

Enthält die Festplatte defekte Speicherblöcke, hilft das beste Backup nichts: Es speichert dann nur fehlerhafte Dateien. Abhilfe schafft regelmäßige Kontrolle.
Wem es einmal erlebt hat, der erinnert sich mit Schrecken daran: Man schaltet nur eben mal den Rechner an – und bekommt anstelle des Anmeldebildschirms nur einen Haufen Fehlermeldungen zu sehen. Die Ursache ist nicht selten ein Fehler auf der Festplatte. Im schlimmsten Fall sind dann wertvolle Daten weg oder zumindest nicht mehr zu erreichen. Zwar stellen Backups ein durchaus probates Mittel der Datensicherung dar, garantieren jedoch nicht automatisch für die Integrität des Inhalts: Schleicht sich ein ein Fehler auf der Festplatte ein, sichert das Backup ihn schlicht mit und macht die betreffenden Daten damit unbrauchbar.
Als Auslöser solcher Festplattenfehler kommen verschiedene Ursachen in Frage. Zum einen spielt der natürliche Alterungsprozess eine Rolle, zum anderen genügt schon ein Rempler, um die Platte – für den Anwender zunächst unbemerkt – zu beschädigen. Eine weitere Fehlerquelle stellt feiner Abrieb oder Staub dar, der die Magnetschicht beschädigt. Diese Partikel verursachen nicht selten einen Headcrash, bei dem der Lesekopf auf die Platter aufschlägt, dort weitere Partikel freisetzt und damit den Exitus der Harddisk wie in einem Schneeballsystem beschleunigt. Das hat zur Folge, dass der Lesekopf die betreffenden Bereiche nicht mehr einwandfrei ausliest oder beschreibt. Ein defektes Bit heißt Badspot, der dazugehörigen Block nennt man “bad block”.
Ein Anzeichen dafür Fehler auf der Festplatte ist oft die nachlassende Lesegeschwindigkeit: Die Elektronik des Datenträgers versucht mehrfach, einen defekten Block zu lesen, oder verliert gar die Information über die Kopfposition, sodass sie immer wieder neu ansetzen muss. Zwar korrigieren die meisten modernen Festplatten Fehler bis zu einem bestimmten Grad; eine Garantie dafür gibt es aber nicht.
Ein smarter Test
Die Smartmontools [1] geben eine Übersicht über den Zustand einer Festplatte. Dazu nutzen sie die “Self-Monitoring, Analysis and Reporting Technology” (SMART, [2]), eine in den meisten Festplatten verbaute Technik. Bei externen USB-Platten lassen sich die entsprechenden Informationen aber oft nicht abrufen.
Die Smartmontools finden sich in den Repositories aller gängigen Distributionen, sodass Sie sie in aller Regel über das Paketmanagement des Systems einrichten. Generell müssen Sie alle Smartmontools-Befehle mit administrativen Rechten ausführen. Das in den Beispielen verwendete Device /dev/sda ersetzten Sie durch das Gerät, das Sie testen möchten.
Um die SMART-Funktionen im Festplattencontroller zu aktivieren, geben Sie auf der Konsole smartctl -s on /dev/sda ein. Achten Sie darauf, immer den Gerätenamen der gesamten Festplatte und nicht einer Partition anzugeben. Der Aufruf smartctl -A /dev/sda zeigt den aktuellen SMART-Status der Festplatte an (Abbildung 1).
