

Um schnell ein Foto einzuscannen, reichen Programme wie XSane völlig aus. Ein mehrseitiges Dokument als PDF-Datei speichern können Sie damit aber nicht. Hier hift gscan2pdf.
Wer im Büro einen modernen Kopierer stehen hat, schätzt sicher die Scan-to-Mail-Funktion: Sie legen einen Stoß Papiere in den Einzugsschacht des Kopierers, wählen Ihre E-Mail-Adresse und drücken auf die Scantaste. Dann zieht das Gerät Seite für Seite aus dem Stapel ein, erzeugt eine PDF-Datei und schickt Ihnen das Resultat per E-Mail. Alternativ legen solche Geräte die PDF-Datei lokal (auf der Kopiererfestplatte) ab und erlauben im lokalen Netz den Zugriff via FTP oder über eine Windows-Freigabe.
Zu Hause werden Sie ein solches Gerät in der Regel nicht verfügbar haben, weil diese Profikopierer in einer eigenen Preisklasse spielen, die private Budgets sprengt; außerdem sind sie nicht gerade klein und passen schon wegen der nötigen Stellfläche kaum in ein normales Home-Office.
Einfache Scanner oder Scanner-Drucker-Kombigeräte für den Privatgebrauch sind hier üblicher, aber ihnen fehlt meist die Scan-to-Mail-Funktion. Doch auch mit solchen Geräten können Sie komfortabel mehrseitige Dokumente zu PDF-Dateien verarbeiten, wenn Sie gscan2pdf[1] installieren.
Installation
Unter Ubuntu und Kubuntu finden Sie das Programm im Standard-Repository, im Test unter Kubuntu holte die Paketverwaltung 256 MByte Software aus dem Internet. Unter OpenSuse 12.1 ist die Installation umständlich. In der Paketverwaltung müssen Sie zunächst ein zusätzliches Repository aktivieren:
- Starten Sie über Computer / Software installieren/entfernen die Paketverwaltung und rufen Sie darin den Menüpunkt Konfiguration / Repositories auf.
- Klicken Sie im sich öffnenden Fenster auf Hinzufügen, wählen Sie im nächsten Dialog oben den Eintrag Community/Gemeinschafts-Repositories und bestätigen Sie per Klick auf Weiter.
- Jetzt erscheint eine Liste von Repositories. Aktivieren Sie dort den Eintrag openSUSE BuildService – devel:languages:perl und richten Sie das Repo ein.
- Zurück in der Liste der aktivierten Repos klicken Sie erneut auf Hinzufügen, wählen diesmal aber die Option URL eingeben.
- Der folgende Dialog hat nur zwei Eingabefelder. Unter Name geben Sie z. B. gscan2pdf ein, unter URL die Adresse http://download.opensuse.org/repositories/home:/illuusio/openSUSE_12.1[2] und übernehmen auch diesen Eintrag.
Bei beiden Repos zeigt YaST einen Schlüssel an und bittet Sie, diesen zu akzeptieren. Nach dem Einrichten der beiden Repos können Sie in der Paketverwaltung das Programmpaket gscan2pdf suchen und installieren. Dabei landen auch die OCR-Programme Tesseract, gocr und cuneiform auf Ihrer Platte.
Die Ubuntu-Repositories enthalten noch die alte gscan2pdf-Version 0.9.32, unter OpenSuse arbeiten Sie bereits mit Version 1.0.4. Wir gehen in diesem Artikel davon aus, dass Ihr Scanner bereits korrekt funktioniert und Sie z. B. mit dem Programm xsane scannen können. Wenn das der Fall ist, sollte auch gscan2pdf auf Anhieb funktionieren.
Die Oberfläche
Starten Sie das Programm über Anwendungen / Grafik / gscan2pdf. Es öffnet sich ein leeres Fenster, in dem Sie später die einzelnen Seiten Ihres Dokuments betrachten können.
