

Menschen mit Behinderungen können viele PDF-Dokumente nicht oder nur teilweise lesen. Dabei lassen sich mit nur wenig Aufwand für jedermann zugängliche PDFs erstellen.
Serie Postscript/PDF-Tools
| Teil 1 | Anzeigen und Konvertieren | LU 08/2009, S. 78 | https://www.linux-community.de/artikel/19014 |
| Teil 2 | Zerlegen und Zusammensetzen | LU 09/2009, S. 82 | https://www.linux-community.de/artikel/17410 |
| Teil 3 | Mehrfachdruck und Poster | LU 10/2009, S. 88 | https://www.linux-community.de/artikel/19376 |
| Teil 4 | Flyer, Booklets und Bücher | LU 11/2009, S. 88 | https://www.linux-community.de/artikel/19481 |
| Teil 5 | Analysieren und Extrahieren | LU 12/2009, S. 88 | https://www.linux-community.de/artikel/19635 |
| Teil 6 | Drehen und Skalieren | LU 01/2010, S. 90 | https://www.linux-community.de/artikel/20046 |
| Teil 7 | Metadaten bearbeiten | LU 02/2010, S. 90 | https://www.linux-community.de/artikel/20357 |
| Teil 8 | Wasserzeichen und Barcodes | LU 03/2010, S. 90 | https://www.linux-community.de/artikel/20558 |
| Teil 9 | Werkzeuge für die GUI | LU 05/2010, S. 90 | https://www.linux-community.de/artikel/20051 |
| Teil 10 | Barrierefreie PDFs erzeugen | LU 07/2010, S. 86 | https://www.linux-community.de/artikel/20506 |
PDF-Dokumente lassen sich aus dem Alltag nicht mehr wegdenken. Nahezu jeder Anwender setzt Adobes Dokumentenformat für den Austausch und den Druck seiner Schriftstücke ein – sei es für Verträge, für online erworbene Fahrkarten, für Angebote und Rechnungen, für Vortragsfolien oder für wissenschaftliche Dokumente. Und das zu Recht, denn PDF bietet erhebliche Vorteile gegenüber anderen Formaten:
- es ist ein vollständig offengelegtes, dokumentiertes Format (Adobe PDF-Spezifikation),
- es lässt sich auf allen Plattformen erzeugen, bearbeiten und nahezu identische darstellen,
- und es stellt die Unveränderbarkeit (Integrität) beim Datenaustausch sicher.
Ungeachtet aller Vorteile sind auch einige Nachteile mit diesem Format verbunden. Der normale Benutzer nimmt sie selten bewusst wahr, da sie erst zutage treten, sobald ein Anwender nicht oder nur eingeschränkt über bestimmte motorische oder visuelle Fähigkeiten verfügt und zur Wahrnehmung auf Hilfsmittel angewiesen ist.
Zur Darstellung für solche Benutzer gilt es das PDF-Dokument so transformieren, dass der Anwender den Inhalt mit seinen Hilfsmitteln erfassen kann (siehe dazu auch Kasten “Gesetze und Richtlinien”). Häufig verwendete Hilfsmittel sind beispielsweise:
- Vergrößerungssysteme für Menschen mit Sehbehinderungen – dabei handelt es sich um eine Kombination verschiedener Funktionen, wie Vergrößerung, Kantenglättung, kontrastreiche Farbdarstellung sowie spezielle Mauszeiger,
- Sprachausgabe und Braille-Zeile [1], die hauptsächlich Blinde nutzen.
Wieviel mehr Benutzern man mit einem entsprechend barrierefreien PDF erreichen kann, darüber liegen derzeit noch keine wissenschaftlichen Erkenntnisse vor. Ausgehend vom Verbreitungsgrad von PDF darf man aber annehmen, dass der Wert hier ähnlich ausfällt wie bei barrierefreien Internetauftritten, also bei rund 20 Prozent zusätzlicher Nutzer [2].
Gesetze und Richtlinien
In Deutschland wurden 2002 mit der sogenannten Barrierefreien Informationstechnikverordnung (BITV, [28]) eine gesetzliche Grundlage für Barrierefreiheit geschaffen. Sie basiert auf §11 Absatz 1 Satz 2 des Behindertengleichstellunggesetzes (BGG, [29]).
Die BITV gilt für öffentliche und nichtöffentliche Internetangebote sowie für “mittels Informationstechnik realisierte graphische Programmoberflächen, die öffentlich zugänglich” und den Behörden der Bundesverwaltung zuzuordnen sind. Bezugspunkt sind gemäß Anlage 1 der BITV die Web Content Accessibility Guidelines (WCAG, [30]), die von der WAI-Arbeitsgruppe des W3C erarbeitet wurden (Web Accessibility Initiative, [31]).
Im Kontext von PDF lassen sich die in den WCAG angesprochenen Richtlinien zur Barrierefreiheit aus mehreren Perspektiven betrachten:
- Ein Dokument muss technisch barrierefrei sein,
- es muss inhaltlich sowie sprachlich logisch erfassbar sein,
- der PDF-Reader muss zugänglich sein, und
- Autoren mit Behinderung muss ein barrierefreies Autorenwerkzeug zur Verfügung stehen.
Die WAI stellt eine Reihe von Richtlinien zur Verfügung, mit deren Hilfe Entwickler und Autoren entsprechend arbeiten können. Dazu zählen:
- die bereits erwähnten Richtlinien für den Inhalt von Internetseiten [30],
- die Authoring Tool Accessibility Guidelines (ATAG, [32]) hinsichtlich der Werkzeuge zum Erstellen von Internetseiten, sowie
- die User Agent Accessibility Guidelines (UAAG, [33]), die Maßgaben für die Darstellung im Anzeigeprogramm.
