

Über die Dienste von Nepomuk durchsuchen Sie nicht nur flott die Dateien auf Ihrem Rechner: Der semantische Desktop von KDE SC 4.4 hat weit mehr zu bieten.
“I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computer”, fasste der Urvater des World Wide Web, Tim Berners-Lee, 1999 seine Vorstellung von der Zukunft des Netzes zusammen. Gut zehn Jahre später ist von dieser Vision der semantischen, das heißt auf Bedeutung basierenden Struktur des Web noch nicht sehr viel zu sehen. Auch auf dem lokalen Computer beherrschen weiterhin traditionelle Dateisysteme die Oberfläche.
Die Datenmenge, mit der sich die Computerbenutzer konfrontiert sehen, steigt ständig. Klassische Dateisysteme bieten Daten in einer hierarchischen Struktur an und organisieren sie dazu in Ordnern. Dabei speichern sie Metadaten nur auf Dateiebene und oft nur individuell – man muss sie also für jede Datei einzeln abrufen. Diese Struktur trägt weder der Zusammengehörigkeit von Dateien Rechnung, noch dem Kontext, in dem die Daten für den Benutzer relevant sind.
Das von der Europäischen Gemeinschaft initiierte Forschungsprojekt Nepomuk [1] hat sich das Ziel gesetzt, die Daten des Benutzers zu vereinen. Dabei soll eine persönliche Datenquelle dem Datenwirrwarr Struktur verleihen, die auf Konzepten basiert, die für den Benutzer zugänglicher ausfallen. Zudem soll Nepomuk es ermöglichen, verschiedene Datenquellen (zum Beispiel Dateien) miteinander thematisch zu verlinken. Das soll den Daten des Benutzers wortwörtlich Bedeutung hinzufügen.
Im Rahmen des Nepomuk-Forschungsprojekts arbeiteten die Entwickler an einer ersten Implementation des semantischen Desktops innerhalb der KDE Software Compilation. Schon mit dem Release von KDE 4.0 kamen die Basics in der Entwicklungsplattform mit. Für den Benutzer war hier allerdings noch nicht sehr viel zu holen, da sich die Neuerungen zum größten Teil auf neue Funktionen in KDE’s Entwickler-Kit beschränkten.
Metadaten
Beim semantischen Desktop geht um Metadaten, also solche Informationen, die der Datei angeheftet werden. Dabei kann es sich um einen Kommentar handeln, eine Bewertung oder ein Schlagwort. Metadaten beschränken sich allerdings nicht auf diese allgemeinen Attribute. Für ein digitales Photo umfassen sie zum Beispiel typischerweise auch Zeitpunkt und Auflösung der Aufnahme, die Belichtungszeit, die Blende und vieles mehr.
Solche Metadaten lassen sich nicht nur Dateien anheften, sondern auch anderen Artefakten, wie zum Beispiel URLs, Projekten, Personendaten, und so fort. Welche Arten Ressourcen es dazu gibt,legen die auf Freedesktop.org entwickelten Ontologien [2] in Form eines offenen Standards fest. Diese Ontologien definieren zum einen semantische Ressourcen und zum anderen, welche Metadaten für diese jeweils sinnvoll sind – Sie normalisieren also das Format verschiedener Ressourcen.
Ein interessanter Aspekt der Metadaten im Sinne des semantischen Desktops: Man kann auch Ressourcen selbst miteinander verbinden. So entsteht quasi ein semantisches Netz, das sich über die Informationen legt und den Zugriff darauf erlaubt.
Ontologien – was ist was?
Um mit Dokumenten auf der Abstraktionsebene des semantischen Desktops umgehen zu können, muss man sich auf bestimmte Definitionen einigen, um den Datenaustausch und die inhaltliche Verlinkung erst einmal möglich zu machen. Dazu legen die Nepomuk-Ontologien Konzepte wie Person, Nachricht und Aufgabe sowie deren Relationen fest.
Um eine Person abzubilden, gibt es in Nepomuk die NCO-Ontologie. Sie bildet nicht nur Adressbucheinträge ab, sondern unter anderem auch Gesprächspartner im Chat und Kontakte in sozialen Netzwerken. Mittlerweile verwenden auch andere Projekte die Nepomuk-Ontologien, wie zum Beispiel die Suchmaschine Tracker. Das erlaubt prinzipiell einen einfachen Datenaustausch zwischen diesen Programmen.
Inkrementelle Entwicklung
In den auf Version 4.0 folgenden Releases der KDE Software Compilation konnten Sie schrittweise verfolgen, wie Nepomuk sich weiterentwickelt und die KDE-Programme mehr und mehr von den Möglichkeiten profitieren, die Nepomuk bietet. So hielt vor rund einem Jahr mit KDE 4.2 beinahe unbemerkt ein Plugin für KRunner Einzug, also für Plasmas Mini-Kommandozeile. Es listete alle Dateien auf, die zu einem Suchbegriff gefunden wurden, sodass man auf einmal an den gewohnten Stellen erweiterte Funktionalität finden konnte.
