

Über die Kommandozeile flink in komprimierten Dateien und Archiven zu suchen, spart viel Zeit. Die richtigen Tools dazu bringt praktisch jedes Linux-System von Haus aus mit.
Um Platz für aktuell nicht mehr benötigte Daten zu schaffen, bietet es sich an, einzelne Dateien zu komprimieren oder diese zu einem komprimierten Archiv zusammenzufassen (siehe Kasten “Komprimierte Datei versus Archiv”). Das Sichern erfolgt danach meist auf einem externen Medium, beispielsweise auf einer DVD, einer weiteren Festplatte oder einem Server im Rechenzentrum.
Komprimierte Datei versus Archiv
Die in diesem Artikel vorgestellten Programme fallen in einigen Fällen in eine der beiden Kategorien Datenkompression und Erzeugen von Archiven, andere kombinieren beides. Zur ersten Kategorie zählen die Tools XZ, Gzip und Bzip2; die zweiten Kategorie besetzt Tar. Zip, 7-zip und Rar verbinden beide Techniken.
Um die mit Gzip, Bzip2 und XZ komprimierten Tar-Archive zu verarbeiten, müssen die Komprimierungsprogramme als Helfer installiert sein. Tar ruft diese direkt auf. Generell erkennen Sie leicht an der Dateiendung, um welche Art von Archiv oder Kompression es sich handelt. Die Tabelle “Dateiendungen” gibt Aufschluss über gängige Formate.
7-zip erweist sich als Spezialfall: Dateien dieses Typs haben üblicherweise die Endung .7z. Die passenden Tools dazu heißen 7z, 7za und 7zr. Der Unterschied liegt darin, welche Formate (zum Teil inklusive Gzip, Bzip2, XZ, LZMA, Rar oder Zip) das Programm beherrscht. Die Namen der Pakete unter Debian und Ubuntu sind p7zip (7zr), p7zip-full (7z, 7za) und p7zip-rar (Rar-Plugin für 7z).
Dateiendungen
| Typ | Endung |
|---|---|
| Komprimierte Dateien | |
| Gzip | .gz |
| Bzip2 | .bz2 |
| XZ | .xz |
| Archive | |
| Zip | .zip |
| 7zip | .7z |
| Rar | .rar |
| Tar | .tar |
| Tar+Gzip | .tar.gz |
| Tar+Bzip2 | .tar.bz2 |
| Tar+XZ | .tar.xz |
Erst zu einem späteren Zeitpunkt taucht meist die spannende Frage auf, wie Sie etwas in diesen komprimierten Dateien und Archiven wiederfinden. Meist kommen einem nur noch Fragmente in den Sinn – ein Teil des Dateinamens, der ungefähre Zeitraum der letzten Bearbeitung oder ein Ausschnitt des Inhalts.
Um die Datei oder das Archiv einfach auszupacken, helfen die Kommandos aus der Tabelle “Archive entpacken”. Danach prüfen Sie, ob die gewünschten Inhalte vorliegen. Dieses Vorgehen erweist sich bei kleinen Datenmengen durchaus als praktikabel.
Bei größeren Datenmengen stößt es aber schnell an seine Grenzen, beispielsweise, wenn für die ausgepackten Daten nicht genügend Speicherplatz bereitsteht. Deshalb haben findige Entwickler einfachere und effizientere Wege zum Durchsuchen der Archive ersonnen.
Archive entpacken
| Typ | Kommando |
|---|---|
| Komprimierte Dateien | |
| Gzip | gunzip Datei.gz, unp Datei.gz |
| Bzip2 | bunzip2 Datei.bz2, unp Datei.bz2 |
| XZ | unxz Datei.xz, unp Datei.xz |
| Archive | |
| Zip | unzip Archiv.zip, unp Archiv.zip |
| 7zip | 7z e Archiv.7z, unp Archiv.7z |
| Rar | unrar e Archiv.rar, unp Archiv.rar |
| Tar | tar -xf Archiv.tar, unp Archiv.tar |
| Tar+Gzip | tar -xzf Archiv.tar.gz, unp Archiv.tar.gz |
| Tar+Bzip2 | tar -xjf Archiv.tar.bz2, unp Archiv.tar.bz2 |
| Tar+XZ | tar -xJf Archiv.tar.xz, unp Archiv.tar.xz |
Ohne Auspacken
Im Fall einer komprimierten Datei entspricht der Dateiname in der Regel dem Namen der gepackten Datei. Ein Archiv dagegen fasst unter einem eigenen Dateinamen mehrere Dateien zusammen. Die einzelnen Programme bieten jedoch eine Option, über die Sie die Liste im Archiv ausgeben. Mit den Kommandos aus Tabelle “Inhalt auflisten” durchsuchen Sie das Archiv nur nach Dateinamen und packen es nicht auf den Datenträger aus.
