

Postscript und PDF erzeugen kann jeder – darin suchen ist schon etwas schwieriger. Wir zeigen, welche Werkzeuge zum Erfolg verhelfen.
Daten nach bestimmten Inhalten zu durchsuchen und die Ergebnisse zu filtern, gehört zu den Aktivitäten, die im Alltag am häufigsten vorkommen. Für versierte Linux-Nutzer zählen die Grep-Kommandos zu den vertrauten Werkzeugen beim Filtern von Textdaten. Bei PDF und Postscript handelt es sich zwar im weitesten Sinne ebenfalls um Textformate, die jedoch einem spezifischen Schema für den Dokumentaufbau folgen (siehe Kasten “Postscript im Detail” und Kasten “PDF im Detail”).
Daher funktioniert die Suche in solchen Dokumenten nicht wie gewohnt. Das ist umso ärgerlicher, als Postscript und PDF zu den Dokumentformaten zählen, die in der IT-Welt mit am häufigsten zum Einsatz kommen – Postscript beispielsweise in der Druckvorstufe und PDF zum Dokumentenaustausch, dem Rechnungswesen und vermehrt in der digitalen Archivierung gemäß PDF/A-1a-Spezifikation [1].
Postscript im Detail
Bei Postscript handelt es sich um eine stackbasierte Programmiersprache [10], welche ein Postscript-Interpreter verarbeitet, den man Raster Image Processor (RIP) nennt. Viele Drucker verfügen über eine separate Platine mit einem Postscript-Controller und können daher Postscript-Dokumente direkt verarbeiten und ausdrucken.
Hinter Druckerverwaltungen wie lpr und dem Common Unix Printing System (CUPS) stecken Werkzeuge, die die Druckdaten für den Interpreter und das Ausgabesystem über Postscript Printer Descriptions (PPDs) entsprechend aufbereiten. Zur Vorschau der Druckdaten am Bildschirm dient Ghostscript [11]. Für Debian/Ubuntu finden sich CUPS-Filter und -Treiber sowie PPDs im Paket ghostscript-cups, der Software-RIP in den beiden Paketen ghostscript und ghostscript-x.
Der Aufbau einer Postscript-Datei folgt Prinzipien, wie sie auch bei der Programmierung üblich sind (Abbildung 1). So finden sich beispielsweise Variablendefinitionen, Prozeduren und Zuweisungen sowie Konstrukte für Schleifen und Wertevergleiche. Nach dem Vorspann (“Prolog”) folgt der eigentliche Inhalt, Script genannt.
Neben Prozedurdefinitionen (%%BeginProcSet) enthält das Script unter anderem auch die Seitengröße (%%BeginSetup). Jede einzelne Seite beginnt mit dem Kommando %%Page. Danach folgen die Anweisungen für das Positionieren und Zeichnen der Grafik- und Textobjekte auf der Seite. Den Abschluss des Dokuments bildet ein Abspann. Er beginnt mit %%Trailer und endet mit der Markierung %%EOF (“end of file”).
Weitere Details, Kommandos und ausführliche Beispiele zu Postscript beinhaltet das “PostScript Language Cookbook” [12].