Erstere greift auch für die PDF-Dokumente, die zweiten für PDF-Editoren und die dritten für PDF-Reader (siehe dazu Teil 1 dieser Serie, [34]).
Es gibt jedoch auch den PDF-Standard PDF/A-1a ([35],[36]), der explizit das Erstellen barrierefreier Dokumente zum Ziel hat. “A” steht dabei für Langzeitarchivierung und “1a” bezeichnet Spezifikationen, die gewährleisten sollen, dass Menschen unter Verwendung sogenannter assistiver Technologien [37] die Inhalte der Dokumente wahrnehmen können. PDF/A-1a enthält Vereinbarungen zu Namensräumen (“Namespaces”), Farben und Farbräumen, Metadaten, digitalen Signaturen und den XMP-Daten ([38],[39]).
Auflösungserscheinungen
Viele PDF-Betrachter verfügen bereits über eine stufenlose Vergrößerung bis zu 400 Prozent, beispielsweise Okular und Ghostview (Abbildung 1). Reicht das nicht mehr aus, bieten sich als Vergrößerungssystem die Werkzeuge GnomeMag aus dem Orca-Projekt [3], das zu Compiz gehörende Ezoom [4] oder Virtual Magnifying Glass ([5], Abbildung 2) an. Eine ausführliche Beschreibung der verfügbaren Programme und der technischen Hintergründe diskutiert der Verein LinAccess e.V. [6] im LinuxWiki [7].
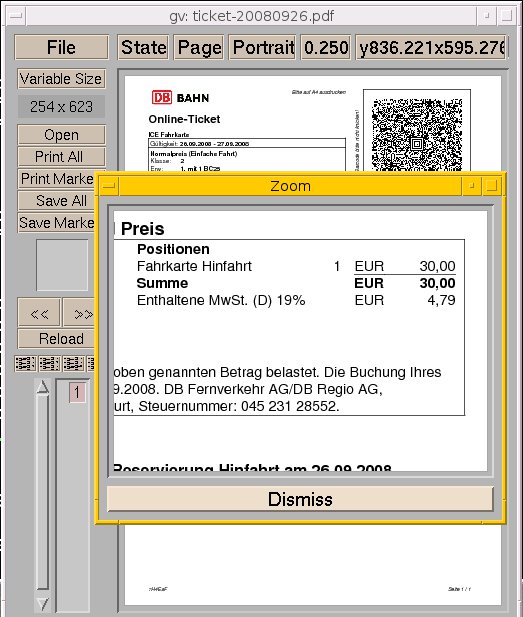
Abbildung 1: Vergrößerte Darstellung in Ghostview.
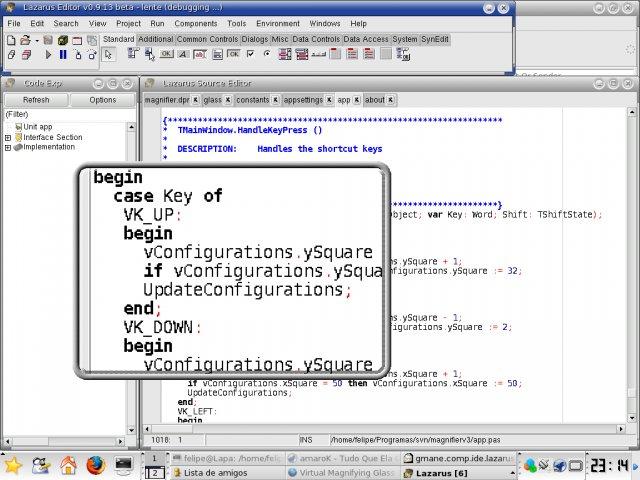
Abbildung 2: Darstellung eines Bildschirmausschnitts mit Virtual Magnifying Glass.
Aus administrativer Sicht ins Gewicht fällt hier das Zusammenspiel der Rendering-Engine im PDF-Betrachter beziehungsweise des Vergrößerungssystems und der Auflösung, in der das angezeigte PDF-Dokument vorliegt: Je mehr vergrößert werden muss, umso mehr Leistung schluckt das Neuberechnen des Bilds. So schön und handlich Netbooks im Alltag auch sein mögen – hier zeigen sich deren Leistungsgrenzen ganz deutlich.
Hat das PDF-Dokument eine geringe Auflösung (typischerweise 72 dpi für die reine Bildschirmdarstellung), treten bei stärkerer Vergrößerung vermehrt Treppeneffekte und Graustufen auf. Gleichzeitig nimmt die Schärfe der Darstellung ab, da die Rendering-Engine das Bild nicht mehr adäquat nachjustieren kann. PDF-Dokumente mit einer Auflösung ab 300 dpi (eigentlich primär für den Druck gedacht) sorgen hier für ein deutlich besseres vergrößertes Bild am Monitor.
Zur Qualität der Darstellung tragen daneben auch die Einstellungen des PDF-Betrachters bei. Im Adobe Reader lässt sich die gewünschte Auflösung unter Bearbeiten | Voreinstellungen im Abschnitt Seitenanzeige fest vorgeben. Das Grafiksystem berechnet das Bild dann vor der tatsächlichen Darstellung passend nach.
Screenreader
Bildschirmleseprogramme, sogenannte Screenreader, lesen die Bildschirminformationen aus und leitet sie an eine Sprachausgabe und eine Braille-Zeile weiter. Seit längerer Zeit gibt es dazu mehrere, parallele Projekte und Entwicklungszweige für Unix- und Linux-Systeme. Eine Zusammenstellung verfügbarer Programme findet sich bei Wikipedia [8].