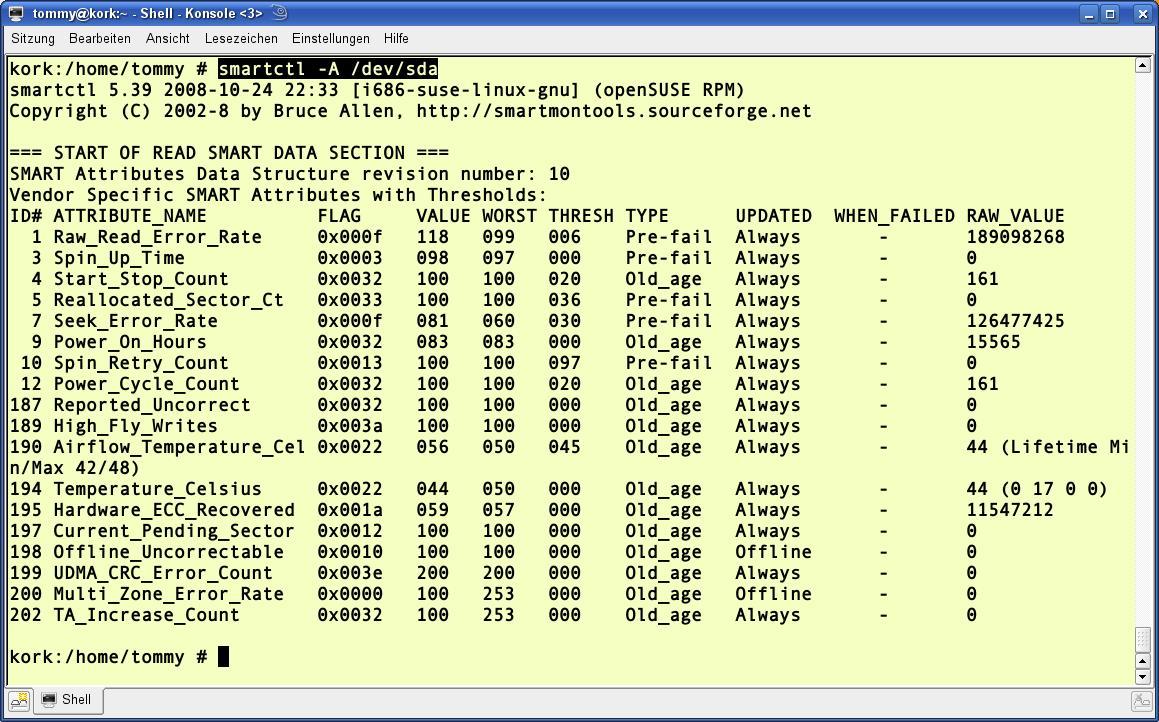
smartctl -A /dev/Device zeigt alle von der Platte bereitgestellten SMART-Attribute in einer Liste an.” width=”300″ height=”187″ />
Abbildung 1: Das Kommandosmartctl -A /dev/Device zeigt alle von der Platte bereitgestellten SMART-Attribute in einer Liste an.Je nach unterstützter Fehlerdiagnose unterscheiden sich die Ausgaben von Smartctl bei Platten verschiedener Hersteller. Die wichtigsten Attribute sind die des Typs Pre-fail aus der Spalte TYPE. Zu jedem Attribut gehört ein vom Hersteller festgelegter normalisierter Wert VALUE, dem in der Spalte WORST der schlechteste tatsächliche Messwert gegenüber steht. Je größer letzterer ausfällt, desto besser. Den dazugehörigen Grenzwert zeigt die Spalte THRESH. Wurde dieser jemals von einem wichtigen Attribut unterschritten, erscheint in der Spalte WHEN_FAILED das entsprechende Datum – höchste Zeit, die Platte zu wechseln.
Einen ersten Hinweis zur die Gesundheit der Platte liefert der Wert von Raw_Read_Error_Rate. Kommt hier der Wert unter WORST nahe an den Grenzwert von THRESH heran, hat die Fehlerkorrektur der Platte reichlich zu tun. Bei hohen Zahlen in der letzten Spalte RAW_VALUE ist zwar keine Panik, aber durchaus Vorsicht geboten.