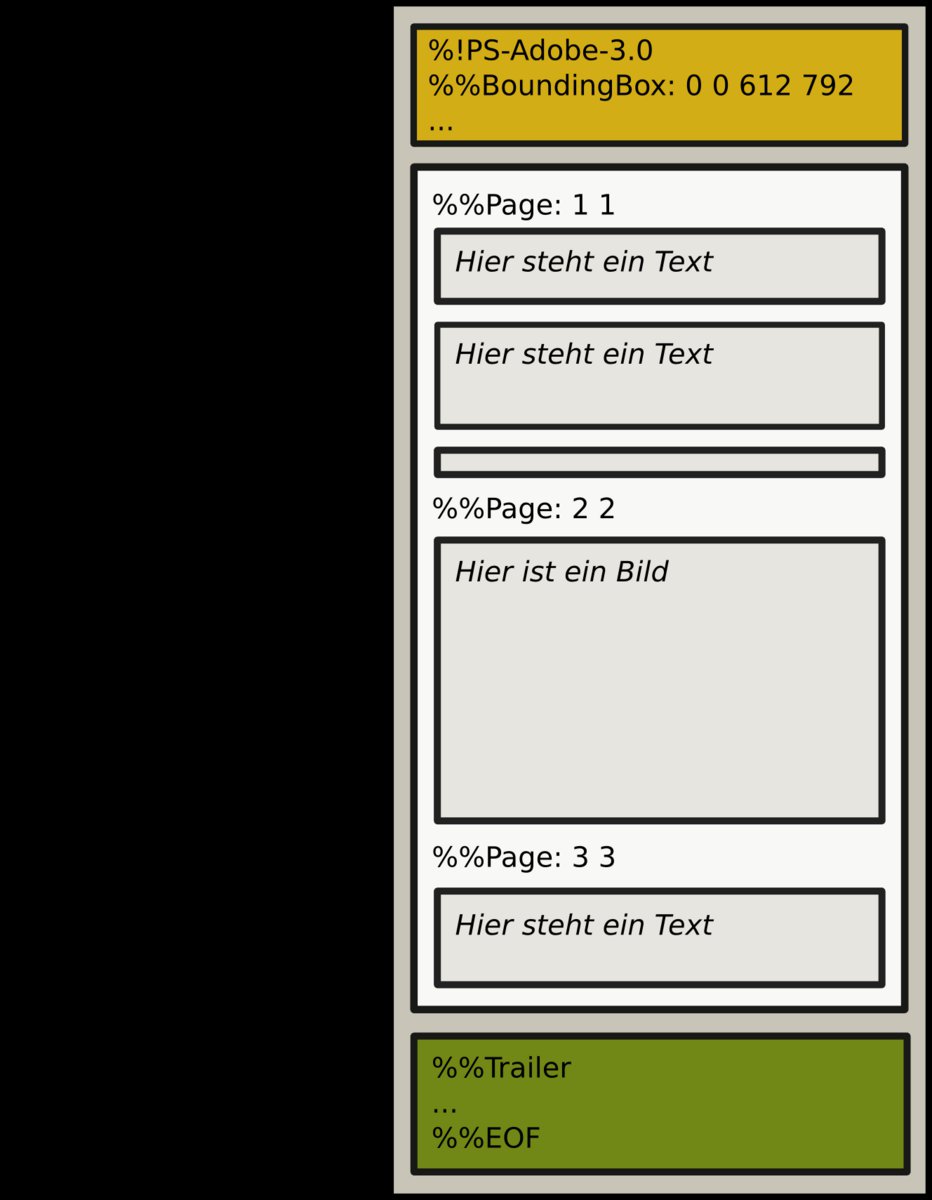
Abbildung 1: Der Aufbau einer Postscript-Datei.
PDF im Detail
Die Abfolge der Strukturen in PDF und Postscript fallen nahezu identisch aus (siehe [13], S. 62). Ein PDF-Dokument besteht ebenfalls aus vier Abschnitten (Abbildung 2) – dem Vorspann (“Header”), dem Inhalt (“Body”), dem Inhaltsverzeichnis der Objekte (“Cross-reference table”) und dem Abspann (“Trailer”).
Im Header stehen die Metainformationen zum Dokument, wie etwa die PDF-Version, der Autor, die Schlüsselworte zum Dokumenteninhalt sowie das Programm, mit dem das PDF-Dokument erzeugt wurde. Diese Metainformationen lassen sich mit den beiden Werkzeugen pdfinfo [14] und pdftk [15] auslesen und verändern. Teil 7 dieser Serie [16]) hat sich ausführlich mit diesen Programmen befasst.
Nach dem Header folgt im PDF-Dokument der eigentliche Inhalt (“Body”). Er besteht aus einer Folge von einzelnen Objekten mit Seiten- und Größeninformation, Positionsangaben sowie Text- und Grafikkommandos (genannt “Object Stream”). Um diese Objekte und deren Abfolge in der Darstellung zu bestimmen und einen wahlfreien Zugriff darauf zu ermöglichen, enthält das Dokument ein Inhaltsverzeichnis der einzelnen Objekte (PDF-Kommando xref). Zum Schluss des Dokuments folgt der Abspann, der die Position des Inhaltsverzeichnisses beinhaltet (startxref) und das Ende des PDF-Dokuments markiert (%%eof).