Eines der ältesten Projekte in diesem Bereich ist der Text-Screenreader brlTTY [9], den die Entwickler immer noch weiter perfektionieren. brlTTY unterstützt die meisten Braillezeilen und bietet eine gut spezifizierte Schnittstelle zur Informationsübergabe zwischen Bildschirmausgabe und Braille-Zeile. In Kombination mit Pdftotext [10] lässt sich brlTTY auf der Kommandozeile dazu nutzen, Textdaten aus PDF-Dokumenten zu erhalten und zu verarbeiten.
Bis zum Frühjahr 2007 unterstützte IBM das Projekt “Linux Screen Reader” (LSR), das einen Screenreader für Gnome entwickeln sollte. Der letzte Projektstand lässt sich unter [11] nachlesen: LSR wurde eingestellt, da Orca [12] leistungsfähiger ist und IBM in der Weiterentwicklung von LSR keinen Sinn mehr sah.
Orca soll optimal mit allen Programmen zusammenarbeiten, die auf den Gnome-Bibliotheken aufsetzen, wie etwa Evolution, Pidgin, und dem Gnome-Terminal. Lange Zeit wurde das Projekt (Abbildung 3) auch von Sun Microsystems unterstützt, um Orca auf OpenSolaris verwenden zu können. Im Zug der Veränderungen nach dem Kauf von Sun Microsystems durch Oracle fiel dieser Support kürzlich jedoch weg. Bis zum Redaktionsschluss lag dazu keine offizielle Stellungnahme vor. Da Orca jedoch eine gute Community aufgebaut hat, besteht begründete Hoffnung, dass das Projekt diesen Rückschlag relativ unbeschadet übersteht und erfolgreich fortgesetzt wird.
Abbildung 3: Das Logo des Orca-Projekts mit dem Schriftzug GNOME in Form von Braille-Zeichen.
2007 gestartet, läuft das vom Bundesministerium für Arbeit und Soziales unterstützte Forschungsprojekt SUE (“SUE Screenreader & Usability Extensions”, [13]) Ende Juni 2010 aus. Die Federführung bei SUE haben die IT Science Center Rügen [14] (ein An-Institut der Uni Rostock) und das Studienzentrum für Sehgeschädigte der Uni Karlsruhe [15]. Ziel des Projekts war es, einen Screenreader für graphische Oberflächen und Anwendungen unter Linux zu entwickeln. Er soll die wichtigsten im Arbeitsumfeld erforderlichen Aufgaben unterstützen, wie die Nutzung des Desktops, den Umgang mit der Textverarbeitung und der Tabellenkalkulation, das Bearbeiten von E-Mails sowie die Arbeit mit dem Webbrowser.
Wie LSR und Orca setzt SUE dabei auf das Gnome-Framework. Das liegt nicht zuletzt daran, dass Gnome im Gegensatz zu Qt/KDE bereits über Accessibility-Schnittstellen verfügt. Eine Accessibility-Erweiterung für Qt4 befindet sich noch in Arbeit [16]. Sowohl LSR als auch SUE stehen noch in einer frühen Entwicklungsphase und lassen sich bislang nicht sinnvoll nutzen.
Ganz anders Klaus Knoppers nach seiner blinden Frau benannte Adriane-Projekt (“Audio Desktop Reference Implementation and Networking Environment”, [17]): Das gut funktionierende System ist dafür gedacht, insbesondere den Zugang zu den Standard-Internetdiensten E-Mail, WWW sowie das Einscannen und Vorlesenlassen von Dokumenten und die Benutzung von Mobilfunk-Diensten wie SMS über ein eigenes Handy zu erleichtern. Dazu integriert es den “Screenreader for Blind Linux Users” (SBL, [18]) von Marco Skambraks und Halim Sahin.
Sprachausgabe
Neben Vergrößerungssystemen stellt die Sprachausgabe – in der Regel direkt an den Screenreader angedockt – ein elementares Hilfsmittel dar. Hier gilt es zu unterscheiden zwischen:
- anwendungsspezifischen Sprachausgaben, die manche Applikationen mitbringen (und die meist nur die Informationen innerhalb der Anwendung vorlesen) und
- der systemweiten Sprachausgabe, die dem Nutzer die volle Orientierung über alle Prozesse und Ansichten, also die komplette Bildschirmausgabe, überträgt.
Eine ausführliche Beschreibung der Funktionalität von Sprachausgaben würde den Rahmen dieses Artikels sprengen – gute Informationen dazu bietet beispielsweise der Informationspool für Computerhilfsmittel für Blinde und Sehbehinderte [19].
Die Braille-Zeile
Bei der Braille-Zeile handelt es sich um eine externe Hardware-Erweiterung für den Computer, die man je nach Modell entweder über ein serielles Interface, die USB-Schnittstelle oder über Bluetooth anschließt. Eine Braille-Zeile nimmt je nach Modell 20, 40 oder 80 Zeichen auf und stellt Text in Form von Braille-Zeichen [1] dar.
Braille-Zeichen bezeichnet man umgangssprachlich auch oft als Punktschrift, da sie jeden Buchstabe und jede Ziffer in sechs, sieben oder acht Punkten codieren. Auf Papier kommen sechs Punkte zum Einsatz, wohingegen eine Braille-Zeile mit acht Punkten alle 256 Zeichen des ASCII-Zeichensatzes abbildet. Die Anordnung der Punkte ist international standardisiert, der Leser erfasst den Text durch das Ertasten dieser Punkte. In der Braille-Zeile werden sie durch variable Metallstifte repräsentiert, die leicht hervorstehen. Aus der Abfolge der Erhebungen ergeben sich die einzelnen Buchstaben, Ziffern und Satzzeichen.