Inhalt auflisten
| Typ | Kommando |
|---|---|
| Komprimierte Dateien | |
| Gzip | gzip -l Datei.gz |
| Bzip2 | keine Option |
| XZ | xz -l Datei.xz |
| Archive | |
| Zip | unzip -l Archiv.zip |
| 7zip | 7z l Archiv.7z |
| Rar | unrar l Archiv.rar |
| Tar | tar -tf Archiv.tar |
| Tar+Gzip | tar -tzf Archiv.tar.gz |
| Tar+Bzip2 | tar -tjf Archiv.tar.bz2 |
| Tar+XZ | tar -tJf Archiv.tar.xz |
Die Dateiliste des Archivs filtern Sie bei Bedarf mit einem Grep-Kommando, indem Sie den gewünschten Namen als Muster verwenden. Beide Kommandos verbinden Sie dazu über eine Pipe miteinander. Die ausgegebene Dateiliste beinhaltet in jeder Zeile nur einen Dateinamen. Daher gibt das Grep-Kommando nur die Zeilen zurück, auf die das Suchmuster des Dateinamens passt. Drei Varianten von Grep helfen dabei [1]:
grep -F(alternativ:fgrepodergrep --fixed-strings): Mit diesem Aufruf extrahieren Sie ausschließlich exakte Vorkommen einer Zeichenkette im Datenstrom. Sonderzeichen ignoriert das Tool.grep -G(alternativ:grep --basic-regexp): Grep ohne Auswahl des Suchmuster-Typs nutzt eine einfachere Variante von regulären Ausdrücken und nimmt das Suchmuster dementsprechend nicht so wortwörtlich wie Fgrep. Es interpretiert verschiedene Sonderzeichen (Wildcards), beispielsweise*als Ausdruck für beliebig viele beliebige Zeichen. Diese einfachen regulären Ausdrücke sind ähnlich (aber nicht identisch) zu den Wildcards, die Sie in der Shell zum Auswählen von Dateien nutzen.egrep(alternativ:grep -Eodergrep --extended-regexp): Die “extended regular expressions”, also erweiterte reguläre Ausdrücke, entsprechen in etwa den Suchmustern in anderen Kommandozeilenprogrammen, wie zum Beispiel in Sed und Awk, im Editor Vi und im Betrachter Less.
Grep früher und heute
In Debian-Releases bis zur Version 4.0 (“Etch”) waren Fgrep und Egrep Verweise auf Grep. Diese reichten den Aufruf an Grep mit der entsprechenden Option und den Parametern weiter, grep -F für fgrep und grep -E für egrep. Das erfolgte über ein Shell-Skript:
$ cat /bin/fgrep
#!/bin/sh
exec grep -F ${1+"$@"}
Mittlerweile hat sich das geändert: Die Kommandos liegen bei den aktuelleren Debian-Versionen als eigenständige Binaries vor. Scientific Linux und Ubuntu handhaben das ähnlich wie Debian, der Red-Hat/Fedora-Ableger CentOS hingegen nicht. Listing 1 zeigt, dass unter CentOS 5.5 Fgrep und Egrep auf Grep linken – zu erkennen am l in den Benutzerrechten und dem Verweis in der rechten Spalte.
Die beiden Kommandos Fgrep und Egrep sind zudem als veraltet gekennzeichnet (siehe dazu die Manpage der Kommandos) und nur aus historischen Gründen noch in dieser Form enthalten. Es steht daher zu erwarten, dass diese Kommandos in der Zukunft entfallen und es stattdessen Grep mit der entsprechenden Option aufzurufen gilt. Ein genauer Termin für diese doch recht gravierende und umstrittene Änderung steht jedoch noch nicht fest.