Abbildung 2: Der Aufbau einer PDF-Datei.
Suchen in Textdaten
Beim Wiederfinden von Daten anhand einer Suchanfrage handelt es sich um einen recht komplexer Vorgang. Zunächst gilt es den Suchstring – also das Textfragment, nachdem man fahndet – in eine interne Darstellung für den Suchvorgang umzuwandeln, beispielsweise in einen Regulären Ausdruck [2]. Mit dieser modifizierten Anfrage durchsucht ein Algorithmus die Datenmenge und markiert die einzelnen Fundstellen. Vor der Ausgabe des Suchergebnisses erfolgt eine Sortierung der Suchtreffer anhand der Relevanz, meistens beginnend mit der höchsten Übereinstimmung mit dem Suchstring (“absteigende Sortierung”). Mittlerweile gewinnen alternative Darstellungen an Beliebtheit, wie etwa mehrfarbige Ringe und Waben (Abbildung 3) oder Baumstrukturen. Dabei erfolgt eine Kategorisierung der Dokumente anhand der zugehörigen Stichworte.
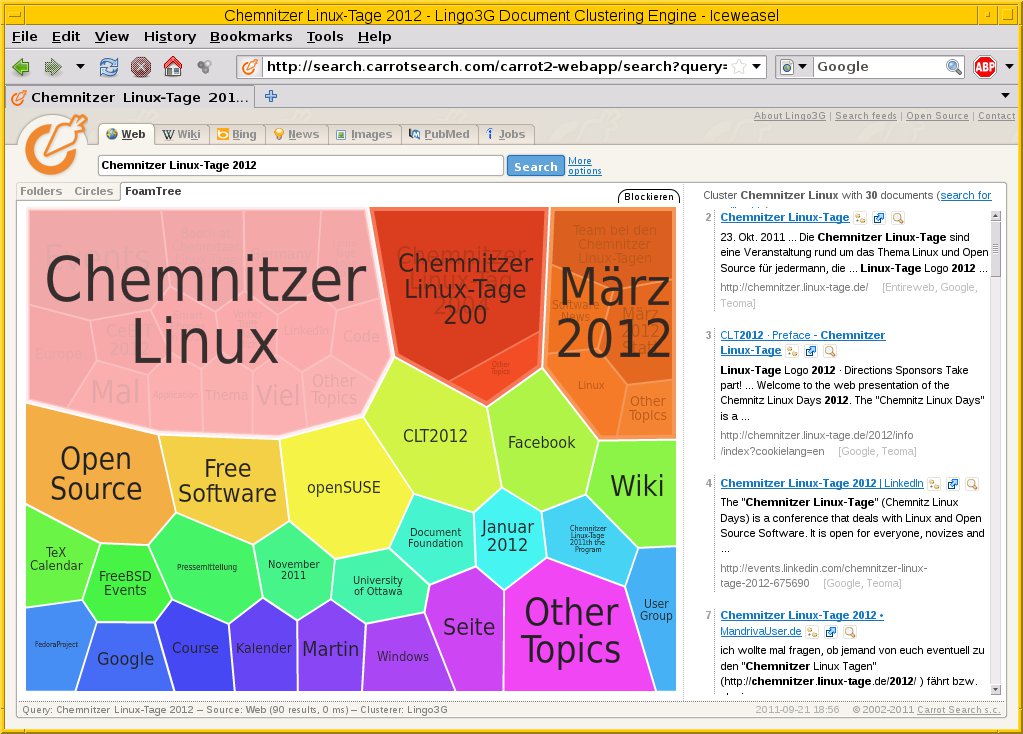
Abbildung 3: Visualisierung eines Suchergebnisses mit dynamischen Waben bei Carrot Search.
Um Postscript- und PDF-Dokumente in die Suche miteinzubeziehen, bedarf es etwas mehr Mühe. Einfache Grep-Kommandos helfen kaum weiter, um das Vorkommen eines Suchstrings in festzustellen. Der Grund dafür liegt in der Art und Weise, wie Postscript und PDF die eigentlichen Inhalte im Dokument abspeichern. Den Ausgangspunkt bildet ein zweidimensionales Koordinatensystem mit dem Nullpunkt in der linken oberen Ecke jeder Seite. Alle Objekte werden mit den entsprechenden X/Y-Koordinaten im Dokument abgelegt und darüber exakt auf der Seite positioniert.