Für den Schnellstart klicken Sie das vierte (bzw. bei OpenSuse: das dritte) Icon von links (ein Scanner-Symbol) an. Darüber öffnen Sie den Scandialog, und gscan2pdf sucht zunächst nach einem Gerät, was einige Sekunden dauern kann. Wenn das Programm Ihren Scanner gefunden hat, erscheint dessen Bezeichnung rechts oben im Scandialog (Abbildung 1).
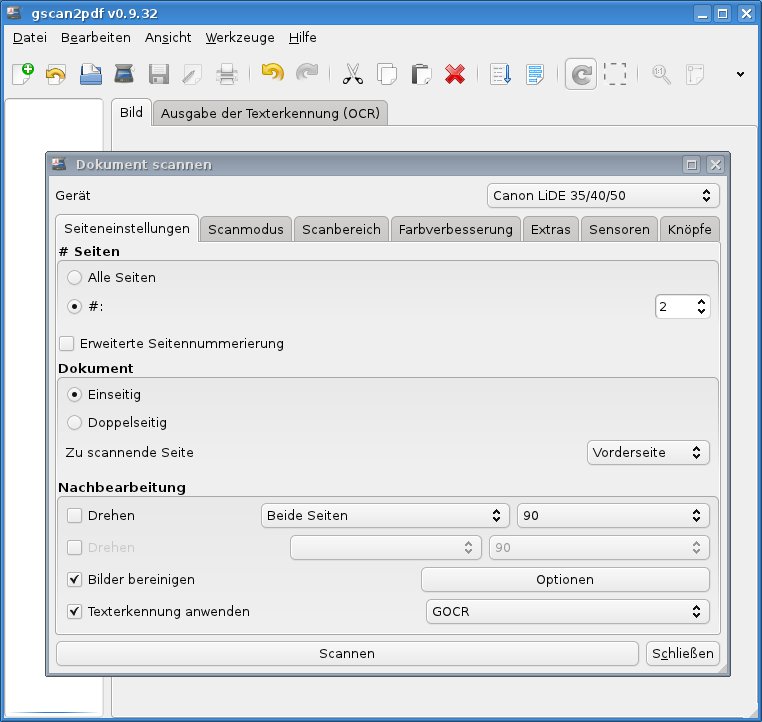
Abbildung 1: “gscan2pdf” hat einen Scanner gefunden und ist bereit.
Auf dem ersten Reiter Seiteneinstellungen geben Sie nun unter Seiten / #: an, wie viele Seiten Sie einscannen möchten. Vorsicht: Wenn Sie hier mehr als eine Seite einstellen und dann den Scanvorgang starten, fordert das Programm nicht zum Wechseln der Vorlage auf; Sie müssen also, während der Schlitten nach dem Scannen einer Seite auf die Ausgangsposition zurückfährt, schnell das nächste Blatt einlegen. Wer diesen Wechsel ausreichend flink durchführen kann, spart ein wenig Zeit und unnötige Mausklicks. Scanner mit automatischem Papiereinzug erleichtern die Aufgabe.
Kennen Sie die Anzahl nicht oder wollen nicht zählen, aktivieren Sie die Option Alle Seiten; auch das funktioniert nur mit einem automatischen Papiereinzug, der das Ende des Stapels erkennt. Bei einem normalen Gerät landen Sie über diese Einstellung in einer Endlosschleife, in welcher das Programm ohne Ende scannt. (Passiert Ihnen das aus Versehen, können Sie den Endlos-Scan aber abbrechen.)
Wollen Sie Stress beim Vorlagenwechsel vermeiden, übernehmen Sie als Seitenzahl immer den Vorgabewert 1. Nach dem Abschluss des Scanvorgangs bleibt der Scandialog geöffnet, so dass Sie einfach erneut auf Scannen klicken können, wenn Sie das nächste Papier auf das Glas gelegt haben. Sind alle Seiten erfasst, klicken Sie auf Schließen.
gscan2pdf zeigt nun links eine Übersicht der eingescannten Seiten (mit Vorschaubildern) und rechts die erste dieser Seiten in einer großen Darstellung an (Abbildung 2). Mit dem Mausrad (und gedrückter Strg-Taste) können Sie in die angezeigte Seite rein- oder aus ihr herauszoomen, halten Sie die linke Maustaste gedrückt, können Sie im Zoom-Modus den sichtbaren Bereich verschieben.