Listing 1
$ ls -l $(which egrep fgrep grep) lrwxrwxrwx 1 root root 4 22. Okt 2010 /bin/egrep -> grep* lrwxrwxrwx 1 root root 4 22. Okt 2010 /bin/fgrep -> grep* -rwxr-xr-x 1 root root 85060 26. Sep 2009 /bin/grep*
Für ein tar.gz-Archiv liefert die kurze Befehlsfolge aus Listing 2 erste Treffer. Zuerst durchsucht Tar das angegebene Archiv und schickt das komplette Inhaltsverzeichnis auf die Standardausgabe in eine Pipe. Aus dieser erhält Fgrep die Eingabedaten und filtert diese nach dem angegebenen Muster – hier dem Dateinamen.
Listing 2
$ tar -tzf Archiv.tar.gz | fgrep --color Dateiname
Die Option --color wäre für den Aufruf nicht unbedingt notwendig. Sie dient nur der besseren Übersicht in der Ausgabe und sorgt dafür, dass Fgrep den Suchtreffer in der Ausgabe farbig hervorhebt. Für komplexere Suchen mit Sonderzeichen eignen sich Grep und Egrep, zum Beispiel, wenn der genaue Dateiname unklar ist und Sie über ein Muster suchen möchten.
Die Befehlsfolge aus Listing 3 entspricht jener aus Listing 2, nur dass hier ein Bzip2-komprimiertes Archiv zum Einsatz kommt. Mit Hilfe von Egrep und einem regulären Ausdruck als Muster filtern Sie alle Dateinamen aus dem Inhaltsverzeichnis des Archivs heraus, die auf das Muster passen.
Listing 3
$ tar -tjf archiv.tar.bz2 | egrep --color "^rechnung.1[5-7]\.pdf"
Das Sonderzeichen ^ im Suchmuster legt fest, dass die Zeichenkette rechnung nur dann einen Suchtreffer ergeben darf, wenn sie am Zeilenanfang steht. Auf ein beliebiges Zeichen (.) folgen zwei Ziffern, wobei die erste Ziffer mit 1 vorgegeben ist, wohingegen die zweite Ziffer aus dem Bereich von 5 bis 7 stammen darf. Das Musterende bildet ein Punkt, den Sie mit einem Backslash schützen, da Grep ihn sonst als Sonderzeichen interpretiert, und die Zeichenkette pdf. Gültige Treffer für dieses Muster wären zum Beispiel rechnung015.pdf, rechnung817.pdf, rechnung-16.pdf und rechnung-16.pdf.bak.
Kennen Sie von der gesuchten Datei nur das ungefähre Datum der letzten Änderung, wählen Sie einen anderen Weg: Die Tar-Option -v zeigt ausführliche Informationen zu den archivierten Dateien an, also Zugriffsrechte, Eigentümer und Gruppe, Größe, Modifikationsdatum sowie den Dateinamen. Um eine Liste aller Dateien zu erhalten, die einen Zeitstempel vom 11., 12., 13., 21., 22. oder 23. Dezember 2011 besitzen, hilft analog zu obigem Beispiel der Aufruf aus Listing 4.
Listing 4
$ tar -tjvf Archiv.tar.bz2 | egrep --color "2011-12-[12][1-3]"
Egrep fungiert hierbei als Filter der Ausgabe von Tar. Nur die Zeilen, die die Zeichenkette 2011-12-11, 2011-12-12, 2011-12-13, 2011-12-21, 2011-12-22 oder 2011-12-23 enthalten, landen im Ergebnis. Alle Zeichen, die in eckigen Klammern stehen, behandelt das Tool beim Mustervergleich als Alternativen. Hier ergibt sich entweder Ziffer 1 oder 2, gefolgt von der Ziffer 1, 2 oder 3. Mit dieser kompakten Schreibweise des Datums formulieren Sie alle sechs Kombinationen, ohne sie auszuschreiben. Selbst in dieser überschaubaren Situation sparen Sie so bereits Schreibarbeit.
Möchten Sie das Gegenteil erreichen – also alles ausgeben mit Ausnahme dessen, was dem Muster entspricht – verwenden Sie zusätzlich die Option -v (Listing 5). Damit enthält die Ausgabe zwar Dokumente mit dem Muster 2011-11-30 oder 2011-12-24, aber nicht 2011-12-13.
Listing 5
$ tar -tjvf Archiv.tar.bz2 | grep -E -v "2011-12-[12][1-3]"
Komprimierte Dateien
Der erste Aufruf für die Suche in einer komprimierten Datei folgt dem bisher bekannten Muster – Auspacken der Datei auf die Standardausgabe (Tabelle “Archive auspacken”), anschließendes Filtern mittels Grep. Listing 6 zeigt ein Beispiel mit einer Bzip2-komprimierten Datei.