Um ein möglichst perfektes Druckbild zu erreichen, folgen Satzsysteme wie beispielsweise LaTeX den Konventionen aus über 500 Jahren Buchdruck. Beim Umwandeln von LaTeX nach Postscript/PDF werden die Absätze in einzelne Wörter und Buchstaben zerlegt (“bounding boxes”). Feinheiten im Satz, wie etwa Über- und Unterschneidungen der Buchstaben, realisiert das Verfahren über entsprechend verkürzte oder vergrößerte Abstände zwischen den einzelnen Zeichen. Der geometrische Anfang eines Buchstabens wird in die passenden X/Y-Koordinaten umgerechnet.
Postscript und PDF haben gemeinsam, dass die Abfolge der Objekte im Dokument nur einen begrenzten Schluss auf das endgültige Aussehen des Dokuments – das Druckbild – zulässt. Bei Postscript kann man die Positionierungen immerhin noch seitenweise nachzuvollziehen, bei PDF-Dokumenten muss man dazu die einzelnen Elemente des gesamten Object Streams verfolgen.
Dabei dürfen obendrein nachfolgende Objekte vorhergehende wieder überdecken, beispielsweise um eine nachträgliche Schwärzung von Text mit Hilfe eines Balkens zu erreichen. Bei der Anzeige oder dem Ausdruck des Dokuments lassen sich diese Einzelschritte nicht mehr erkennen, da nur die “Draufsicht” erscheint und die einzelnen Ebenen nicht mehr zu sehen sind. Zudem gestattet PDF neben dem Verweis auf externe Daten auch das Einbinden von verkleinerten Vorschaubildern mit unterschiedlichen Auflösungen, Videos, Flash- und Javascript-Elementen sowie komprimierten Daten und Anhängen mit den jeweiligen Referenzen aufeinander.
Finden sich Textfragmente in Form eingebundener Grafiken im Dokument, verhält es sich ähnlich wie bei Webseiten: Zwar kann ein Mensch den Text problemlos erfassen, er lässt sich aber nicht oder nur schwer automatisch von Programmen wie grep verarbeiten. Suchmaschinen versuchen dieses Problem zu lösen, indem bei der Dokumentanalyse zusätzliche Programme zur Texterkennung [3] einbinden. Aus Sicht des Endanwenders steht dieser Aufwand jedoch vielfach nicht im gesunden Verhältnis zum tatsächlichen Nutzen.
Suche in Postscript-Dateien
Für Dateien im Postscript-Format stehen als Betrachter beispielsweise Ghostview, Kghostview, Evince und Okular zur Verfügung. Keines der genannten Werkzeuge ermöglicht bislang eine Suche in den Daten: Menüpunkte zur Recherche gibt es zwar, sie lassen sich aber nicht anwählen.
Um trotzdem ein zumindest ansatzweise brauchbares Ergebnis zu erzielen, bleibt nur der Ausflug auf die Kommandozeile. Hier erweisen sich die Werkzeuge pstotext, ps2ascii und grep als hilfreich. Die Kombination daraus sieht folgendermaßen aus:
$ pstotext Datei.ps | grep --color Suchstring $ ps2ascii Datei.ps | grep --color Suchstring
Die Kommandos extrahieren den Text aus der Postscript-Datei und schreiben ihn auf die Standardausgabe. Von dort gelangt er über eine Pipe als Eingabe an das Kommando grep, das dann in den Daten nach dem übermittelten Suchstring fahndet. Die Grep-Option --color hebt den Suchtreffer in der Ausgabe farblich hervor und erleichtert so das Auswerten der Trefferliste.