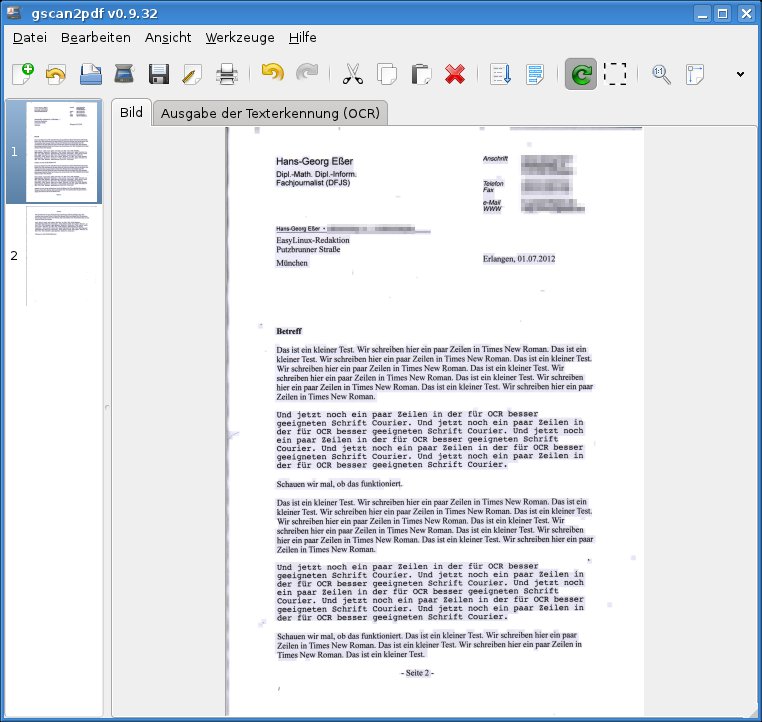
Abbildung 2: Nach dem Scannen können Sie prüfen, ob die Seiten vernünftig aussehen.
OCR
Nach dem Scannen versucht gscan2pdf automatisch, mit Hilfe einer OCR-Anwendung den Text auf den Seiten zu erkennen. Dabei unterstützt das Programm mehrere OCR-Tools: gocr, Tesseract und cuneiform. Für die letzten beiden können Sie zudem die Sprache des Dokuments einstellen, dann werden beim Scannen sprachspezifische Wörterbücher verwendet. Im Test stürzte cuneiform unter Kubuntu allerdings regelmäßig ab, unter OpenSuse funktionierte das Tool und lieferte gute Ergebnisse. Wenn Tesseract unter Ubuntu noch nicht installiert ist, spielen Sie die Pakete tesseract-ocr und tesseract-ocr-deu ein.
Wechseln Sie nach dem Scannen auf den Reiter Ausgabe der Texterkennung (OCR), um den erkannten Text zu lesen (Abbildung 3). Die Ergebnisse der Zeichenerkennung lassen allerdings im Vergleich zu Profilösungen wie der von Adobe Acrobat (unter Windows oder Mac OS) zu wünschen übrig. Tesseract mit deutschem Wörterbuch arbeitete deutlich besser als gocr und erkannte z. B. Umlaute und das scharfe S (ß), was gocr manchmal nicht gelang. Auch optisch konnten die Resultate nicht erzeugen: gscan2pdf versucht sich an diversen Bildverbesserungen, um die Qualität des OCR-Durchlaufs zu erhöhen, das führte im Test aber dazu, dass alle Textbereiche im Dokument schwarz auf hellgrauem Hintergrund erschienen, während Scanbereiche ohne Text weiß wurden (Abbildung 4). Dieser Effekt trat nur in der älteren gscan2pdf-Version von Ubuntu auf.