Listing 6
$ bzip2 -dc Datei.bz2 | grep -F "Suchmuster"
Grep gibt alle Zeilen auf die Standardausgabe aus, die auf das Suchmuster passen und mindestens einen Treffer beinhalten. Bei Binärdateien liefert es die Mitteilung Übereinstimmungen in Binärdatei (Standardeingabe).
Interessieren Sie die Zeichenketten, die einen Treffer erzeugt haben, hilft die Option -o. Damit gibt Grep diese zeilenweise aus. Die Anzahl der Treffer ermitteln Sie, indem die Ausgabe über eine Pipe an das Kommando wc -l weiterreichen (Abbildung 1).
Abbildung 1: Über eine Kette von Kommandos ermitteln Sie ganz leicht die Anzahl der Fundstellen für einen String in einer komprimierten Datei.
Die Tabelle “Archive auspacken” enthält eine dritte Spalte mit alternativen Kommandos, die exakt das gleiche wie jene in Spalte 2 bewirken. Viele Werkzeuge bringen Varianten mit, die sich namentlich an das Tool Cat anlehnen. Letzteres gibt den Inhalt einer Datei auf der Standardausgabe aus, wie zum Beispiel xzcat den entpackten Inhalt einer XZ-komprimierten Datei.
Das Programm Ucat gehört zum Unp-Paket [2]. Dies enthält kleine Perl-Skripte, die je nach Format den richtigen Befehl zum Extrahieren ausführen. Gemäß Quellcode unterstützt die Software beispielsweise die Formate Gzip, Tar.Gzip, Bzip2, Tar.bzip2, XZ, Tar.XZ, LZip, Tar.LZip und 7zip. Als Backend nutzt Ucat die entsprechenden Kommandozeilen-Tools, was voraussetzt, dass Sie diese installiert haben.
Archive auspacken
| Typ | Kommando | Alternativkommando |
|---|---|---|
| Komprimierte Dateien | ||
| Gzip | gzip -dc Datei.gz |
zcat Datei.gz |
| Bzip2 | bzip2 -dc Datei.bz2 |
bzcat Datei.bz2 |
| XZ | xz -dc Datei.xz |
xzcat Datei.xz |
| Archive | ||
| Zip | unzip -p Archiv.zip |
ucat Archiv.zip |
| 7zip | 7z e Archiv.7z -so |
ucat Archiv.7z |
| Rar | unrar p Archiv.rar |
ucat Archiv.rar |
| Tar | tar -Of Archiv.tar |
ucat Archiv.tar |
| Tar+Gzip | tar -xOzf Archiv.tar.gz |
ucat archiv.tar.gz |
| Tar+Bzip2 | tar -xOjf Archiv.tar.bz2 |
ucat Archiv.tar.bz2 |
| Tar+XZ | tar -xOJf Archiv.tar.xz |
ucat Archiv.tar.xz |
Die Komprimierungsprogramme bringen eigene Werkzeuge zum Suchen mit. Gzip enthält Zgrep, Zfgrep und Zegrep. Bei allen drei Programmen handelt es sich um Shell-Skripte, wobei Zgrep recht umfangreich ausfällt und die eigentliche Arbeit leistet. Zfgrep und Zegrep bestehen aus wenigen Zeilen und rufen lediglich Zgrep mit den Optionen -F beziehungsweise -E auf.
Bei Bzip2 und XZ kommt das selbe Prinzip zum Tragen: Hier heißen die Werkzeuge jeweils Bzgrep, Bzfgrep und Bzegrep beziehungsweise XZgrep, XZfgrep und XZegrep. Obiges Beispiel zur Suche in der Bzip2-Datei ließe sich daher vereinfachen, ähnliches gilt für Aufrufe mit Zgrep und XZgrep.
Wie in Abbildung 2 zu sehen, sucht der Helfer alle Einträge in der Datei, die eine Zeichenkette enthalten, welche mit M beginnt, gefolgt von zwei beliebigen Zeichen und darauf der Zeichenkette er.

Abbildung 2: Bzegrep vereinfacht die Suche in gepackten Archiven.