Beide Varianten benötigen wenig Zeit, haben aber den Nachteil, dass sie nur Zeichen im Encoding ISO 8859-1 (Latin-1) zuverlässig auslesen können. Andere Codierungen, wie etwa ISO 8859-15 (Latin-1 mit Euro) oder UTF-8 unterstützen sie nur bedingt. Im Ergebnis zeigt sich das, indem eine Suche nach Fragmenten mit Umlauten maximal Teilergebnisse liefert oder sogar gänzlich fehlschlägt. Im Test kam Ps2ascii etwas besser mit Umlauten zurecht, dafür fehlen Wortzwischenräume und Zeilenumbrüche.
Im Laufe der Recherchen ergab sich eine (wenn auch auf den ersten Blick ungewohnte) Alternative zu Ps2ascii – der Umweg über PDF:
$ ps2pdf Datei.ps $ pdfgrep Datei.pdf Suchstring
Mit dieser etwas seltsam anmutenden Aufruffolge von Ps2pdf über Pdfgrep gelingt die Suche im Postscript-Dokument.
Device independent file format (DVI)
Etwas leichter hat es, wer für seine Dokumente das geräteunabhängige Dateiformat DVI [4] verwendet. Es entsteht beispielsweise als Zwischenergebnis, wenn man LaTeX-Dokumente nach Postscript übersetzt.
Sowohl Okular als auch der Veteran Xdvi ermöglichen eine Suche unabhängig von der Groß- und Kleinschreibung und heben die jeweiligen Fundstellen im Dokument farbig hervor. Xdvi gestattet bei der Recherche im Text auch die Verwendung regulärer Ausdrücke (Abbildung 4). Evince kann zwar ebenfalls DVI-Dateien lesen, fällt aber bei den verwendeten Fonts auf die Nase. Kurioserweise blieb im Test auch die Möglichkeit zur Suche deaktiviert.
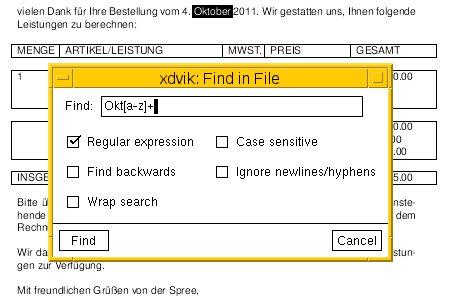
Abbildung 4: So funktioniert die Suche im Betrachter Xdvi.
Zum im vorigen Abschnitt vorgestellten Aufruf auf der Kommandozeile für Postscript-Dateien gibt es mit dvitype ein Analogon für DVI:
dvitype Datei.dvi | grep --color Suchstring
Dvitype geht auf Donald E. Knuth zurück und bildet einen festen Bestandteil der Werkzeugsammlung des Textsatzsystems LaTeX. Das Tool analysiert die DVI-Datei und extrahiert neben den einzelnen Zeichen auch deren Position auf der Seite in der DVI-Datei. Mit Grep lassen sich dann jene Zeilen aus dem Ergebnis herausfiltern, die den Suchstring enthalten. In Bezug auf Umlaute und Encodings verhält sich Dvitype ähnlich unkomfortabel wie Pstotext und kommt ebenfalls nicht mit UTF-8 zurecht (Abbildung 5).
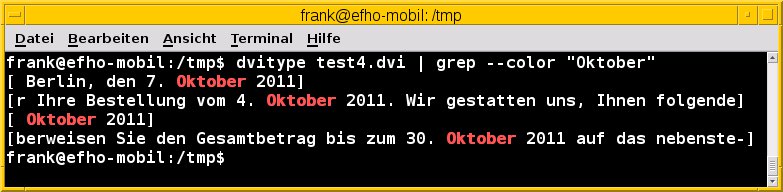
Abbildung 5: Ein “umlautbefreites” Suchergebnis nach der Ausgabe von Dvitype.
Portable Document Format
Anzeigeprogramme für das populäre PDF-Format gibt es inzwischen zuhauf. Die bekanntesten Werkzeuge dafür sind der Altmeister Xpdf sowie Evince aus dem Gnome-Projekt und Okular als KDE-Pendant. Als absolut ebenbürtig erweisen sich jedoch die deutlich schlankeren Alternativen Epdfview [5], Mupdf, Zathura und Apvlv. Die drei Letztgenannten orientieren sich in ihrer tastaturzentrierten Bedienung am Konzept des Texteditors Vi(m) [6].