Der Platten-Controller lagert die Daten aus beschädigten Plattenbereichen in Reservesektoren um. Wie oft so etwas bislang vorkam, zeigt Reallocated_Sector_Ct. Kommt hier WORST in die Nähe des Grenzwerts, gehen die Reservesektoren zur Neige – höchste Zeit für einen Plattenwechsel. Ähnliches gilt für den Eintrag Reported_Uncorrect. Ein Wert größer Null signalisiert nicht korrigierbare Fehler bringt sämtliche Alarmglocken zum Schrillen. Der RAW_VALUE für die Temperatur (Temperature_Celsius) sollte möglichst unter 50 Grad Celsius liegen – je kühler, desto besser. Zeigt UDMA_CRC_Error_Count einen Fehler an, stimmt etwas mit der Festplattenanbindung ans Mainboard nicht.
Steht in der Spalte UPDATED der Eintrag Offline, ermittelt die Software die Werte nicht regelmäßig. Mit dem Aufruf smartctl -t offline /dev/sda fordern Sie die Platte auf, die Daten zu liefern. Das Kommando stößt über den Plattencontroller einen Selbsttest an, was jedoch nicht jede Festplatte unterstützt. Einen kurzen Selbsttest, der meist weniger als eine Minute dauert, leitet das Kommando smartctl -t short /dev/sda ein, mit smartctl -t long /dev/sda starten Sie eine gründliche Prüfung. Sie nimmt einen kompletten Scan der Plattenoberfläche vor und findet damit auch Bad Blocks, dauert jedoch abhängig von der Plattengröße unter Umständen mehrere Stunden. Während dieser Zeit können Sie weiter arbeiten, müssen aber Einschränkungen der Performance hinnehmen. Für beschädigte Platten stellt dieser Test eine ziemliche Belastung dar und befördert das kränkelnde Laufwerk unter Umständen sogar direkt ins Nirvana. Deswegen sollten Sie ihn nicht aufrufen, wenn der Anfangsverdacht eines Defekts besteht.
Möchten Sie sich die Ergebnisse aller bisherigen Selbsttests der Platte anzeigen lassen, erledigen Sie das mit dem Aufruf smartctl -l selftest /dev/sda (Abbildung 2). Stehen in der letzten Spalte keine Einträge, ist die Platte sehr wahrscheinlich in Ordnung. Steht hier ein Wert, handelt es sich dabei um die LBA-Adresse des ersten aufgetretene Fehlers. Wie Sie aus dieser die dazugehörige Datei ermitteln, beschreibt das Bad-Block-Howto [3] auf der Smartmontools-Projektseite.
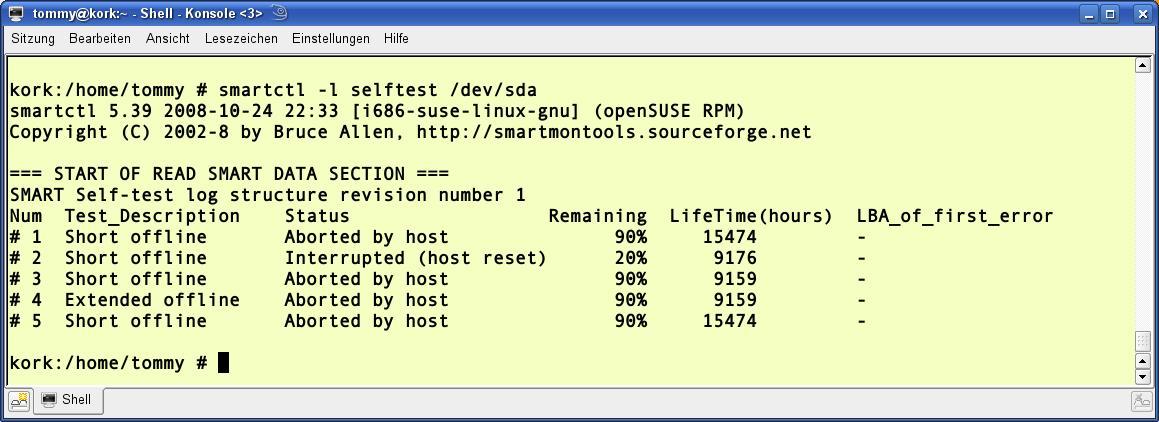
Abbildung 2: Eine Liste gibt Aufschluss darüber, wann und mit welchem Resultat Selbsttests liefen.