Für die Suche in Zip-Archiven existiert Zipgrep. Das Shell-Skript gehört zum Unzip-Paket. Bei der Mustersuche greift es auf Unzip und Egrep zurück. Gemäß Manpage reicht Zipgrep alle Optionen und Parameter durch, die Egrep kennt. Im Test stellte sich jedoch heraus, das Zipgrep etwas nachlässig programmiert ist, was dazu führt, dass es Langoptionen ignoriert [3].
Für jeden Treffer gibt das Programm den Dateinamen aus, gefolgt von einem Doppelpunkt und nachfolgend der Zeile mit der passenden Zeichenkette. Wünschen Sie ein farbiges Hervorheben der Treffer, gelingt das derzeit nur über einen kleinen Umweg, da Zipgrep sich an der bekannten Grep-Option --color verschluckt. Deswegen bleibt als Ausweg nur die Kombination von beiden Tools (Abbildung 3). Listing 7 zeigt, wie Sie die beiden Kommandos zu einer Kette verbinden.
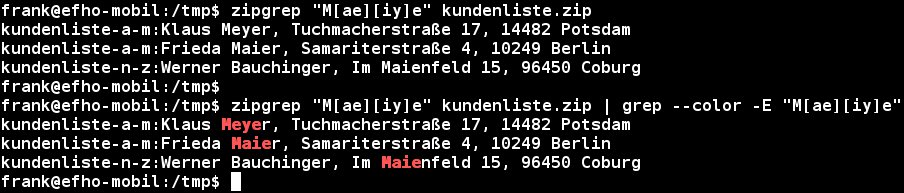
Abbildung 3: Ein farbiges Hervorheben der Treffer gelingt im Fall von Zipgrep nur durch nochmaliges Kombinieren mit Grep, da das eigentliche Tool Optionen für Grep verschluckt.
Listing 7
$ zipgrep "[Pp]reis.*pdf" archiv.zip | grep --color -E "[Pp]reis.*pdf"
Suche in Archiven
Bei Archiven hilft meist nur ein Abgleich der Inhalte mit einem Muster weiter, besonders, wenn Sie weder den genauen Namen noch das Änderungsdatum der gesuchten Datei kennen. Die Tar-Optionen --to-stdout beziehungsweise -O leiten den Inhalt einer Datei auf die Standardausgabe. Über eine Pipe filtern Sie dann den Datenstrom ganz leicht mittels Grep (Listing 8).
Listing 8
$ tar -xOvf archiv.tar | grep -F suchstring
Tar verarbeitet das Archiv dabei Datei für Datei. Die Option -v bewirkt, dass das Programm Daten über zwei Kanäle ausgibt – der Inhalt landet in der Standardausgabe (stdout), die Dateinamen auf der Standardfehlerausgabe (stderr). Ein Terminal führt beide Kanäle zusammen, sodass die Zeilen jeweils nacheinander erscheinen. Ohne die Option -v erfolgt keine Ausgabe der Dateinamen über die Standardfehlerausgabe.
Das Suchergebnis besteht aus einer Liste von Dateinamen aus dem Tar-Archiv und den Treffern. Ein Zuordnen zwischen Dateiname und Treffer findet nicht statt (Abbildung 4). Für ein verständlicheres Suchergebnis braucht es einen etwas tieferen Griff in die Trickkiste der Abteilung Shell-Programmierung, wie Listing 9 zeigt.
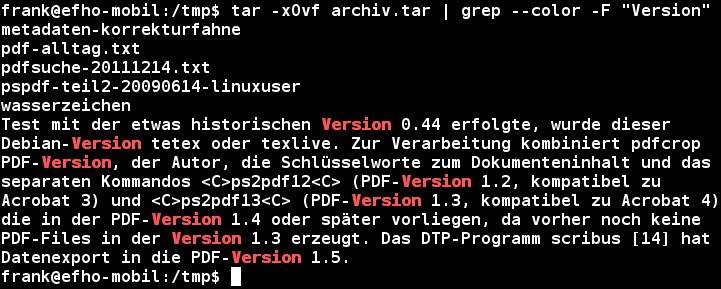
Abbildung 4: Dateiliste und Suchtreffer mischen sich bei der Suche nach Dateiinhalten aus Tar-Archiven.