Abbildung 4: Eine Braille-Zeile am PC. (Bild: Matthieu Faure, GFDL/CC-BY-SA)
Stolperstellen
Das erfolgreiche Nutzen des Screenreaders und der daran gekoppelten Braille-Zeile und Sprachausgabe setzt voraus, dass sich die Textdaten in Form von einzelnen Zeichen überhaupt aus dem PDF-Dokument oder vom Bildschirm identifiziert und extrahiert lassen. Besonders ärgerlich ist es, wenn die Extraktion nur teilweise gelingt oder als Ergebnis lediglich ein wirrer Buchstabensalat entsteht.
Enthalten gescannte Dokumente oder Rastergrafiken beispielsweise Buchstaben, Ziffern oder eine Handschrift ausschließlich als Pixelfolge, lässt sich diese nicht automatisch ablesen, erkennen oder erraten und entfällt daher komplett. Auch mit dem Zwischenschritt über eine OCR-Software gelingt eine Erkennung nur bis zu einem gewissen Grad [20]. Weitere mögliche Stolperstellen in PDF-Dokument sind zum Beispiel:
- Artefakte (Linien, Marken, Bilder, Hervorhebungen),
- mehrspaltiger Text,
- Bilder ohne Alternativ-Text,
- Fußnoten und Lesezeichen,
- Kopf- und Fußzeilen sowie Seitennummern,
- Seitenumbrüche im Fließtext und harte Trennstriche,
- PDF-Erweiterungen (etwa Javascript) sowie
- PDF-Nutzungseinschränkungen (Drucken).
Die Vorverarbeitung für den Screenreader versucht zunächst, die richtige Reihenfolge für das Vorlesen der Textelemente zu erkennen. Ohne korrekte Markierung der Textblöcke fehlt dem Programm jedoch die Orientierung im Datenstrom. Das fällt besonders bei mehrspaltigem Text auf, sowie bei Tabellen und Abbildungen, die in den Textfluss eingebettet sind. Der Screenreader muss klar alle irrelevanten Elemente erkennen können, die er nicht vorlesen soll: beispielsweise Hintergrundgrafiken, Seitennummern oder Kopf- und Fußzeilen.
Eine weitere Hürde stellen Umlaute, Sonderzeichen und nicht zueinander passende oder noch nicht vollständig unterstützte Zeichencodierungen dar (ASCII, ISO8859-15, Unicode). Das gilt sowohl für die einzelnen Programme, die die beispielsweise Umlaute unterschiedlich darstellen (":u" oder ""u"), als auch für die Ausgabegeräte und die verarbeiteten PDF-Dokumente. Bedenklich sind nicht etwa die Standards an und für sich, sondern vielmehr der Reifegrad des Zusammenspiels der einzelnen Komponenten. Deutlich wird das erst, wenn man die Komponenten zusammen nutzt und sich dabei herausstellt, dass etwa eine Braille-Zeile nichts mit UTF-8-kodiertem Text anfangen kann.
Alle Buchstaben aus dem PDF-Dokument, die nicht erkannt wurden, lassen sich weder an die Braille-Zeile noch an die Sprachausgabe weiterleiten. Diese Zeichen fehlen letztendlich im Datenstrom, die Informationen gehen für den Benutzer somit vollständig verloren.
Darstellung von Bilddaten
Bilddaten lassen sich als solche nicht auf einer Braille-Zeile ausgeben. Üblicherweise fügt man stattdessen eine Beschreibung in den Text ein oder fertigt auf Spezialpapier oder Folie eine spezielle Prägung der Abbildung an, die der blinde Benutzer ertasten kann.
Sofern die Textelemente einer Abbildung als separate Ebene vorliegen, lassen zumindest diese sich aus dem Bild extrahieren. Kommt etwa das Vektorgrafikformat SVG zum Einsatz, wertet man dazu die Textknoten (<text>) aus, im Speziellen den Inhalt des <tspan>-Tags. In Abbildung 5 (eine mit Inkscape erzeugte SVG-Datei) ist das Ergebnis die weiß hinterlegte Buchstabenfolge XSLT/XSL-FO.
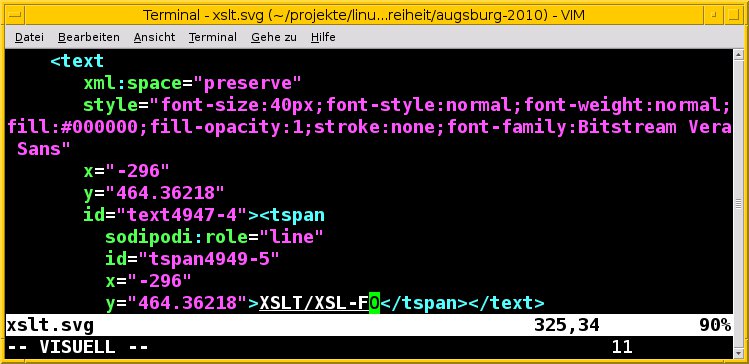
Abbildung 5: Screenreader können zwar keine Grafiken vorlesen, aber zumindest die Textknoten aus einer SVG-Datei.
Barrierefreie PDFs
Um möglichst barrierefreie PDF-Dokumente zu erzeugen, bedarf es einer Reihe von zum Teil recht komplexen Schritten. Wir stellen dies hier anhand des Textsatzsystems LaTeX und von OpenOffice Writer genauer vor. Für Entwickler ist daneben sicher PDFlib-8 interessant, womit sich ebenfalls PDF/A-1a-konforme Dokumente erzeugen lassen [21].
