

OpenCL macht die Grafikkarte vom alltäglichen, aber langweiligen Begleiter zum Turbo für anspruchsvolle Rechenoperationen. Wie im richtigen Leben spielt der Lader seine Qualitäten aber erst auf der Autobahn aus – im Stadtverkehr rührt sich wenig.
Nachdem der erste Teil dieses Artikels in der letzten Ausgabe einen Überblick über den Anwendungsbereich von OpenCL gab und auf die Installation einging, widmen sich dieser Teil den Arbeitsschritten zur Bildfaltung mittels OpenCL auf der Grafikkarte (Abbildung 1, Abbildung 2). Die im vorigen Teil des Artikels vorgestellte CPU-Implementierung dient dabei später als Referenz für die Laufzeitmessung.

Abbildung 1: Das Eingabebild: Larry Ewings Tux.

Abbildung 2: Das Ergebnis: Tux’ Gradienten, gefaltet mit einem Sobelkernel.
Nun widmen wir uns dem OpenCL-Code, dessen wichtigste Partien Sie in Listing 1 sehen. Den kompletten Quelltext finden Sie auch auf der Heft-DVD sowie zum Download auf unserer Website [1].
Listing 1
1 #define __CL_ENABLE_EXCEPTIONS... 13 const char* kernelSource = "\ 14 __kernel void convolveKernel(\ 15 global uchar *in,\... 18 global uint *out,\... 21 global float *convKernel,\ 22 uint convKernelWidth,\ 23 uint convKernelHeight)\ 24 {\ 25 size_t x = get_global_id(0);\ 26 size_t y = get_global_id(1);\... 35 for(size_t ky = 0; ky < convKernelHeight; ++ky)\ 36 { 37 for(size_t kx = 0; kx < convKernelWidth; ++kx)\ 38 {\ 39 convolutionSum += (float) in[(y + ky) * inWidth + (x + kx)]\ 40 * convKernel[ky * convKernelWidth + kx];\ 41 }\ 42 }\ 43 out[y * outWidth + x] = (uint) clamp(convolutionSum, 0, 255);\ 44 }"; 45 46 /** 47 * Convolve a grayscale image with a convolution kernel on the GPU using OpenCL. 48 */ 49 grayImage convolveGPU(grayImage in, convolutionKernel convKernel) 50 { 51 grayImage out; 52 out.width = in.width - (convKernel.width - 1); 53 out.height = in.height - (convKernel.height - 1); 54 out.data = new uchar[out.height * out.width]; 55 56 // Platforms 57 std::vector< cl::Platform > platforms; 58 cl::Platform::get(&platforms); 59 assert(platforms.size() > 0); 60 61 // Devices 62 std::vector<cl::Device> devices; 63 platforms[0].getDevices(CL_DEVICE_TYPE_GPU, &devices); 64 assert(devices.size() > 0); 65 assert(devices[0].getInfo<CL_DEVICE_TYPE>() == CL_DEVICE_TYPE_GPU); 66 67 // Context 68 cl::Context context(devices); 69 70 // Create GPU buffers 71 cl::Buffer inGPU(context, CL_MEM_READ_ONLY, in.width * in.height * sizeof(uchar)); 72 cl::Buffer convKernelGPU(context, CL_MEM_READ_ONLY, convKernel.width * convKernel.height * sizeof(float)); 73 cl::Buffer outGPU(context, CL_MEM_WRITE_ONLY, out.width * out.height * sizeof(uint)); 74 75 // Commandqueue 76 cl::CommandQueue queue(context, devices[0], 0); 77 78 // Upload in.data to inGPU 79 queue.enqueueWriteBuffer(inGPU, false, 0, in.width * in.height * sizeof(uchar), in.data);... 86 // Upload kernel.data to convKernelGPU 87 queue.enqueueWriteBuffer(convKernelGPU, true, 0, convKernel.width * convKernel.height * sizeof(float), convKernel.data);... 