Eine Liste freier PDF-Betrachter hält die Free Software Foundation Europe (FSFE) vor [7]. Sie setzt sich damit für eine anbieterunabhängige Auswahl ein und möchte der Öffentlichkeit Programme ins Bewusstsein rufen, die die vier Freiheiten respektieren – das Nutzen, Untersuchen, Weitergeben und Verbessern. Ein weiteres Ziel: Die starke Verknüpfung zwischen dem PDF-Format und Adobes Acrobat-Produktfamilie zu lösen sowie deutlich zu machen, dass es brauchbare und kostenfreie Alternativen gibt.
Alle Betrachter mit einer Menüleiste (Xpdf, Epdfview, Okular und Evince) verfügen über einen entsprechenden Menüpunkt zur Suche. Nach dessen Auswahl öffnet sich ein entsprechendes Eingabefenster. Bei allen Programmen mit Ausnahme von Xpdf erreichen Sie dieses Suchfenster zusätzlich über [Umschalt]+[7] (“/”). Dies spiegelt eine Tastenbelegung wieder, wie sie im Texteditor Vi(m) üblich ist. Die alternative Tastenkombination [Strg]+[F] unterstützen hingegen Evince, Okular, Epdfview und Xpdf.
Fast alle Programme blenden zur Suche am unteren Rand des Fensters eine kleine Leiste ein, teilweise mit einem Eingabefeld und mehreren Schaltflächen für die Suchrichtung und zusätzliche Optionen. Wieder kippt Xpdf aus der Reihe, bei dem ein separates Fenster erscheint.
Bei allen Programmen beginnt die Suche im Dokument bereits, noch während Sie das Suchwort eingeben. Der “Cursor” springt, ausgehend von der aktuellen Position, zum nächsten Suchtreffer im Dokument. Die Suche vorwärts und rückwärts bieten alle Betrachter an, nur jeweils verbunden mit einer anderen Tastenbelegung (siehe Tabelle “Tastenkombinationen”). Mit [Esc] blenden Sie die Leiste beziehungsweise das Suchfenster wieder aus.
Tastenkombinationen
| PDF-Betrachter | Suche vorwärts beginnen | Suche rückwärts beginnen | Suche vorwärts fortsetzen | Suche rückwärts fortsetzen |
|---|---|---|---|---|
| Epdfview | über GUI, [Umschalt]+[7],[Strg]+[F] | n.v. | [Eingabe] | n.v. |
| Evince | über GUI, [Umschalt]+[7],[Strg]+[F] | n.v. | [Strg]+[G] | [Strg]+[Umschalt]+[G] |
| Okular | über GUI, [Umschalt]+[7],[Strg]+[F] | n.v. | [F3] | [Umschalt]+[F3] |
| Xpdf | über GUI (“Fernglas”-Icon), [Strg]+[F] | n.v. | [Eingabe] | n.v. |
| Apvlv | [Umschalt]+[7] | [Umschalt]+[ß] | [N] | [Umschalt]+[N] |
| Mupdf | [Umschalt]+[7] | [Umschalt]+[ß] | [N] | [Umschalt]+[N] |
| Zathura | [Umschalt]+[7] | [Umschalt]+[ß] | [N] | [Umschalt]+[N] |
| n.v. = nicht vorhanden; [Umschalt]+[7] = “/”; [Umschalt]+[ß] = “?” | ||||
Bei den Suchoptionen wird es teilweise recht dünn. Okular und Xpdf bieten immerhin eine Suche nach der exakten Groß- und Kleinschreibung an (“case sensitive”), Okular gestattet außerdem das Einschränken auf die aktuelle Seite (Abbildung 6). Evince blendet als Hilfe die Anzahl der Suchtreffer in der Suchleiste ein (Abbildung 7). Eine Suche mittels regulärer Ausdrücke lassen alle vier Programme vermissen.
Abbildung 6: Die Suchleiste in Okular (KDE).
Abbildung 7: Die Suchleiste in Evince (Gnome).