Generell gilt es zu beachten, Textdaten ausschließlich als Zeichen und nicht etwa als Bild einzubinden. PDF-Dokumente, die aus Bildern mit eingescanntem Text bestehen, sind zur automatisierten Verarbeitung in diesem Fall nahezu wertlos. Bei dieser Methode bleibt der Text unzugänglich, da ein Screenreader von Hause aus keine OCR-Funktionalität und Schrifterkennung mitbringt, um den Inhalt des Bildes zu analysieren und in Buchstaben zurückzuwandeln. Werkzeuge wie Pdftotext scheitern ebenfalls, da sie keine Bilddaten auswerten. Als Nebeneffekt gerät das PDF-Dokument mit dieser Methode unnötig groß und kann schnell mehrere MByte umfassen.
Den wichtigsten Punkt stellt das Tagging von PDF-Dokumenten dar. Solche Tags kennzeichnen die Textelemente. Anhand dieser Markierungen kann der Screenreader beispielsweise eine Überschrift auch als solche erkennen, korrekt verarbeiten und schließlich passend ausgegeben. als Dreh- und Angelpunkt kristallisiert sich bei der Erstellen des Dokuments die passende Struktur und korrekte Anwendung der Tags heraus.
Wie bei Webseiten gilt es die in das PDF eingebundenen Abbildungen mit dazu passenden Bildunterschriften und Alternativtexten zu versehen, damit der Screenreader diese Informationen auswerten kann.
Barrierefrei mit LaTeX
In ihrer Diplomarbeit beschreibt Babett Schalitz (TU Dresden, 2007), welche Schwachstellen LaTeX in Bezug auf Barrierefreiheit aufweist und wie man diese umgeht. Sie hat dazu ein eigenes LaTeX-Paket entwickelt [22]. Als Alternative dazu haben wir die beiden Standard-Pakete Hyperref und Pdfx unter die Lupe genommen.
Mit dem TeX-Paket Hyperref [23] lassen sich die PDF-Metainformationen festlegen, wie beispielsweise Autor, Titel und Schlüsselworte [24]. Daneben verfügt Hyperref (Abbildung 6) über eine Option pdfa: Sie erzeugt zwar kein PDF/A-konformes Dokument, sorgt aber immerhin dafür, dass durch Pdftex erzeugte Dokumente den PDF/A-Standard nicht verletzen, indem in diesem Kontext unzulässige TeX-Kommandos und Optionen nicht ausgeführt werden.
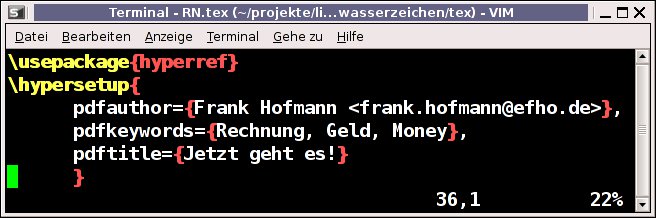
\usepackage-Befehl binden Sie das Hyperref-Paket ins LaTeX-Dokument ein.” width=”300″ height=”100″ />
Abbildung 6: Mit einem schlichten\usepackage-Befehl binden Sie das Hyperref-Paket ins LaTeX-Dokument ein.Das TeX-Paket Pdfx [25] gestattet das Erzeugen von Dokumenten, die zu den Standards PDF/A-1b und PDF/X-1a konform sind ([26],[27]). Daraus resultiert zwar eine eindeutige visuelle Reproduzierbarkeit (PDF/A-1b) und die Daten lassen sich als Druckvorlage nutzen (PDF/X-1a) – wirklich barrierefrei sind die Dokumente aufgrund fehlender Strukturinformationen für den Screenreader jedoch nicht.
Barrierefrei mit OOo
Bei OpenOffice ist die Unterstützung für Barrierefreiheit schon sehr weit gediehen. Die elementarsten Bestandteile sind das konsequente Verwenden von Formatvorlagen (siehe Kasten “OOo-Formatvorlagen”) und der korrekte Export als Tagged-PDF, das Sie als Autor explizit anstoßen müssen. Der Export funktioniert weitgehend korrekt, erweist sich aber als immer noch fehleranfällig. Daher muss man die erzeugten Dokumente nachbearbeiten, beispielsweise mit Adobe Acrobat.
OOo-Formatvorlagen
Unter einer Formatvorlage versteht man bei OpenOffice die Darstellungsoptionen (Formatierungen) von Absätzen und Zeichen. Daneben lassen sich auch Inhalte vordefinieren, beispielsweise für Kopf- und Fußzeilen. OpenOffice unterscheidet die Formatvorlagen je nach Einsatzgebiet, etwa Absatzvorlagen für Textabsätze, Rahmenvorlagen für Rahmen und Grafiken sowie Seitenvorlagen zur Festlegung für die gesamte Seite. Ausgenommen sind hier nur die Einstellungen für die Spaltenaufteilung. Weitere Informationen zu den Vorlagen finden sich im OpenOffice-Wiki [40].
Für diesen Artikel erstellen wir ein Testdokument (Abbildung 7), das etliche Fallstricke aus dem Alltag enthält, wie beispielsweise einen Bereich mit zwei Spalten. Damit zeigen wir die einzelnen Arbeitsschritte vor und nach dem Export in das PDF/A-1a Format und prüfen die einzelnen Werkzeuge auf ihre Brauchbarkeit.