94 // Program 95 cl::Program::Sources source(1, std::make_pair(kernelSource, strlen(kernelSource))); 96 97 cl::Program program(context, source); 98 program.build(devices); 99100 // Ranges101 size_t localWidth = 16;102 size_t localHeight = 16;103104 cl::NDRange localRange(localWidth, localHeight);105 cl::NDRange globalRange(((out.width-1)/localWidth+1) * localWidth, ((out.height-1)/localHeight+1) * localHeight);106107 // Run kernel108 cl::Kernel kernel(program, "convolveKernel");109 cl::KernelFunctor func = kernel.bind(queue, globalRange, localRange);110111 cl::Event event = func(inGPU, in.width, in.height, outGPU, out.width, out.height, convKernelGPU, convKernel.width, convKernel.height);112 event.wait();113114 // Download result115 uint *outTemp = new uint[out.width * out.height];116 queue.enqueueReadBuffer(outGPU, true, 0, out.width * out.height * sizeof(uint), outTemp);...123 // Convert uint array to uchar array124 for(size_t i = 0; i < out.width * out.height; ++i)125 { out.data[i] = (uchar) outTemp[i];127 }...129 delete outTemp;130 return out;131 }
Los geht’s
Um die in Teil 1 bereits erwähnten OpenCL-C++-Bindings zu verwenden, genügt ein simples #include <CL/cl.hpp>. Statt der in C üblichen Errorcodes sollen die Exceptions der Bindings zum Einsatz kommen. Dazu dient die Definition #define __CL_ENABLE_EXCEPTIONS. Sämtliche Klassen finden sich im Namespace cl::. Um dem Linker mitzuteilen, wogegen er zu linken hat, fügen Sie der Parameterliste beim Aufruf von g++ noch das Argument -lOpenCL hinzu.
Benötigte Verwaltungsobjekte
Im Gegensatz zu Cuda erzeugt OpenCL den plattformabhängigen Code erst zur Laufzeit. Somit muss OpenCL zunächst herausfinden, welche Hardware den parallel auszuführenden Code abarbeiten wird. Dazu erzeugen Sie in den Zeilen 57 und 62 von Listing 1 eine cl::Platform und einen Vektor mit cl::Devices.
TIPP
Es gibt zwei unterschiedliche Typen von cl::Platform: “full profile” und “embedded profile”. Dieser Artikel behandelt das “full profile”.
Innerhalb jeder cl::Platform kann es mehrere cl::Device geben, die jeweils eine verbaute GPU oder CPU wiederspiegeln. Die assert()>-Anweisungen ab Zeile 64 stellen sicher, dass es mindestens ein OpenCL-fähiges Device gibt und es sich beim ersten Device um eine unterstützte Grafikkarte handelt. Für ein Ausführen auf der CPU müssen Sie dementsprechend dasjenige Device aus dem Vektor nehmen, das vom Typ CL_DEVICE_TYPE_CPU ist.
Ein cl::Context verwaltet über diverse cl::Devices hinweg Objekte wie Command Queues, Speicherobjekte, Kernel und Ausführungsobjekte. Auf diese Objekte werden wir im Folgenden noch eingehen; im Beispiel verwaltet ein cl::Context nur unsere Grafikkarte.
Schließlich gibt es noch eine cl::CommandQueue. In diese reihen Sie Aktionsobjekte ein, die das System dann im Standardfall der Reihe nach (FIFO) ausführt.
Daten kopieren
Um unsere Daten (Eingabebild, Faltungskernel, Ausgabebild) im Grafikspeicher zu lagern, müssen Sie zunächst sogenannte cl::Buffer-Objekte für sie erzeugen (ab Zeile 71). Im Konstruktor übergeben Sie den verwaltenden Context, den Zugriffsmodus und die Größe. Dies entspricht im Prinzip einem malloc() im GPU-RAM.
Für einen cl::Buffer gibt es die Zugriffsmodi nur lesend (CL_MEM_READ_ONLY), nur schreibend (CL_MEM_WRITE_ONLY) und lesend/schreibend (CL_MEM_READ_WRITE). Die “Blickrichtung” bezieht sich hierbei auf den Zugriff von der Grafikkarte aus – der Host hat in allen Fällen Vollzugriff auf die Speicherobjekte. Für jedes Speicherobjekt geben Sie malloc()-typisch die zu reservierende Größe in Byte an. Falls das GPU-RAM nicht ausreicht, wirft der Aufruf eine Exception, die sich bequem fangen lässt.