Listing 9
for datei in $(tar -tf archiv.tar);
do
suchtreffer=$(tar -xOf archiv.tar "$datei" | grep -F suchstring) && echo "$datei:";
echo "$suchtreffer" | grep --color -F suchstring;
echo "";
done
Die Ausgabe des ersten Tar-Kommandos – die Liste der Dateien im Archiv – landet in der Variable datei. Dabei teilt die Shell die Ausgabe an den Leerzeichen. Dateinamen, die solche enthalten, führen zu Fehlern beim nachfolgenden Verarbeiten innerhalb der Schleife. Diese arbeitet sich schrittweise durch die einzelnen Werte.
Bei jedem Schleifendurchlauf erfolgt ein Mustervergleich und dessen Auswertung. Dazu speichert das Skript zuerst in der Variable suchtreffer das Ergebnis des Tar/Grep-Kommandos, wobei der Tar-Befehl nur die Datei aus dem Archiv auspackt und den Inhalt ausgibt. Eine Pipe leitet den Datenstrom weiter zum Filtern an Grep.
Im nächsten Schrritt nutzt das Skript den Rückgabewert des grep-Kommandos aus. Falls grep einen Suchtreffer gelandet hat, liefert es als Rückgabewert den Wert 0. Der Operator && sorgt dafür, dass das Skript diesen Wert evaluiert und die nachfolgenden echo-Befehle nur ausführt, falls Grep die als Rückgabewert 0 meldet (“erfolgreich ausgeführt und mit Treffer”).
Als Ausgabe erscheinen der Dateiname und die Zeile mit dem farbig hervorgehobenen Suchtreffer. Die Werte finden sich in den beiden Variablen datei und suchtreffer, deren Inhalt auf der Standardausgabe landet. Das Semikolon zwischen den echo-Befehlen bewirkt einen Zeilenumbruch, der letzte echo-Aufruf eine Leerzeile zwischen den Ausgaben, was für etwas mehr Lesbarkeit sorgt (Abbildung 5).
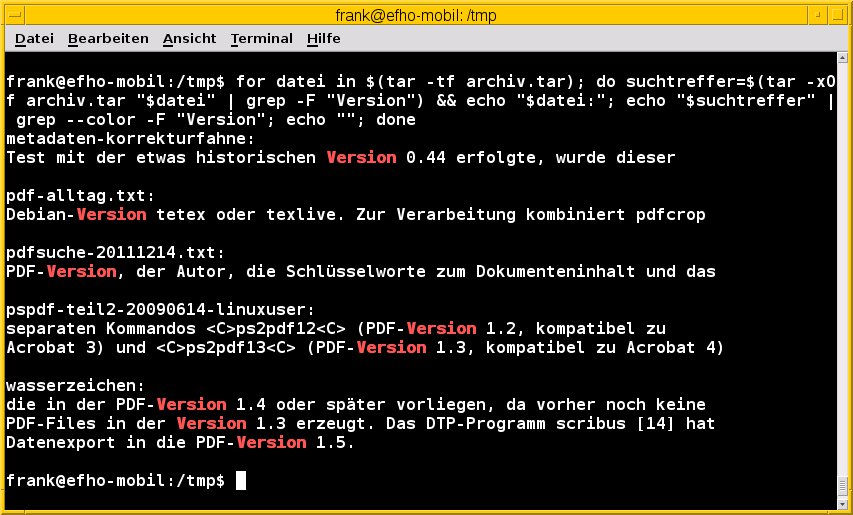
Abbildung 5: Suchtreffer und zugeordnete Dateien im Überblick.
In den Beispielen bestünde die Möglichkeit, die Befehl grep -F durch eine Mustersuche mit grep -E in Kombination mit einem regulären Ausdruck auszutauschen – je nachdem, wie umfangreich und flexibel die Recherche ausfällt. Das beschriebene Vorgehen funktioniert auch bei komprimierten Tar-Archiven. Dazu geben Sie in den Aufrufen die entsprechende Option für das Komprimierungsformat an, beispielsweise -z für Gzip-komprimimierte Dateien.
Kombinationen
Für Rar- und 7zip-Archive existiert keine spezifische Grep-Version. Hier hilft es wieder, zwei Befehle miteinander zu kombinieren: unrar beziehungsweise 7z einerseits und grep andererseits. Bei Unrar nutzen Sie die Option p für “print”. Damit weisen Sie das Programm an, den Inhalt der aus dem Archiv entpackten Dateien auf die Standardausgabe auszugeben. Bei 7zip sind es zwei Optionen: Mit -e extrahieren Sie die Dateien, und über -so erfolgt die Ausgabe. Über eine Pipe filtern Sie dann mittels Grep die Daten (Listing 10).