Suche im Verzeichnis
Will man ein ganzes Archiv durchforsten, möchte man nicht jedes Dokument einzeln öffnen und darin suchen. Hier bewähren sich wieder die Werkzeuge auf der Kommandozeile. Der erste Kandidat erfordert etwas Bash-Know-how – er besteht aus eine Kombination von Pdftotext und Grep mit einer Pipe in einer For-Schleife:
$ for datei in $(ls *.pdf); do pdftotext $datei - | grep --color Suchstring; done
Zunächst listet das Kommando mittels ls alle PDF-Dateien im aktuellen Verzeichnis auf. Die For-Schleife arbeitet diese Liste dann zeilenweise ab. Pdftotext wandelt jede PDF-Datei aus der Liste in einfachen Text um und schickt die Ausgabe auf die Standardausgabe. Dafür sorgt der zweite Parameter (-). Grep übernimmt die Ausgabe als Eingabe und stöbert darin anschließend nach dem Suchstring.
In den Tests zeigte sich, dass das kleine Skript flink und zuverlässig arbeitet. Pdftotext kommt problemlos mit den gebräuchlichen Encodings ISO 8859-1, 8859-15 und UTF-8 zurecht. Über die Option -enc Encoding wählen Sie bei Bedarf explizit die gewünschte Zeichenkodierung zur Extraktion aus.
Sind viele Treffer zu erwarten, hilft das Kommando less, um durch die Ergebnisliste zu blättern. Sie fügen es einfach über eine weitere Pipe an die obige Kommandozeile an. Da Less die farbliche Hervorhebung der Suchtreffer nicht übernimmt, können Sie dabei die grep-Option --color im Aufruf streichen.
Als Kandidat Nummer Zwei präsentiert sich das bereits erwähnte Werkzeug Pdfgrep [8]. Es ist zwar nicht auf jeden Linux-System vorhanden, steht aber beispielsweise als offizielles Debian-Paket bereit. Analog zu Grep durchsucht es die übermittelte Dateiliste nach dem angegebenen Textfragment:
$ pdfgrep Suchstring Dateiliste
Alle Suchtreffer hebt das Tool automatisch farbig hervorgehoben. Über die Option --color <§§I>Wert<§§I> verändern Sie dieses Verhalten. Als Wert dazu kennt Pdfgrep drei Varianten: always hebt immer hervor, never schaltet die Hervorhebung ab und auto hebt nur hervor, wenn die Ausgabe auf einem Terminal erfolgt.
Als hilfreich erweisen sich auch die Optionen -n und -i. Mit -n gibt Pdfgrep zusätzlich die Seite aus, auf der der Treffer erfolgte, -i sucht unabhängig von der Groß- und Kleinschreibung. Damit lässt sich beispielsweise relativ unkompliziert in elektronischen Rechnungen stöbern.
Ein Beispiel zeigt Abbildung 8. In der ersten Spalte der Ausgabe steht der Dateiname (in Violett), danach die Seite, auf der das Fragment gefunden wurde (in Grün) und zum Schluss das gefundene Fragment (in Rot). Der Parameter -C 15 sorgt dafür, dass Pdfgrep den Kontext um den Suchtreffer mit ausgibt, wobei der Wert 15 diesen Kontext auf 15 Zeichen festsetzt. Ohne diesen Parameter gibt pdfgrep nach Möglichkeit die ganze Zeile aus, in der es das Fragment gefunden hat.
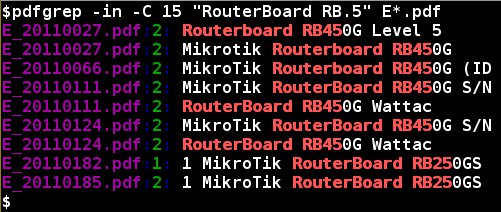
Abbildung 8: Pdfgrep gibt Suchtreffer mit Dokument und Seitennummer aus.
Pdfgrep unterstützt auch erweiterte reguläre Ausdrücke. Sie können damit auch nach mehreren Kriterien suchen, indem Sie die Anfrage in einen passenden regulären Ausdruck überführen. In Abbildung 9 etwa sucht Pdfgrep in allen PDF-Dokumenten nach einer Zeichenkette, die mit der Produktbezeichnung “NanoStation” beginnt, gefolgt von mindestens einem weiteren Buchstaben (.+) sowie der Seriennummer des Gerätes, beginnend mit “156D1”. Die Klammern dienen der Gruppierung der einzelnen Worte.