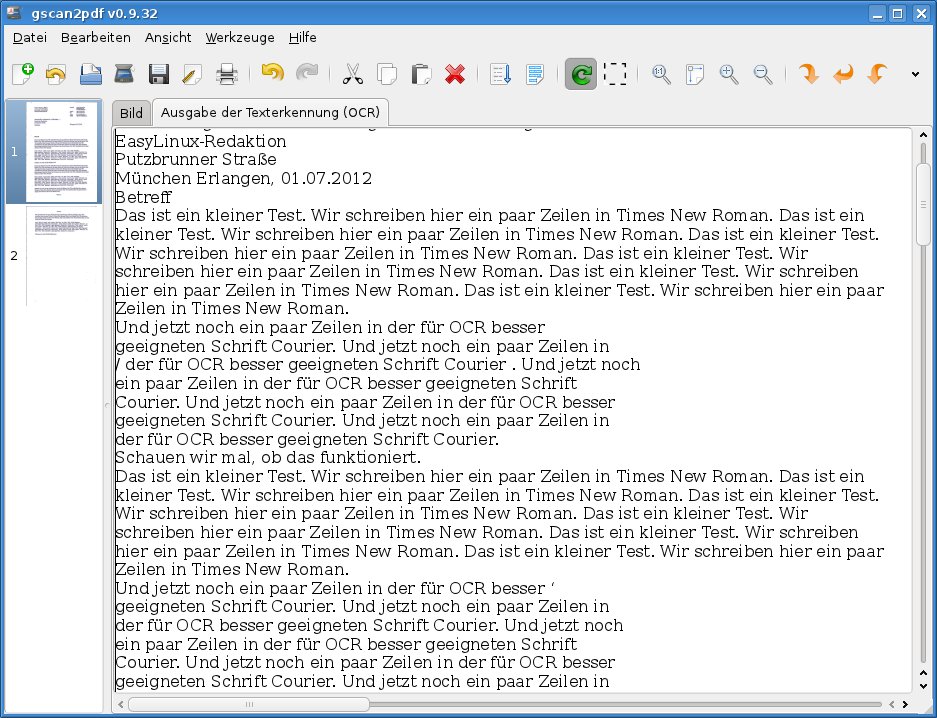
Abbildung 3: Ein Beispieldokument mit Text in Times und Courier hat das OCR-Programm Tesseract gut erkannt. Mit einem Arial-Font gab es größere Probleme.

Abbildung 4: Einen lästigen Schatten bastelt die Ubuntu-Version von “gscan2pdf” um alle Textbereiche.
Für die PDF-Konvertierung rufen Sie den Menüpunkt Datei / Speichern auf und entscheiden sich für das PDF-Format – fertig.
Kein Acrobat-Ersatz
Wer das OCR-Feature von Adobe Acrobat kennt, wird von gscan2pdf enttäuscht sein: Acrobat verbindet die Grafik mit dem OCR-Anteil, so dass Sie das damit erzeugte PDF-Dokument später durchsuchen können und die Treffer im Dokument hervorgehoben werden. gscan2pdf integriert einfach den erkannten Text links oben in winziger, unsichtbarer Schrift in der PDF-Seite. Damit können Sie dann zwar nach Begriffen suchen und finden die richtigen Seiten, nicht aber die Trefferpositionen auf einer Seite. Die unter OpenSuse installierte, neuere Version lieferte hier etwas bessere Ergebnisse, blieb aber immer noch weit hinter der Acrobat-Lösung zurück.
Komfortabler als manuelles Zusammenbasteln mehrerer eingescannter Bilddateien zu einem PDF-Dokument ist die Arbeit mit gscan2pdf aber allemal: Wenn die OCR-Funktion nicht so wichtig ist, leistet das Programm ansonsten gute Arbeit.
Infos
[1] gscan2pdf: http://gscan2pdf.sourceforge.net/
[2] OpenSuse-Repo: http://download.opensuse.org/repositories/home:/illuusio/openSUSE_12.1