Abbildung 7: Das Testdokument für die Fähigkeiten von OpenOffice.
Nach dem Erstellen eines leeren Dokuments in OOWriter öffnen Sie den Formatvorlagen-Dialog über die Taste [F11] (Abbildung 8). Es empfiehlt sich, zunächst den gesamten Textinhalt zu erstellen und die Formatvorlagen erst am Ende des Arbeitsprozesses zuzuweisen. Diese Reihenfolge ist jedoch nicht zwingend. Im Testdokument verwenden wir die folgenden Formatvorlagen:
- Titel und Untertitel,
- Überschrift erster bis dritter Ordnung,
- einen Link innerhalb eines Fließtextes,
- eine Grafik mit Untertitel sowie
- eine Tabelle.
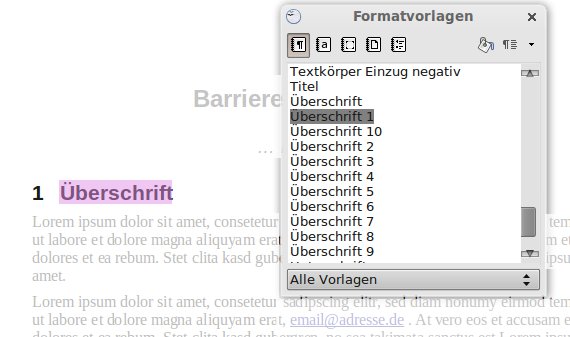
Abbildung 8: Der OpenOffice-Dialog zur Zuweisung der Formatvorlagen.
Im ersten Schritt geben Sie den Text ein, erzeugen über Extras | Kapitelnummerierung eine Dokumentgliederung und weisen danach den einzelnen Textteilen die entsprechende Vorlage zu. Im zweiten Schritt erstellen Sie den mehrspaltigen Bereich. Dazu setzen Sie nicht etwa unsichtbare Tabellen ein, sondern legen stattdessen die Anzahl und Anordnung der Spalten über den Dialog Format | Spalten fest (Abbildung 9).
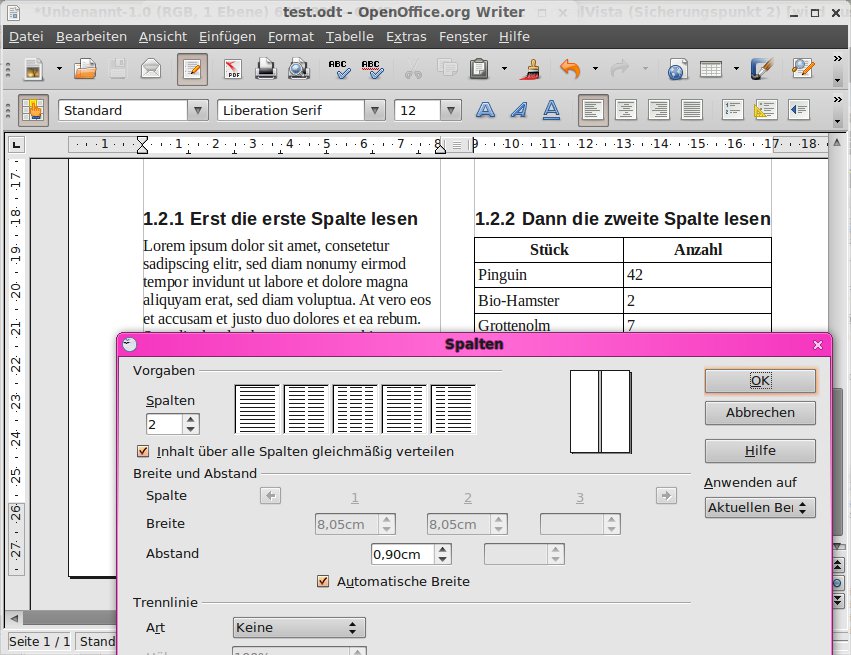
Abbildung 9: Zum Zuweisen der Spaltenanzahl gibt es in OpenOffice einen ausführlichen Dialog.
Im dritten Schritt folgt das Eintragen des Alternativtextes für Abbildungen: Mit einem Rechtsklick auf das Bild öffnen Sie das entsprechende Kontextmenü. Wählen Sie dort die Registerkarte Zusätze und tragen einen kurzen, beschreibenden Text für das Bild ein (Abbildung 10). Es empfiehlt sich, nur dann einen Alternativtext zu setzen, wenn das Bild wichtige Informationen übermittelt. Ansonsten ist es besser, das Bild mittels Umlauf | Im Hintergrund als Hintergrundbild abzulegen.
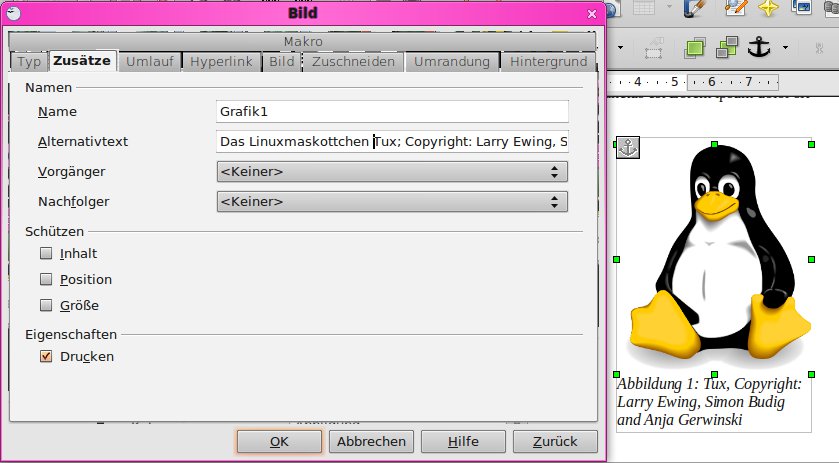
Abbildung 10: Über das Kontextmenü geben Sie zusätzliche Informationen zum Bild ein.