Listing 10
$ unrar p archiv.rar | grep --color -E "[Pp]reis.*pdf" $ 7z e archiv.7z -so | grep --color -E "[Pp]reis.*pdf"
Geschwindigkeit
An dieser Stelle erhebt sich die spannende Frage nach der Trefferquote und der Zeit, nach der das Suchergebnis feststeht. Obwohl für bestimmte Formate spezielle Werkzeuge existieren, arbeiten diese nicht automatisch besser – die Standard-Tools sind vielfach bis ins letzte Quäntchen optimiert.
Für einen Vergleich mit halbwegs plausiblen Werten stand im Test eine Datei mit 12 MByte ASCII-Text bereit. Diese wurde mit den jeweiligen Programmen komprimiert und dann darin gesucht – einmal über die Standardausgabe und einmal mit den formatspezifischen Suchprogrammen. Die Tabelle “Tools im Test” zeigt die ermittelten Werte, Abbildung 6 stellt diese grafisch gegenüber.
Tools im Test
| Methode | Kommandoaufruf | Zeit (real) | Zeit (user) | Zeit (sys) |
|---|---|---|---|---|
| Unkomprimiert | time grep --color -E "[Pp]reis.+pdf" testliste |
0,040s | 0,024s | 0,016s |
| Bzegrep | time bzegrep --color "[Pp]reis.+pdf" testliste.bz2 |
0,824s | 0,832s | 0,036s |
| Bzip2+Grep | time bzip2 -dc testliste.bz2 | grep --color -E "[Pp]reis.+pdf" |
0,826s | 0,832s | 0,036s |
| Zegrep | time zegrep --color "[Pp]reis.+pdf" testliste.gz |
0,189s | 0,196s | 0,024s |
| Gunzip+Grep | time gunzip -dc testliste.gz | grep --color -E "[Pp]reis.+pdf" |
0,173s | 0,184s | 0,016s |
| Xzgrep | time xzgrep --color -E "[Pp]reis.+pdf" testliste.xz |
0,113s | 0,100s | 0,044s |
| Xz+Grep | time xz -dc testliste.xz | grep --color -E "[Pp]reis.+pdf" |
0,097s | 0,108s | 0,020s |
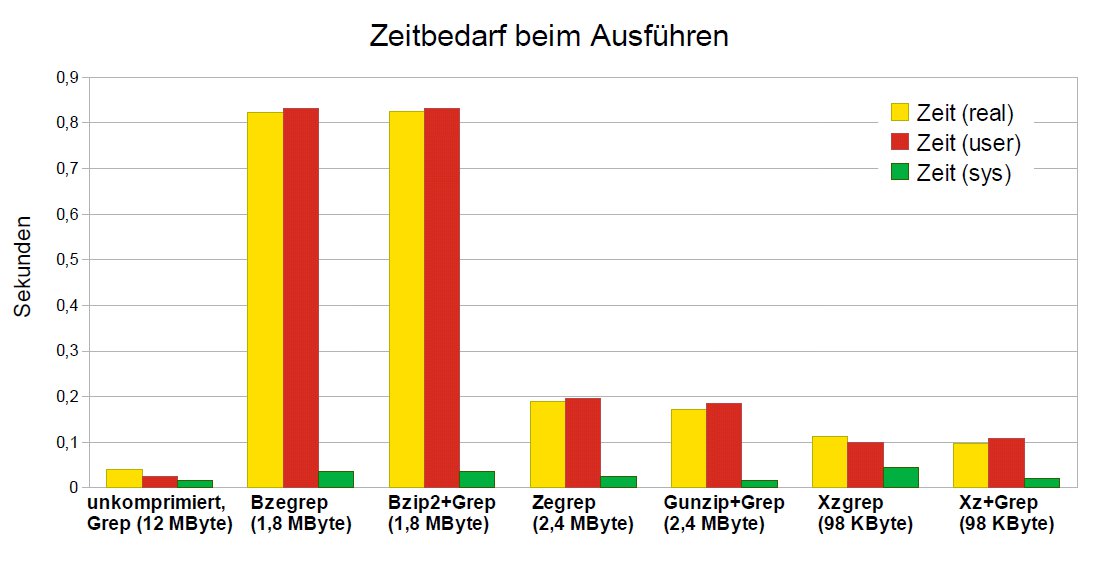
Abbildung 6: Die gemessenen Zeiten für die Kommandoaufrufe differieren teils deutlich.