Der Befehl smartctl -a /dev/sda zeigt sämtliche verfügbaren SMART-Informationen für die Festplatte, einschließlich der Herstellerangaben und der Ergebnisse der Selbsttests. Einen kurzen Gesundheitscheck der Platte liefert auch smartctl -H /dev/sda. Liegt keine größere Störung vor, gibt das Tool den Wert PASSED zurück. Das hilft jedoch nicht bei der Suche nach defekten Blöcken, da bei Tests auch eine Platte dieses Prädikat erhielt, die definitiv fehlerhafte Blöcke aufwies. Eine komfortable Alternative bietet die grafische Oberfläche Gsmartcontrol (siehe Kasten “HD-Check mit GUI”).
HD-Check mit GUI
Zwar bieten die Smartmontools einen enormen Funktionsumfang, stellen jedoch sowohl beim Bedienen als auch der anschließenden Analyse der Messwerte hohe Ansprüche an die Fachkompetenz des Anwenders. Abhilfe schafft die grafische Oberfläche Gsmartcontrol [5]: Sie erleichtert nicht nur das Handling, sondern zeigt die Ausgabe sauber aufbereitet in einer Tabelle an. Darüber hinaus steht für jeden Messwert eine Hilfestellung bereit, die sich selbständig öffnet, sobald Sie mit dem Mauszeiger einen Augenblick auf dem gewünschten Eintrag verweilen (Abbildung 3).
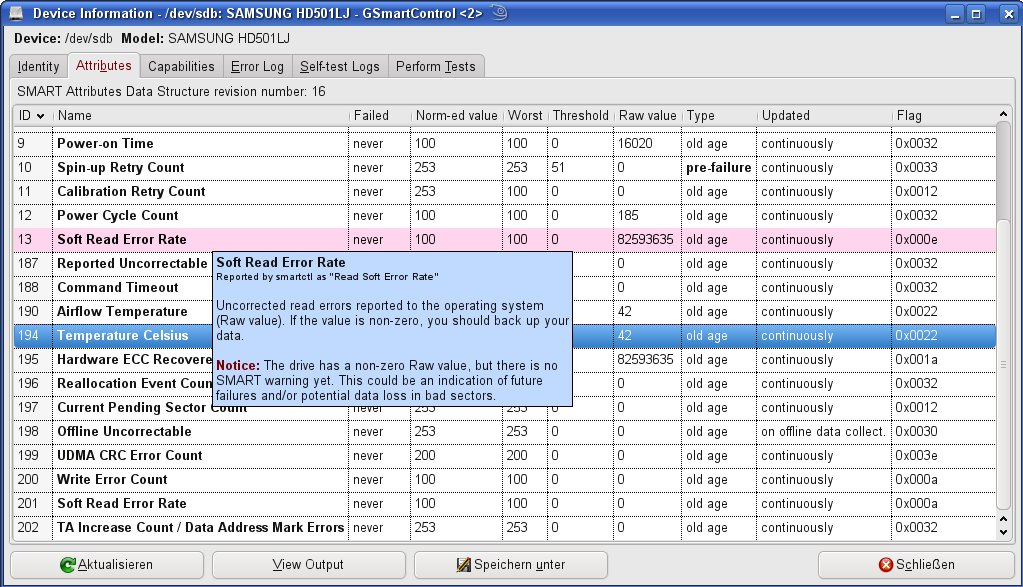
Abbildung 3: Die grafische Oberfläche Gsmartcontrol erleichtert nicht nur das Bedienen der Smartmontools, sondern bietet eine wesentlich übersichtlichere Analyse der Ergebnisse samt interaktiver Hilfe zu den Messwerten.