Im nächsten Schritt kopieren Sie die Eingabedaten vom Host in den soeben erzeugten cl::Buffer. Die Kopieraktionen hierzu reihen Sie mittels enqueueWriteBuffer() in die Command-Queue eingereiht (Zeile 79). Im einzelnen geben Sie als Parameter an:
- den Zielpuffer,
- ob die Aktion blockierend sein soll (Ausführung kehrt erst nach Abschluss der Aktion zum Host zurück),
- einen Offset,
- die zu kopierende Größe in Byte sowie
- einen Pointer mit der Speicheradresse im Host.
Den Blocking-Parameter der ersten Kopieraktion setzen Sie auf false. Die Aktion wird in die Command-Queue eingereiht und der Host bekommt wieder die Ausführungsgewalt (während das Kopieren im Hintergrund abläuft), um gleich danach die zweite Kopieraktion einzureihen. Diese arbeitet blockierend, um den Host erst nach dem Ende der zweiten Kopieraktion wieder weiterarbeiten zu lassen. Da die Command Queue nach dem FIFO-Prinzip arbeitet, sind anschließend beide Kopieraktionen abgeschlossen. Das ermöglicht ein korrektes Timing der I/O-Aktionen. Sofern keine oder nur lineare Abhängigkeiten zwischen den Aktionen bestehen, lässt sich jede Aktion nicht blockierend ausführen – bis auf die zuletzt eingereihte.
Der Kernel
Wie bereits erwähnt, müssen Sie jedem Thread auf der Grafikkarte mitteilen, was er in Abhängigkeit seines Indexes zu tun hat. Den Quelltext des Kernels hinterlegen Sie als const char* mit dem Namen kernelSource (ab Zeile 13). Mit dem Schlüsselwort __kernel teilen Sie dem OpenCL-Runtime-Compiler mit, dass es sich um einen OpenCL-Kernel handelt. Als Untermenge von ISO C99 ähnelt OpenCL-C dem Standard in Syntax und Semantik. Zusätzlich bringt OpenCL eine Reihe von nützlichen, eingebauten Funktionen mit [2].
Drei Parameter mit dem Schlüsselwort global in der Parameterliste identifizieren Pointer im globalen Grafikspeicher, die auf die erstellten cl::Buffers zeigen. Mittels der eingebauten Funktion get_global_id() ordnen Sie jedem Thread einen eindeutigen Index zu. Mit dem Parameter 0 behandeln Sie die X-Dimension entlang des Ausgabebildes (Zeile 25), analog steht 1 für die Y-Dimension.
Die Hauptaufgabe jedes Threads (ab Zeile 35) übernehmen Sie im Prinzip direkt von der CPU-Implementierung respektive deren Pseudocode-Zwischenform, die Sie bereits im ersten Teil des Artikels kennengelernt haben. Sie benötigen hier lediglich die inneren beiden Schleifen, da die Threads schon alle benötigten X- und X-Werte parallel behandeln. Beim Speichern der Faltungssumme nutzen Sie die eingebaute Funktion clamp(), deren Funktionsweise jener von clampuchar() entspricht.
Als aufmerksamen Leser fällt Ihnen sicher auf, dass der cl::Buffer outGPU vorzeichenlose Ganzzahlen statt uchar speichert (Zeile 73). Der Grund: Einige Grafikkartenmodelle unterstützen das Speichern auf beliebige Adressen nicht [3]. Schreiben Sie auf Adressen, die integer-aligned sind (also in der Regel alle 4 Byte), bleiben Sie auf jeden Fall auf der sicheren Seite. Um auf beliebige Adressen zu speichern, müssten Sie dagegen das OpenCL-Pragma cl_khr_byte_addressable_store aktivieren. Ob die verwendete CPU dies unterstützt, gilt es vorab über getInfo() auf dem cl::Device herauszufinden.