Wichtig: Der Alternativtext sollte eine neutrale Beschreibung des Bilds enthalten – in unserem Beispiel etwa: “Grafik eines sitzenden und grinsenden Pinguins”. Sollte es sich um ein interaktives PDF-Dokument handeln und eine Grafik einen Button darstellen, müssen Sie im Alternativtext dessen Funktion des Buttons hinterlegen, zum Beispiel “Absenden”. In der Bildunterschrift kann dann ein durchaus auch journalistischer Text stehen.
In Schritt 4 setzen Sie nun unter Datei | Eigenschaften | Beschreibung den Dokumenttitel und die Schlüsselwörter sowie einen Kommentar zum Dokument (Abbildung 11). Im vorletzten Schritt prüfen Sie das Dokument nun noch einmal akribisch: Sind alle Formatvorlagen und Tabellenüberschriften zugewiesen, alle Links als solche schon im Text angelegt? Ist der Text sprachlich logisch?
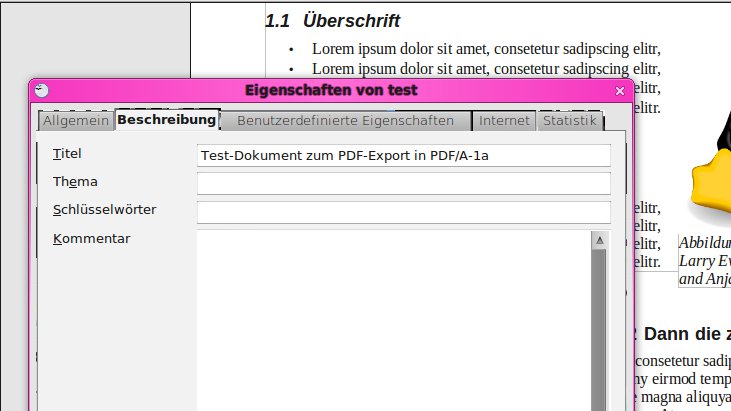
Datei | Eigenschaften | Beschreibung setzen Sie die Dokumenteigenschaften.” width=”300″ height=”169″ />
Datei | Eigenschaften | Beschreibung setzen Sie die Dokumenteigenschaften.Im sechsten und letzten Schritt steht nun der Export nach PDF an. Den stoßen Sie über den Menüpunkt Datei | Export als PDF an (Abbildung 12). Setzen Sie dabei im Dialogfenster das Häkchen vor PDF/A-1a gesetzt, erzeugt OpenOffice dabei die Tags automatisch. In Sonderfällen lässt sich der PDF/A-1a-Standard nicht verwenden – dann wählen Sie alternativ explizit die Option Tagged PDF.
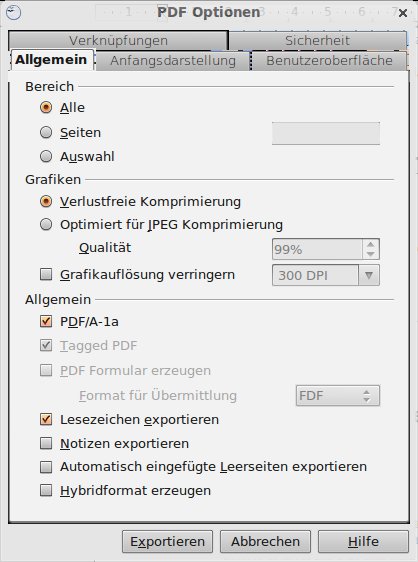
Abbildung 12: Über die PDF-Export-Optionen sorgen Sie für die Erzeugung eines (beinahe) barrierefreien Dokuments.
Die Dateigröße kann beim Export erheblich zunehmen, da OpenOffice zusätzlich zum eigentlichen Inhalt die gesamten Markierungen im Dokument ablegt. So enthalten PDFS gemäß PDF/A-1a alle verwendeten Schriftarten sowie sämtliche Bilder oder extern referenzierten Dateien. Erweiterungen, welche die Darstellung des Textes im PDF-Betrachter verändern (etwa Javascript) bleiben andererseitsaußen vor.
Unser Dokument enthält eine Abbildung mit Transparenzen – das ist nach PDF/A-1a nicht konform. OpenOffice erzeugt dementsprechend eine Warnung (Abbildung 13) und retuschiert die Transparenzen.
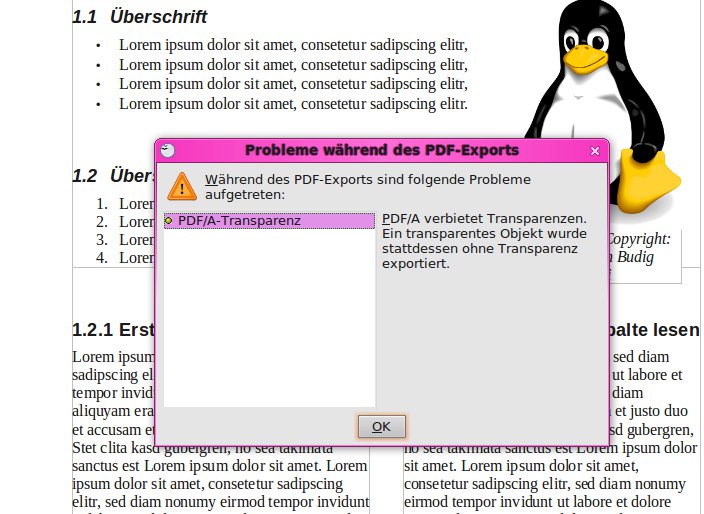
Abbildung 13: Nicht PDF/A-1a-konform: Bei Transparenzen in Abbildungen warnt OpenOffice und bessert entsprechend nach.