Pöhze Plöcke
Das Programm badblocks aus dem Paket e2fsprogs gehört zur Standardausstattung aller gängigen Distributionen. Es wurde zur Oberflächenanalyse von Datenträgern konzipiert und stellt damit eine sinnvolle Ergänzung der SMART-Tests dar. Badblocks scannt nur die gewünschte Partition auf fehlerhafte Blöcke, meldet aber anders als Smartctl mehr als einen Fehler und gibt darüber hinaus alle ermittelten defekten Blocknummern aus. Das es blockorientiert arbeitet, spielt das Dateisystem der Partition keine Rolle. Für den Test von RAID-Systemen eignet sich das Programm jedoch nicht.
Wie der Selbsttest mit den Smartmontools belastet die Suche nach fehlerhaften Blöcken die Festplatte erheblich. Deswegen verzichten Sie beim Verdacht einer Beschädigung besser darauf, um nicht etwa die Daten vollständig zu zerstören. Erste Hinweise auf Fehler liefern eventuell merkwürdige Geräusche oder regelmäßig auftretende Lesefehler. Riskieren Sie dennoch einen Scan, dann empfiehlt es sich, vorher eine Datensicherung auf externen Datenträgern anzulegen. Das erledigen Sie am besten mit einem Synchronisationstool wie Rsync, das lediglich die letzten Änderungen auf das Backup überträgt. Für das Retten von Daten von beschädigten Festplatten eignet sich das Programm Myrescue [4], das zunächst alle intakten Bereiche ausliest und erst danach die als defekt erkannten Sektoren – das belastet die Festplatte weniger.
Eine intakte Festplatte dagegen hält auch intensive Oberflächentests problemlos aus. Deswegen empfiehlt es sich, von Zeit zu Zeit eine Suche nach fehlerhaften Blöcken vorzunehmen: Das beste Backup hilft nicht viel, wenn Sie bereits seit Monaten immer wieder die gleichen, fehlerhaften Daten von der Festplatte gesichert haben.
Immerhin bedeutet nicht jeder Fehler gleich den Verlust von Daten. So macht sich ein defekter Block in Video- oder MP3-Dateien oft nur durch einen kaum hörbaren Knackser beim Abspielen bemerkbar. Hat sich aber auch nur ein falsches Bit in einer wichtigen Datei wie der Steuererklärung oder Diplomarbeit eingeschlichen, zieht das womöglich sehr unangenehme Folgen nach sich.
Fehler aufspüren
Das Tool Badblocks kennt mehrere unterschiedlich gründliche Tests. Ohne weitere Parameter nur mit der zu testenden Zielpartition aufgerufen, startet Badblocks einen einfachen Lesetest, wie er auch bei e2fsck -c erfolgt. Damit spüren Sie zwar womöglich nicht alle vorhandenen Fehler auf, aber dafür dauert der Test auch nicht allzu lange. Die Dauer lässt sich etwa mit dem beschriebenen langen Selbsttest von Smartctl vergleichen.
Möchten Sie die von Badblocks ausgegebenen Blocknummern weiter verwenden – etwa, um die dazugehörige Datei zu ermitteln – teilen Sie dem Programm über den Parameter -b die Blockgröße des getesteten Dateisystems mit. Andernfalls geht es von einer Blockgröße von 1024 Byte aus. In großen Partitionen sind die Blöcke jedoch meist 4096 Byte groß. Im Zweifelsfall ermitteln Sie die Blockgröße (Block size) mithilfe des Programms Dumpe2fs aus dem Fundus von E2fsprogs (Listing 1)
Listing 1
# dumpe2fs -h /dev/sda5 | grep "Block" dumpe2fs 1.41.9 (22-Aug-2009) Block count: 2685556 Block size: 4096 Blocks per group: 32768
Der Befehl badblocks -b 4096 /dev/sda5 untersucht beispielsweise die Partition /dev/sda5 mit einer Blockgröße von 4096 Byte im Read-only-Modus. Die Nummern der gefundenen fehlerhaften Blöcke gibt das Programm auf dem Bildschirm aus.