Der Kernelquelltext muss noch von der OpenCL Library zur Laufzeit kompiliert werden, um die Plattformunabhängigkeit zu gewährleisten. Dazu erzeugen Sie ein cl::Program-Objekt aus dem Quelltext und lassen es mit program.build() kompilieren (ab Zeile 95).
Kernelaufruf
Neben einem eindeutigen globalen Index verfügt jeder Thread durch den Hardware-Aufbau bedingt auch über einen sogenannten lokalen Index. Alle Threads innerhalb einer sogenannten Work Group teilen sich einen kleinen, gemeinsamen Speicher, der sehr schnell arbeitet.
In der unoptimierten Variante nutzen Sie diesen Speicher nicht und verwenden stattdessen eine generische zweidimensionale Größe von 16×16 für eine Work Group (ab Zeile 101). Für den Kernelaufruf benötigen wir auch die Gesamtanzahl an Threads in jeder Dimension. Diese muss mindestens so groß ausfallen wie das Ausgabebild, sich jedoch auch in jeder Dimension durch die Größe der Work Group teilen lassen.
Nun laden Sie zuvor kompilierten Kernel aus dem cl::Program und übergeben die soeben berechneten Größen. Schließlich starten Sie den Kernel, indem Sie dem cl::KernelFunctor die Parameter übergeben. Dazu gehören die Puffer für Ein- und Ausgabebild sowie den Faltungskernel-Buffer und die dazugehörigen Metainformationen (Zeile 111). Während Sie die Puffer erzeugen und befüllen mussten, können Sie einfache Datentypen wie die Größen der Bilder direkt (also ohne enqueueWriteBuffer()) übergeben.
Ein Kernelaufruf arbeitet stets nicht blockierend. Um auf seinen Abschluss zu warten, können Sie ein cl::Event verwenden und darauf ein .wait() aufrufen.
Ergebnisse holen
Die Threads des Kernelaufrufs schreiben ihre Ergebnisse in den Puffer outGPU. Das Kopieren der Ergebnisse aus diesem Puffer in den Hostspeicher geschieht analog zum Befüllen im Abschnitt “Daten kopieren” mittels enqueueReadBuffer(). Da der Kernel in uints geschrieben hat, müssen wir noch etwas aufräumen und auf der CPU das Array in ein Feld von uchars umwandeln (ab Zeile 124).
Der Beispielcode
Den kompletten Quellcode der Anwendung, deren wesentlichen Teil Listing 1 darstellt, finden Sie auf der Heft-DVD sowie unserer Website im Tarball convolucl.tar.gz. Der Einfachheit wurde der Code gegen die frei erhältliche Libpng [4] gelinkt, die hier zum Schreiben und Lesen von Graustufen-PNGs dient.
Nach dem Auspacken des Quellcodes und der Übersetzung mittels make all können Sie beliebige Graustufen-PNGs mit den mitgelieferten Kerneln falten. Die Aufrufsyntax lautet:
$ convolucl eingabe.png ausgabe.png [kernel-index]
Rufen Sie convolucl ohne Parameter auf, dann erhalten Sie eine Auflistung aller verfügbaren Faltungskernel (Listing 2). In den Abbildungen im ersten Teil dieses Artikels waren Ergebnisse dieser Faltungen zu sehen.
Listing 2
# convolucl 0 Sobel 1 Gauss 5x5 2 Gauss 12x12 3 Mean 3x3 4 Mean 5x5 5 Emboss 6 Sharpen 7 Motion blur
Evaluation
Die Effizienz der Implementation haben wir auf zwei Testsystemen ermittelt, deren Spezifikationen Sie in der Tabelle “Testsysteme” finden. Als Betriebssystem kam jeweils Ubuntu 10.10 (64 Bit) zum Einsatz, als Compiler G++ 4.4.5. Als Testbilder dienten uns drei Skalierungen des Linux-Maskottchens Tux mit den Maßen 200×235 (“Tux klein”, 2000×2353 (“Tux”) und 4000×4706 Pixel (“Tux groß”). Wir maßen die Laufzeiten für jeden oben genannten Faltungskernel.