Ausblick
Das korrekte Erzeugen eines weitgehend barrierefreien PDFs stellt aber erst die halbe Miete dar. Nun gilt es die Qualität des Dokuments zu prüfen und gegebenenfalls nachzubessern. Im nächsten Teil dieses Workshops stellen wir die dazu nötigen Werkzeuge und Verfahrensweisen vor. Außerdem untersuchen wir, wie gut die verschiedenen Lesewerkzeuge mit unserem Erzeugnis zurecht kommen und wo sie Schwachstellen aufweisen. Abschließend werfen wir dann einen Blick in die Zukunft barrierefreier PDF-Dokumente für Linux.
Infos
[1] Braille-Schrift (Wikipedia): http://de.wikipedia.org/wiki/Brailleschrift
[2] Zugang für Alle: http://www.access-for-all.ch
[3] Gnome-mag: http://live.gnome.org/GnomeMag
[4] Compiz-Fusion-Plugin Ezoom: http://wiki.compiz.org/Plugins/Ezoom
[5] Virtual Magnifying Glass: http://sourceforge.net/projects/magnifier/
[6] LinAccess e.V.: http://www.linaccess.org
[7] Vergrößerungssoftware für Linux im Überblick: http://linuxwiki.de/LinAccess/Projekte/Compiz-eZoom
[8] Screenreader (Wikipedia, englisch): http://en.wikipedia.org/wiki/List_of_screen_readers
[9] brlTTY-Projekt: http://dave.mielke.cc/brltty/
[10] PS/PDF-Tools, Teil 5: Frank Hofmann, “Scheibchenweise”, LU 12/2009, S. 88, https://www.linux-community.de/artikel/19635
[11] Linux Screen Reader: http://live.gnome.org/LSR/
[12] Orca: http://projects.gnome.org/orca/
[13] Projekt SUE: http://service.it-science-center.de/mediawiki/index.php
[14] IT Science Center Rügen: http://www.it-science-center.de/
[15] SZS der Universität Karlsruhe: http://www.szs.uni-karlsruhe.de/
[16] Accessibility in Qt4.3: http://doc.trolltech.com/4.3/accessible.html
[17] Projekt Adriane: http://knopper.net/knoppix-adriane/
[18] Screenreader for Blind Linux Users: http://www.openblinux.de/
[19] Sprachausgaben bei Incobs: http://www.incobs.de/produktinfos/sprachausgaben/index.php
[20] OCR-Software bei Ubuntuusers.de: http://wiki.ubuntuusers.de/Texterkennung_(OCR)
[21] PDFlib-8: http://www.pdflib.com/download/pdflib-family/pdflib-8/
[22] Babett Schalitz: Accessibilityerhöhung von LaTeX, Diplomarbeit, TU Dresden, 2007, http://www.babs.gmxhome.de/da_start.htm
[23] Hyperref-Paket (CTAN): http://www.ctan.org/tex-archive/macros/latex/contrib/hyperref/
[24] PS/PDF-Tools, Teil 7: Frank Hofmann, “Innere Werte”, LU 02/2010, S. 90, https://www.linux-community.de/artikel/20357
[25] Pdfx-Paket (CTAN): http://www.ctan.org/tex-archive/macros/latex/contrib/pdfx/
[26] PDF/A-1b-konforme Dokumente mit Pdftex: http://www.apfeltalk.de/forum/pdftex-pdf-1b-t299359.html
[27] “Generating PDF/A compliant PDFs from pdftex”: http://support.river-valley.com/wiki/index.php?title=Generating_PDF/A_compliant_PDFs_from_pdftex
[28] “Verordnung zur Schaffung barrierefreier Informationstechnik nach dem Behindertengleichstellungsgesetz”: http://www.gesetze-im-internet.de/bitv/
[29] “Gesetz zur Gleichstellung behinderter Menschen”: http://www.gesetze-im-internet.de/bgg/
[30] W3C Web Content Accessibility Guidelines 2.0: http://www.w3.org/TR/WCAG20/
[31] W3C Web Accessibility Initiative (WAI): http://www.w3.org/WAI/
[32] W3C Authoring Tool Accessibility Guidelines (ATAG) 1.0: http://www.w3.org/TR/WAI-AUTOOLS/
[33] W3C User Agent Accessibility Guidelines (UAAG) 1.0: http://www.w3.org/TR/WAI-USERAGENT/
[34] Tools für PS/PDF-Tools (1): Frank Hofmann, “Bild und Druck”, LU 08/2009, S. 78, https://www.linux-community.de/artikel/19014
[35] PDF/A (Wikipedia): http://de.wikipedia.org/wiki/PDF/A
[36] PDF/A Competence Center: http://www.pdfa.org
[37] Assistive Technologien (Wikipedia, englisch): http://en.wikipedia.org/wiki/Assistive_technology
[38] Extensible Metadata Platform (XMP) bei Wikipedia: http://de.wikipedia.org/wiki/Extensible_Metadata_Platform
[39] Extensible Metadata Platform: http://www.adobe.com/products/xmp/
[40] OpenOffice-Formatvorlagen: http://www.ooowiki.de/FormatVorlagen