Einen genaueren Test ohne Löschen der vorhandenen Daten ermöglicht der Schalter -n. Badblocks schreibt damit zufällige Prüfmuster auf die Platte und stellt nach dem Lesen die ursprünglichen Einträge wieder her. Mit dem Schalter -v gibt das Programm die getesteten Blöcke aus. Die Option -c beschleunigt den Test, da Sie damit festlegen, wie viele Blöcke das Tool gleichzeitig prüft: In der Grundeinstellung nimmt Badblocks lediglich 64 Blöcke parallel unter die Lupe, Bei den heute üblichen großen Hauptspeichern erweist sich jedoch ein höherer Wert als sinnvoll. So halbierte im Test ein Aufruf mit der Option -c 16384 die Laufzeit nahezu. Die Zusammenfassung der genannten Parameter lautet im Programmaufruf:
# badblocks -n -b 4096 -v -c 16384 /dev/sda5
Diesen nicht zerstörenden Read-Write-Test dürfen Sie nur auf ausgehängte Partitionen anwenden, weswegen Sie die Root-Partition nur über eine andere Installation oder eine Live-CD testen können. Wichtiger sind jedoch die Tests der Anwenderdaten, weswegen Sie dem Heimatverzeichnis eine eigene Partition spendieren sollten. Vor dem Prüfen hängen Sie dieses mit dem Kommando umount /home/ aus; ein Weiterarbeiten als einfacher Benutzer fällt dann allerdings flach.
Rufen Sie das Tool Badblocks mit dem Schalter -w auf, startet es einen intensiven Write-Test, der alle Daten auf der Partition zerstört. Das Programm schreibt und liest mehrere Testmuster, um wirklich alle Fehler zu finden. Der Prüflauf dauert deshalb länger als der nicht zerstörende Read-Write-Test. Diese Variante ist in der Regel nur beim Erstellen eines Filesystems sinnvoll. Das Kommando mke2fs -cc ruft den Test auf und trägt die gefundenen defekten Blöcke gleich in den Bad-Block-Inode des neu erstellten Filesystems ein.
Fördert einer der Tests defekte Blöcke zutage, sollten Sie möglichst schnell die wichtigen Daten retten und danach die Festplatte entsorgen: Mit hoher Wahrscheinlichkeit treten in nächster Zeit weitere Fehler auf. Können Sie die Platte nicht rasch ersetzen und wollen dennoch das Risiko minimieren, gilt es, die defekten Blöcke zu markieren, damit das System sie künftig ausklammert. Das erledigen unter Linux – je nach Gründlichkeit – am besten die Kommandos e2fsck -c (mit dem Read-Only-Test) oder e2fsck -cc (mit dem nicht zerstörenden Read-Write-Test), die alle gefundenen schlechten Blöcke automatisch in den Bad-Block-Inode des Filesystems eintragen. Um die richtige Blockgröße müssen Sie sich dabei nicht mehr kümmern.
Allerdings erlaubt es E2fsck nicht, die Anzahl der gleichzeitig zu testenden Blöcke manuell festzulegen. Ein kleiner Trick hilft, die Suche zu beschleunigen. Dazu rufen Sie folgendes Kommando auf
# badblocks -n -b 4096 -v -c 16384 -o /tmp/badblocks /dev/sda5
Es leitet die Fundstellen durch den Schalter -o in die Datei /tmp/badblocks um, die sie anschließend mit der Option -l an e2fsck übergeben. Achten Sie dabei darauf, dass beide Programme die gleiche Blockgröße verwenden:
# e2fsck -B 4096 -l /tmp/badblocks /dev/sda5
Ob das geklappt hat, kontrollieren Sie mit dem Befehl dumpe2fs -b /dev/sda5. Er gibt alle als defekt markierten Blöcke der Partition aus, die im Bad-Block-Inode des Dateisystems stehen.