Testsysteme
| System 1 | System 2 | |
|---|---|---|
| Typ | Desktop (No-name) | Notebook (Samsung R70) |
| CPU | AMD Athlon II X4 620 | Intel Core2 Duo T7300 |
| GPU | ATI Radeon HD4870 (1024 MByte) | Nvidia 8600M GS (512 MByte) |
| Treiber | Catalyst 10.10 | Nvidia 260.19.29 |
| Toolkit | ATI Stream SDK 2.3 | Cuda Toolkit 3.2.16 |
Die CPU-Implementierung ließen wir einmal ohne Compileroptimierung und einmal mit -O3 kompilieren. Bei der GPU-Implementierung maßen wir die Kompilierung des OpenCL-Kernels (Build), die I/O-Zeiten (Kopieren der Daten und Umwandlung), die Kernellaufzeit und die Gesamtzeit gemessen. Diese entspricht der vom Host aus messbaren Zeit für den Aufruf von convolveGPU().
Die Just-in-Time-Kompilierung des OpenCL-Kernels benötigte auf dem Desktop-Rechner im Mittel 117 ms, auf dem Notebook 285ms. Offensichtlich benötigt also das Kompilieren der Faltungskernel schon eine so lange Zeit, dass sich das Berechnen kleiner Bildern auf der Grafikkarte schon aus diesem Grund nicht lohnt. Bei mehreren Faltungen pro Programmaufruf – mehrfach pro Bild oder mehrere unterschiedliche Bilder – so fällt der Overhead durch das Kompilieren nicht so sehr ins Gewicht.
Interessanterweise benötigt das Kompilieren mit dem AMD Stream SDK weniger als die Hälfte der Zeit, die das NVIDIA Toolkit in Anspruch nimmt. Wie die Tabelle “I/O-Zeiten” verdeutlicht, verhalten sich die Grafikkarten auch in Bezug auf das Hin- und Herkopieren der Daten unterschiedlich. Die vermutete Monotonie der Übertragungszeit in Abhängigkeit von der Datenmenge bestätigt sich. Die Tabelle “Kernellaufzeiten” zeigt, das diese wie zu erwarten steigen sie mit der Größe des Faltungskernels, aber auch mit der Größe des Eingabebildes steigen.
I/O-Zeiten
| Bild | System 1 | System 2 |
|---|---|---|
| Tux klein | 24 ms | 5 ms |
| Tux | 83 ms | 46 ms |
| Tux groß | 216 ms | 175 ms |
Kernellaufzeiten
| Bild | Kernel | Kernelgröße | System 1 | System 2 |
|---|---|---|---|---|
| Tux klein | Sobel | 3×3 | 60 ms | 2 ms |
| Tux klein | Gauß | 5×5 | 60 ms | 6 ms |
| Tux klein | Motion Blur | 9×9 | 63 ms | 19 ms |
| Tux klein | Gauß | 12×12 | 62 ms | 33 ms |
| Tux | Sobel | 3×3 | 75 ms | 242 ms |
| Tux | Gauß | 5×5 | 91 ms | 647 ms |
| Tux | Motion Blur | 9×9 | 142 ms | 2024 ms |
| Tux | Gauß | 12×12 | 189 ms | 3551 ms |
| Tux groß | Sobel | 3×3 | 124 ms | 961 ms |
| Tux groß | Gauß | 5×5 | 186 ms | 2562 ms |
| Tux groß | Motion Blur | 9×9 | 372 ms | 8119 ms |
| Tux groß | Gauß | 12×12 | 566 ms | 14296 ms |
| Laufzeiten des OpenCL Kernels für drei Bildskalierungen und verschieden große Faltungskernel. | ||||
Nachdem wir ein Gefühl für die Laufzeiten der Komponenten auf der GPU bekommen haben, vergleichen wir die Gesamtlaufzeit der GPU-Implementierung (mit und ohne Kompilierung des Kernels) mit den CPU-Implementierungen (Tabelle “CPU vs. GPU total”).