Abbildung 9: So sieht in Pdfgrep ein Suchergebnis unter Verwendung regulärer Ausdrücke aus.
Bilddaten
Auch einzelne Bilder lassen sich bei Bedarf vom Dokument separieren. Für Postscript gibt es dazu psrip. Für PDF steht (als Bestandteil des Pakets poppler-utils) das Werkzeug pdfimages zur Verfügung. Beide Programme haben wir bereits in Teil 6 dieser Serie [9] ausführlich vorgestellt.
Fazit
Die Suche in Postscript- und PDF-Dokumenten klappt nur dann einigermaßen, wenn die Daten als einzelne Buchstaben im Dokument abgespeichert sind. Besteht das Dokument stattdessen aus Bild, wird es wesentlich komplexer. Im Alltag entstehen solche Dokumente häufig, etwa bei gescannten Daten und bei der Verwendung digitaler Faxgeräte. Auf den ersten Blick tendiert man dazu, diesen Fakt zu übersehen, weil der Mensch das Dokument problemlos lesen kann. Eine nachfolgende automatische Indexierung und Klassifikation klappt indes nur dann, wenn eine Texterkennung mit einer OCR-Software zu einem brauchbaren Ergebnis führt – das jedoch ist ein Kapitel für sich.
Danksagung
Der Autor bedankt sich bei Thomas Winde und Wolfram Eifler für deren kritische Anmerkungen und Kommentare im Vorfeld dieses Artikels.
Infos
[1] PDF/A-Technik: http://www.pdfa.org/2011/09/pdfa-%E2%80%93-ein-blick-auf-die-technische-seite/?lang=de
[2] Reguläre Ausdrücke: Frank Hofmann, “Schnipseljagd”, LU 09/2011, S. 84, https://www.linux-community.de/24091
[3] OCR unter Linux: Andreas Gohr, “Linux OCR Software Comparison”, http://www.splitbrain.org/blog/2010-06/15-linux_ocr_software_comparison
[4] DVI: http://de.wikipedia.org/wiki/Device_independent_file_format
[5] Epdfview und Co.: Frank Hofmann, “Angeschubst” LU 05/2010, S. 90, https://www.linux-community.de/20051
[6] Vim-Basics: Frank Hofmann, Thomas Winde, “Vielseitig”, LU 10/2011, S. 32, https://www.linux-community.de/24065
[7] Liste freier PDF-Betrachter: http://www.pdfreaders.org
[8] Pdfgrep: http://pdfgrep.sourceforge.net
[9] Frank Hofmann, “Scheibchenweise”, LU 12/2009, S. 88, https://www.linux-community.de/19635
[10] Stackbasierte Sprachen: http://de.wikipedia.org/wiki/Stapelspeicher#Stapelorientierte_Sprachen
[11] Ghostscript: http://www.ghostscript.com
[12] PS Language Cookbook: Adobe Systems Incorporated, “PostScript Language”, Addison Wesley 1985
[13] PDF-Referenz: Adobe Systems Incorporated, “PDF Reference, 3rd Edition”, Addison Wesley 2001, ISBN 9780-201-758399
[14] Pdfinfo: http://linuxcommand.org/man_pages/pdfinfo1.html
[15] Pdftk: http://www.accesspdf.com/pdftk/
[16] PDF-Metadaten: Frank Hofmann, “Innere Werte”, LU 02/2010, S. 90, https://www.linux-community.de/20357






Vielen Dank für den schönen Artikel! Folgeartikel zu OCR oder auch zu genaueren PDF/PS-Innereien fände ich großartig. :)
Nur zwei Anmerkungen:
(1)
$ for datei in $(ls *.pdf); do pdftotext $datei – | grep –color Suchstring ; done
welchen Vorteil hat das gegenüber:
$ for datei in *.pdf; do pdftotext $datei – | grep –color Suchstring ; done
(2)
“””Da Less die farbliche Hervorhebung der Suchtreffer nicht übernimmt, können Sie dabei die grep-Option –color im Aufruf streichen.”””
less übernimmt die Hervorhebung, wenn man ihm die Option “-R” gönnt.
Viele Grüße