Fehler analysieren
Um zu erfahren, zu welcher Datei ein schadhafter Block gehört, verwenden Sie das Kommando debugfs. Es eignet sich für die Dateisysteme Ext2/3/4, auch in eingehängtem Zustand. Ohne weitere Optionen öffnet Debugfs das angegebene Filesystem im Read-only-Modus. Einen schreibenden Zugriff (-w) benötigen Sie nicht; darüber hinaus birgt er die Gefahr, das Dateisystem irreparabel zerstören zu können.
Debugfs arbeitet interaktiv, nach dem Öffnen eines Filesystems zeigt es einen Abfrageprompt zur Eingabe interner Kommandos. Mit help oder ? fordern Sie eine Liste aller verfügbaren Kommandos an, q beendet die Interaktion.
Gibt das Kommando badblocks beispielsweise als defekten Block die Nummer 37678 aus, sagt das erst einmal nur, dass die Festplattenoberfläche an der angegebenen Stelle einen Defekt aufweist. Ob sich dort eine Datei befindet, und falls ja, welche, das verschweigt das Programm.
Jede Datei, dazu zählen auch Verzeichnisse oder Links, benötigt einen Inode, der die Verwaltungsinformationen wie Größe, verwendete Blöcke und Berechtigungen speichert. Die Eingabe von icheck am Debugfs-Prompt ermittelt nun den für den Block zuständigen Inode und dessen Nummer. Bei einer unbenutzten Blocknummer erscheint die Ausgabe <block not found>. Um das zu verhindern, prüfen Sie vorab mit testb, ob der Block zu einer Datei gehört. Den Dateinamen zum Inode liefert der Aufruf ncheck. Listing 2 zeigt ein Beispiel für die Analyse von Bad Block Nummer 37678.
Listing 2
# debugfs /dev/sda5 debugfs: testb 37678 Block 37678 marked in use debugfs: icheck 37678 Block Inode number 37678 72 debugfs: ncheck 72 Inode Pathname 72 /var/lib/logrotate.status debugfs: q
Anhand des Dateinamens (im Beispiel /var/lib/logrotate.status) sehen Sie schnell, ob es sich um eine wichtige Datei handelt oder nicht. Nehmen Sie dann gegebenenfalls den Inhalt genau unter die Lupe – er dürfte etliche Fehler aufweisen. Der Rückgriff auf ein Backup hilft in diesem Fall nur dann, wenn der Fehler bei der Datensicherung nicht mitgespeichert wurde.
Es kommt auch vor, dass ein fehlerhafter Block zum Journal des Filesystems gehört, wie es Ext3 und Ext4 in der Regel auf der gleichen Platte vorhalten. In diesem Fall erhalten Sie keinen Dateinamen. Prüfen Sie hier vorsichtshalber die Dateien, die in der letzten Zeit verändert wurden. Das Journal speichert neue oder geänderte Daten eine gewisse Zeit, bevor sie endgültig in den Datenbereich der Partition gelangen.
In Debugfs ermitteln Sie mit dem Kommando imap auch den zu einem Dateinamen gehörigen Inode, die Metadaten der Datei gibt bei Bedarf stat aus.
Hilfe für Windows
Auf Multiboot-Systemen erschwert unter Windows der bei Vista im Hintergrund laufende Defragmentierer die Diagnose: Er verschiebt regelmäßig Daten und lässt daher das Zuordnen einer Datei zu einem gefundenen Block nur bedingt zu. Weiterhin besteht das Risiko, dass er dabei Teile einer Datei, die vorher auf einem fehlerhaften Block lag, in beschädigter Form in einen fehlerfreien Block schreibt. Umgekehrt gelangt womöglich auf diesem Weg ein Teil einer vorher fehlerfreien Datei in einen defekten Block – dieses Szenario ist zwar unwahrscheinlich, aber nicht ausgeschlossen.
Um den automatischen Start des Defragmentierers zu deaktivieren, geben Sie unter Windows entweder im Schnellstarter oder der Konsole den Befehl defrag ein. Entfernen Sie danach in der Konfiguration das Häkchen bei Nach Zeitplan ausführen (empfohlen). Bei älteren Windows-Versionen erübrigt sich das Deaktivieren des Schedulers, da Sie hier das Defragmentieren in der Grundeinstellung nur manuell auslösen.