CPU vs. GPU total
| System 1 | System 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CPU | GPU | CPU | GPU | |||||||
| Bild | Kernel | Kernelgröße | normal | -O3 |
total | ohne Build | normal | -O3 |
total | ohne Build |
| Tux klein | Sobel | 3×3 | 12 ms | 4 ms | 362 ms | 245 ms | 7 ms | 5 ms | 440 ms | 155 ms |
| Tux klein | Gauß | 5×5 | 11 ms | 9 ms | 334 ms | 217 ms | 12 ms | 5 ms | 401 ms | 116 ms |
| Tux klein | Motion Blur | 9×9 | 35 ms | 10 ms | 335 ms | 218 ms | 35 ms | 14 ms | 411 ms | 126 ms |
| Tux klein | Gauß | 12×12 | 52 ms | 21 ms | 332 ms | 215 ms | 59 ms | 24 ms | 429 ms | 144 ms |
| Tux | Sobel | 3×3 | 442 ms | 117 ms | 407 ms | 290 ms | 550 ms | 173 ms | 730 ms | 445 ms |
| Tux | Gauß | 5×5 | 1085 ms | 296 ms | 426 ms | 309 ms | 1261 ms | 465 ms | 1081 ms | 796 ms |
| Tux | Motion Blur | 9×9 | 3082 ms | 817 ms | 470 ms | 353 ms | 3714 ms | 1511 ms | 2456 ms | 2171 ms |
| Tux | Gauß | 12×12 | 5706 ms | 1417 ms | 551 ms | 434 ms | 6423 ms | 2626 ms | 3993 ms | 3708 ms |
| Tux groß | Sobel | 3×3 | 1774 ms | 473 ms | 638 ms | 521 ms | 2205 ms | 695 ms | 1969 ms | 1684 ms |
| Tux groß | Gauß | 5×5 | 4372 ms | 1185 ms | 703 ms | 586 ms | 5051 ms | 1859 ms | 3569 ms | 3284 ms |
| Tux groß | Motion Blur | 9×9 | 12412 ms | 3277 ms | 847 ms | 730 ms | 14883 ms | 6068 ms | 9121 ms | 8836 ms |
| Tux groß | Gauß | 12×12 | 22909 ms | 5690 ms | 1102 ms | 985 ms | 25783 ms | 10550 ms | 15300 ms | 15015 ms |
| Vergleich der Laufzeiten der CPU-Implementierung mit der Gesamtlaufzeit der GPU-Implementierung. | ||||||||||
Für das kleinste Bild benötigt die GPU-Implementierung auf beiden System erheblich mehr Rechenzeit als die CPU-Implementierung (Abbildung 3). Das dürfte sich auch bei zukünftigen GPU-Generationen nicht ändern, denn gegenüber der CPU-Variante fällt hier ein erheblicher Overhead durch das Kompilieren des Kernels und das Kopieren der Daten an. Dieser lässt sich nur durch hinreichend viel rechenaufwändige Parallelverarbeitung wieder wett machen. Selbst wenn man das Kompilieren des Faltungskernels nicht mit in die Laufzeit der GPU einbezieht, bleibt die GPU-Implementierung immer noch um einen Faktor zwischen 4 bis 175 langsamer (System 1).
