechte auf dem fraglichen Rechner, mindestens zwei freie Partitionen und die Mdadm-Tools ([3]). Die verwendeten Partitionen dürfen keine Daten enthalten, die man noch benötigt, da diese bei der Erstellung der Dateisysteme gelöscht werden.
Für die ersten Versuche mit RAID können Sie auch einen USB-Stick verwenden, den Sie mit einem geeigneten Tool – etwa Gparted, Qtparted oder Cfdisk – in zwei Partitionen aufteilt. Das Experiment umfasst folgende Schritte:
- Erstellen von mindestens zwei gleich großen Partitionen
- Kombinieren der Partitionen zu einem RAID mittels
mdadm - Formatieren des RAID-Devices mit einem Dateisystem
- Nutzen der neue RAID-Partition
- Überwachen des RAIDs mit
mdadm
Im folgenden Beispiel heißt das USB-Device /dev/sdc und die beiden Partitionen /dev/sdc1 und /dev/sdc2. Um beiden zu einem RAID 1 zusammenzuschalten, rufen Sie mdadm auf:
mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdc1 /dev/sdc2
Die Option --create erzeugt das RAID, --verbose sorgt für ausführliche Informationen über den Fortschritt, bei /dev/md0 handelt es sich um das zu erstellende RAID-Device und mit --level=1 stellen Sie das redundante RAID-Level 1 ein. Schließlich übergeben Sie noch die Anzahl der RAID-Partitionen und deren Namen.
Um den neu erstellten RAID-Verbund zu nutzen, müssen Sie ihn noch formatieren (im Beispiel mit ReiserFS) und in das Dateisystem mounten:
mkreiserfs /dev/md0 mkdir /media/RAID mount /dev/md0 /media/RAID
Nun können Sie das Verzeichnis /media/RAID wie ein normales Laufwerk nutzen. Im Hintergrund aber werden die Daten auf zwei Partitionen redundant abgelegt. Mit dem Aufruf mdadm --detail /dev/md0 erhalten Sie bei Bedarf Informationen über den Zustand des RAID-Verbunds. Das Ergebnis des Aufrufs zeigt Abbildung 2.
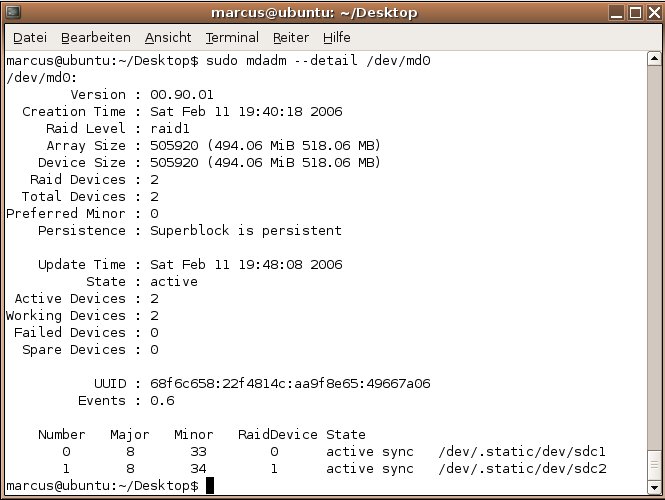
Abbildung 2: Mdadm präsentiert bei Bedarf Informationen über des Status des RAID-Devices.
Doch wie sieht die Redundanz auf den Partitionen des gespiegelten Verbunds tatsächlich aus? Um das zu untersuchen, hängen Sie das RAID mit umount /media/RAID wieder aus dem Dateisystem aus und beenden den RAID-Verbund mit mdadm -S /dev/md0. Anschließend erstellen Sie die beiden Verzeichnisse /media/sd1 und /media/sd2 und mounten dort die Partitionen /dev/sdc1 und /dev/sdc2. Abbildung 3 zeigt, wie auf beiden Partitionen des ehemaligen RAID 0-Verbundes die gleichen Daten abgelegt worden sind.
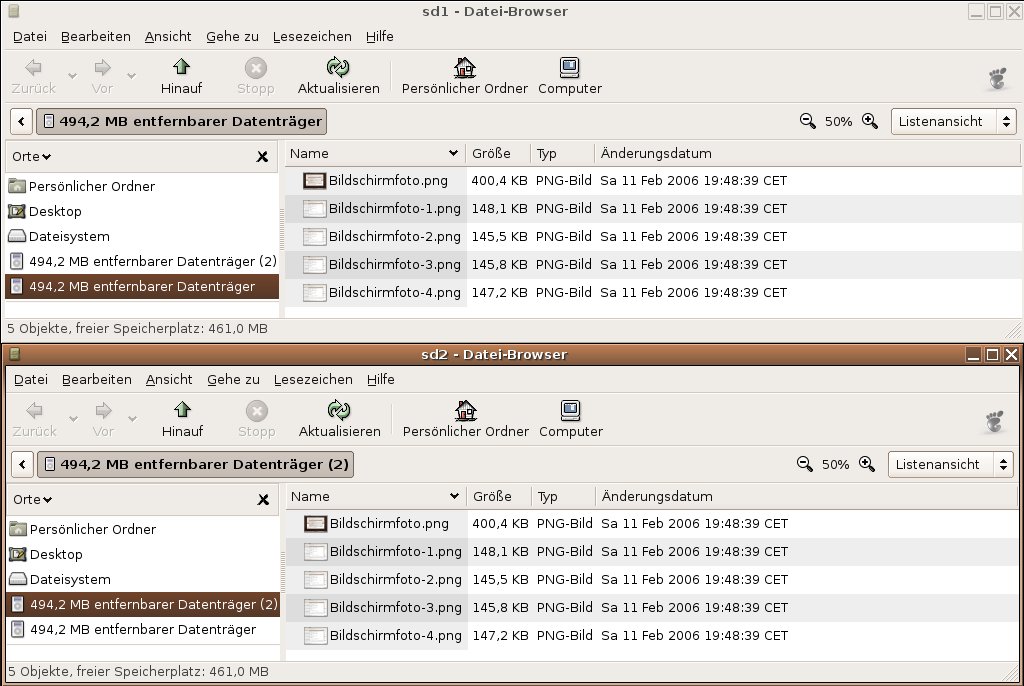
Abbildung 3: Gleicher Inhalt: Die Daten auf den beiden RAID-1-Partitionen fallen identisch aus.
Fazit
RAID bietet auch für den heimischen PC viele Vorteile. Gerade unter Linux lassen sich die resultierende Datensicherheit und die rasanten Plattenzugriffe besonders leicht realisieren, die Einrichtung eines Software-RAID ist mit wenigen Handgriffen erledigt. Für ein Software-RAID müssen Sie auch nicht komplette Festplatten verbauen, es genügen einige Partitionen. Mit Hilfe der Mdadm-Tools können Sie dann alle hier vorgestellten RAID-Level realisieren. Das gilt fürfür Studienzwecke ebenso wie für den Dauereinsatz auf dem heimischen PC.
Infos
[1] RAID bei Wikipedia: http://de.wikipedia.org/wiki/RAID
[2] Bernhard Kuhn: “Manche mögen’s weich”, Linux-Magazin 08/2000, http://www.linux-magazin.de/Artikel/ausgabe/2000/08/SoftRAID/SoftRAID.html
[3] Mdadm: http://cgi.cse.unsw.edu.au/~neilb/mdadm