Um einen Überblick über den Zustand der Platte zu erhalten und abzuschätzen, ob eine Suche nach fehlerhaften Blöcken lohnt, empfiehlt sich vorab das Prüfen mit SMART. Die Projektseite [1] stellt dazu auch eine Version für Windows zum Download bereit. Beim Aufruf des Programms startet automatisch ein Terminal. Wie bei allen in diesem Artikel erwähnten Programmen erfordert auch dieses Administratorrechte. Derzeit kennt es jedoch noch nicht alle der neueren Festplatten. Zeigt der lange Selbsttest einen Fehler, wiederholen Sie das Prüfen der Platte über ein anderes System, etwa mithilfe einer Linux-Live-CD.
Diagnose via Linux
Auch auf NTFS-Dateisystemen gilt es zunächst, die Größe eines Blocks zu ermitteln. Um unter Linux auf NTFS-Dateisysteme zuzugreifen, installieren Sie das Paket Ntfsprogs. Es enthält Programme, die nach dem Einhängen der entsprechenden Partition das direkte Schreiben und Lesen darauf ermöglichen. Das Kommando ntfscluster gibt einen ersten Überblick über das NTFS-Dateisystem (im Beispiel /dev/sda1, das dafür jedoch nicht gemountet sein darf (Listing 3).
Listing 3
# ntfscluster /dev/sda1 2>/dev/null | grep cluster bytes per cluster : 4096 […]
Auch NTFS verwendet Inodes, die Blöcke heißen hier aber Cluster. Da sich die Programme aus den ntfsprogs noch in einem relativ frühen Entwicklungsstadium befinden, erscheinen des Öfteren Meldungen, dass sie bestimmte Inodes nicht lesen können. Wichtig ist im gezeigten Beispiel aber nur die Größe eines Clusters. Deshalb wandern hier die Fehlermeldungen in den imaginären Abfalleimer /dev/null.
Nun nehmen Sie wie in den bereits genannten Beispielen mithilfe von badblocks einen der Integritätstests vor. Für fehlerhafte Blöcke zeigt das Programm ntfscluster die dazugehörenden Dateien mitsamt deren Inodes. Bei mehreren aufeinander folgenden Blöcken geben Sie einen Bereich an (Listing 4).
Listing 4
# ntfscluster -c 5537792 /dev/sda1 2>/dev/null Searching for cluster 5537792 Inode 58372 /Windows/Driver Cache/i386/sp2.cab/$DATA # ntfscluster -c 5552568-5552575 /dev/sda1 2>/dev/null Searching for cluster range 5552568-5552575 Inode 2264 /Dokumente und Einstellungen/User/NTUSER.DAT_old/$DATA
Das mit Windows gelieferte Programm Chkdsk analysiert zwar auch die Oberfläche von Festplatten und blendet fehlerhafte Blöcke aus. Ein Test mit einer ausgemusterten 40-GByte-Platte zeigte unter Windows XP aber, dass es anscheinend nicht sonderlich gründlich arbeitet: Das Programm prüfte die Platte und zeigte auch eine betroffene Datei an, allerdings in der verstümmelten 8-Byte-Schreibweise aus DOS-Zeiten, was eine genaue Zuordnung erschwert. So gab Chkdsk anstelle des richtigen Namens (NTUSER.DAT_old) NTUSER~1.DAT aus. Einen weiteren von Badblocks erkannten Fehler in einer anderen Datei übersah Chkdsk komplett.
Infos
[1] Smartmontools: http://smartmontools.sourceforge.net
[2] Näheres zu SMART: http://de.wikipedia.org/wiki/Self-Monitoring,_Analysis_and_Reporting_Technology
[3] Bad block Howto: http://smartmontools.sourceforge.net/badblockhowto.html
[4] Myrescue: http://myrescue.sourceforge.net
[5] Gsmartcontrol: http://gsmartcontrol.berlios.de