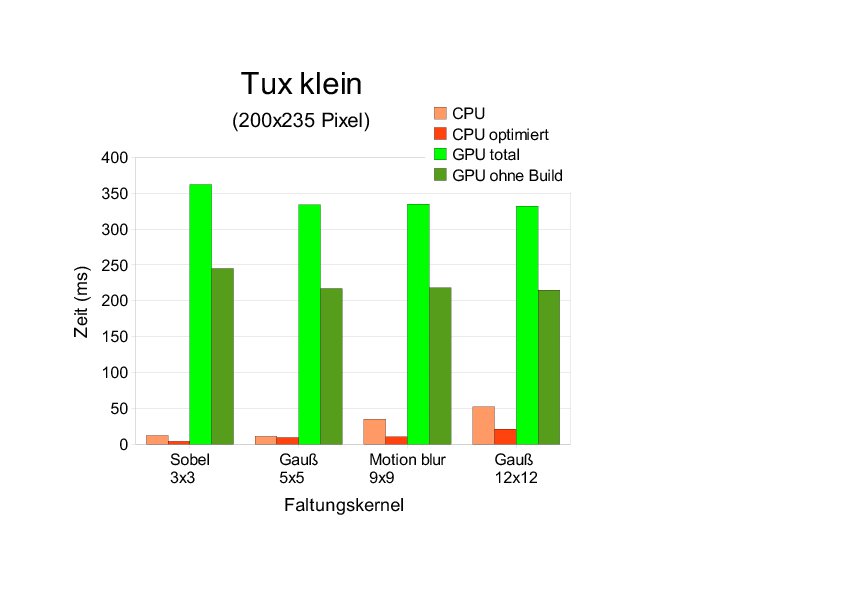
Abbildung 3: Vergleich der Laufzeiten von CPU und GPU auf System 1 für das kleinste Eingabebild und verschieden große Faltungskernel.
Für das mittlere Bild dagegen sparen wir auf System 1 gegenüber der nicht optimierten CPU-Variante bei der Faltung mit einem beliebigen Kernel bereits Zeit ein. Verglichen mit dem -O3-CPU-Binary allerdings ergibt sich lediglich bei großen Faltungskerneln (Gauß 12×12, Motion Blur) ein Zeitgewinn, der dann aber durchaus einen Faktor 10 erreichen kann (Abbildung 4).
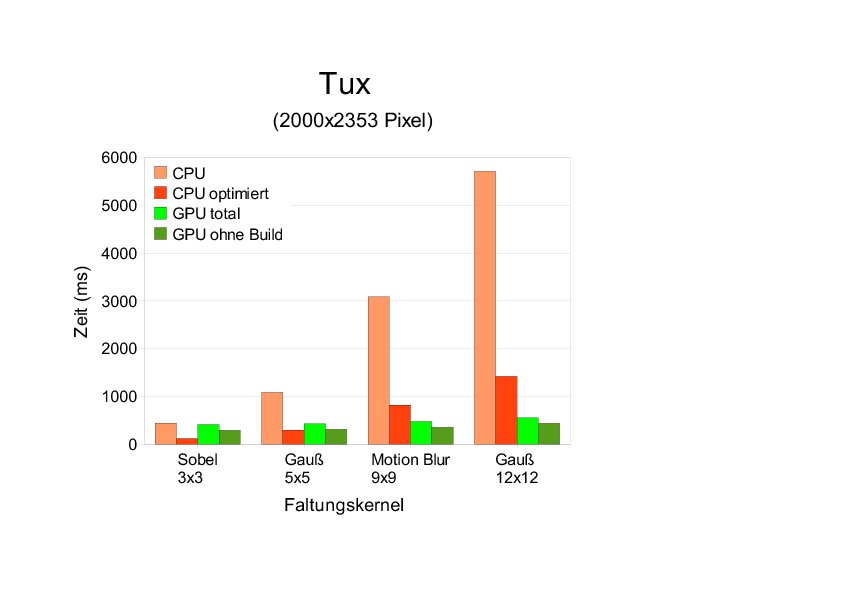
Abbildung 4: Vergleich der Laufzeiten von CPU und GPU auf System 1 für das mittelgroße Eingabebild und verschieden große Faltungskernel.
Beim größten Bild (rund 16 Megapixel) erhöht sich der Zeitgewinn weiter: Beim großen Gauß-Kernel resultiert daraus eine Beschleunigung um den Faktor 21 (gegenüber dem nicht optimierten Binary) beziehungsweise 5 (-O3). Für sehr kleine Faltungskernel allerdings bleibt die Berechnung auf der GPU weiterhin langsamer als jene auf der CPU mit einem optimierten Binary (Abbildung 5).