Vorneweg: Die Liste der Treffer war im Test bei allen Programmen identisch und vollständig. Hingegen zeigen sich bei den gemessenen Zeiten für den Mustervergleich starke Unterschiede: Für jedes Komprimierungsformat existiert ein spezifisches Zeitverhalten. Am wenigsten Zeit benötigt XZ, Bzip2 arbeitet hingegen am längsten.
Abbildung 6 stellt die gemessenen Zeiten bei der Suche in den Textdaten dar. Die erste Säule zeigt die Suche mit Grep auf den unkomprimierten Daten (12 MByte). Die nachfolgenden, jeweils benachbarten Säulen zeigen die Dauer für einen spezifischen Suchweg – Säule 2 und 3 für Bzip2 (1,8 MByte Daten), Säule 4 und 5 für Gzip (2,4 MByte) und Säule sechs und sieben für Xz (98 KByte).
Hier fällt auf, dass sich jeder Suche eine spezifische Dauer zuordnen lässt. Dabei liegt die Suche über die Standardausgabe stets in der gleichen Klasse wie das formatspezifische Programm.
Unter Berücksichtigung der Kompressionsstärke gebührt dem XZ-Format die Ehre des Siegers. Im Vergleich zu den anderen Werkzeugen komprimiert dieses Tool sehr stark. Da es nur 98 KByte an Daten von der Festplatte zu lesen braucht, verringert sich der Gesamtaufwand für die Suche. Das Auspacken und Durchsuchen geschieht vollständig im RAM und verursacht daher die geringste Verzögerung.
Fazit
Archive und komprimierte Daten zu durchsuchen gelingt relativ problemlos, sofern Sie die verschiedenen Werkzeuge geschickt miteinander kombinieren. Das setzt aber die genaue Kenntnis der jeweiligen Optionen und Parameter voraus. Nutzen Sie die speziellen Tools aus den Paketen der einzelnen Archiv- und Komprimierungsprogramme, verringert sich der Aufwand etwas. Qualitativ ließ sich im Vergleich zu den klassischen Shell-Kommandos kein Unterschied feststellen.
Die Unterschiede in Bezug auf die Geschwindigkeit treten bei größerern Datenmengen vermutlich noch deutlicher hervor. Ob das im Alltagsgebrauch eine wesentliche Rolle spielt, hängt im Einzelfall von den archivierten Daten und deren Mengen ab. Mit Ausnahme von Zipgrep erfüllt jedes der vorgestellten Werkzeuge die Erwartungen.
Welche Kommandosequenz Sie letztendlich im Alltag einsetzen, hat oft einen ganz profanen Grund – gibt es das Paket für die genutzte Distribution überhaupt, ist es auch installiert? Weiterhin spielen die Lesbarkeit eines Kommandos und die Bequemlichkeit des Anwenders einen großen Einfluß bei der Nutzung. Verkürzte Schreibweisen sparen Zeit bei der Eingabe und verringern die Fehlerrate beim Einsatz.
Für andere Dateiformate existieren ebenfalls Grep-ähnliche Werkzeuge, unter anderem für PDF-Dokumente (pdfgrep) [4], Audiodaten (taggrepper), Prozesslisten (pgrep) und Gnumeric-Rechenblätter (ssgrep). Eine erste Übersicht hat Axel Beckert in seinem Blog [5] zusammengetragen.
Danksagung
Die Autoren bedanken sich bei Maximilian Techter, Thomas Osterried und Thomas Winde für deren kritische Anmerkungen und Kommentare im Vorfeld dieses Artikels.
Infos
[1] Werkzeuge auf der Kommandozeile: http://www-user.tu-chemnitz.de/~hot/unix_linux_werkzeugkasten/weitere_kdozeilen_beispiele.html
[2] Unpack-Paket bei Debian: http://packages.debian.org/squeeze/unp
[3] Debian-Bug-Report zu Zipgrep: http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=652838
[4] Suche in Postscript und PDF: Frank Hofmann, “Gesucht, gefunden”, LU 02/2012, S. 82, https://www.linux-community.de/25255
[5] “Grep everything”: http://noone.org/blog/English/Computer/Shell/grep%20everything.futile