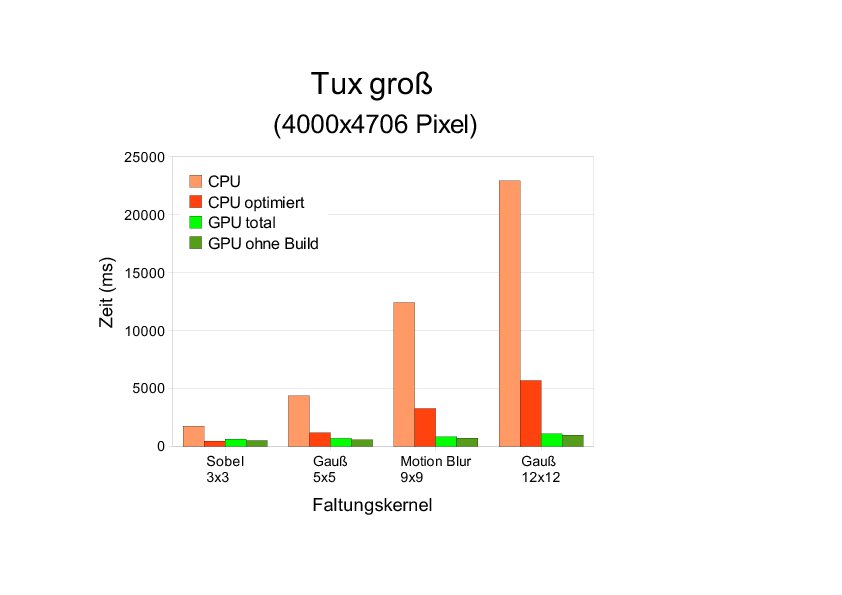
Abbildung 5: Vergleich der Laufzeiten von CPU und GPU auf System 1 für das größte Eingabebild und verschieden große Faltungskernel.
Zusammenfassung und Ausblick
Wie unser kleines Experiment ergeben hat, bringt das Ausführen auf der GPU nicht in jedem Fall einen Zeitgewinn mit sich, sondern nur für spezielle Fälle (große Faltungskernel) und große Datenmengen. Das liegt zum einen am Zeitverlust durch den Just-in-Time-Compiler für die OpenCL Kernel, zum anderen müssen die Daten erst teuer ins GPU-RAM kopiert werden.
Der vorgestellte Code verzichtet bewusst auf einige Optimierungsmöglichkeiten, um das Problem anschaulich zu halten und einen soweit möglich unkomplizierten Einstieg in OpenCL zu geben. Beispielsweise könnte man die Matrixelemente des Faltungskernels, statt sie bei jedem Zugriff neu aus dem globalen Speicher zu holen, vorab in den lokalen Speicher holen, den sich die Threads der bereits erwähnten Work Groups teilen. Hier kann der Zugriff um beinahe drei Größenordnungen schneller erfolgen. Daneben ließe sich durch eine Beschränkung des Problems auf separierbare Kernel die Bildfaltung selbst weiter optimieren.
Bei weiterem Interesse empfiehlt sich das Studium des NVIDIA OpenCL Programming Guide [2], der auch auf die Hardware-Architektur von Grafikkarten eingeht, und der mitgelieferten Beispiele in den SDKs von ATI und Nvidia. Unentbehrlich für angehende OpenCL-Entwickler sind außerdem die OpenCL-Spezifikation [5] sowie die Dokumentation der C++-Bindings [6].
Infos
[1] Download des Beispiel-Quellcodes: http://www.linux-user.de/Downloads/2011/08/
[2] NVIDIA OpenCL Programming Guide: http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_OpenCL_ProgrammingGuide.pdf
[3] OpenCL-Extension cl_khr_byte_addressable_store: http://www.khronos.org/registry/cl/sdk/1.0/docs/man/xhtml/cl_khr_byte_addressable_store.html
[4] Libpng: http://www.libpng.org/pub/png/libpng.html
[5] OpenCL-Dokumentation: http://www.khronos.org/registry/cl/sdk/1.1/docs/man/xhtml/
[6] Dokumentation der OpenCL-C++-Bindings: http://www.khronos.org/registry/cl/specs/opencl-cplusplus-1.1.pdf