Die Achillesferse der KDE-Implementation von Nepomuk [3] – und damit des semantischen Desktops in KDE – bildete jedoch die Performance. Nepomuk kümmert sich nicht selbst um das Speichern der Daten, sondern überlässt dies einer speziell dafür entwickelten Datenbank. KDE 4.3 lieferte dabei zwei Optionen mit: Redland und Sesame2.
Das in C++ geschriebene Redland zeigte sich dabei wenig leistungsfähig, was zu langen Suchanfragen führte und damit effektiv die Brauchbarkeit von Nepomuk in vielen Fällen stark beschnitt. Das Sesame2-Speicherbackend läuft zwar um Einiges schneller, erzielte aber trotzdem noch nicht die für viele Szenarios benötigte Performance. Außerdem verursachte es einige Kopfschmerzen beim Paketieren, da sich in der in Java geschriebenen Sesame2-Datenbank binäre Dateien mit unklarer Lizenz befanden.
Mit KDE SC 4.4 liefert das Team um Sebastian Trüg, dem KDE-Hauptentwickler von Nepomuk, jedoch ein neues, auf der RDF-Datenbank Virtuoso [4] basierendes Speicher-Backend mit. Virtuoso räumt die Probleme sowohl hinsichtlich der Lizenz und Paketierung als auch insbesondere der Performance weitgehend aus. Damit macht es den Weg frei, die Technologien rund um den semantischen Desktop weiter umzusetzen.
Nepomuk in KDE SC 4.4
In den Systemeinstellungen finden sie unter dem Punkt Erweitert die Einstellungen für die Desktopsuche: Hier schalten Sie die semantischen Funktionen ein (Abbildung 1). Aktivieren Sie den Datei-Indexer Strigi [5], indiziert er auch Daten auf der Festplatte. Im Reiter Datei-Indizierung finden Sie die genauen Pfade, die er einbezieht. Schalten Sie die Festplattenindizierung ab, können Sie trotzdem weiter auf die Nepomuk-Datenbank zugreifen. Allerdings steht dann der Datei-Index in den den Resultaten der Desktopsuche nicht mehr mit aktuellen Daten als Datenquelle zur Verfügung.
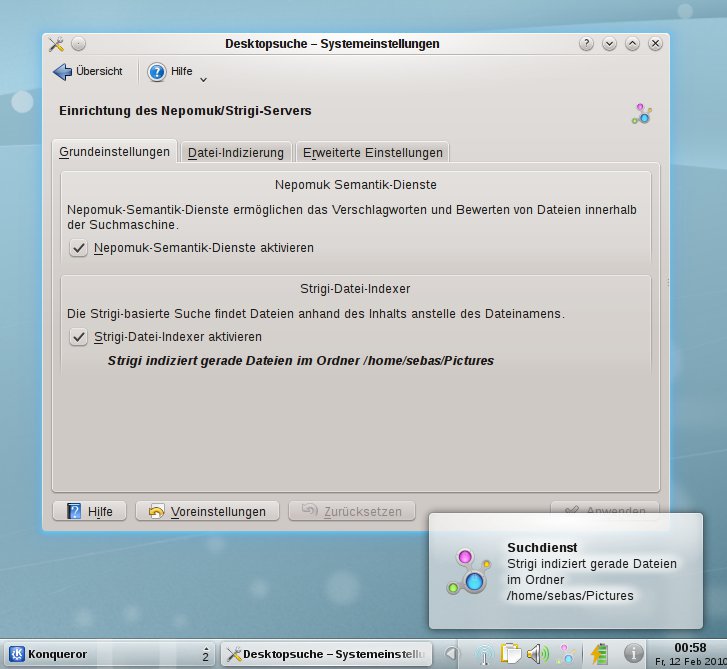
Abbildung 1: In den Systemeinstellungen des KDE-Desktops treffen Sie die Vorgaben für die Desktopsuche via Nepomuk und Strigi.
Die Nepomuk-Dienste lassen sich auch komplett abschalten. In den Applikationen und in der Arbeitsumgebung Plasma stehen dann allerdings Features wie Annotation, Bewertung und Tagging nicht mehr zur Verfügung. Da nicht alle Linux-Distributionen den semantischen Desktop und damit die Suchfunktionen in der Voreinstellung einschalten, lohnt sich ein Blick in die Einstellungen.
Neu in KDE SC 4.4 ist die Option, Daten auf Wechselmedien zu indizieren. So können Sie nun auch Dokumente beispielsweise auf einem USB-Stick automatisch scannen lassen, sodass diese in der Desktopsuche als mögliche Resultate zur Verfügung stehen. Diese Dateien erscheinen dabei nur dann in den Resultaten, wenn der entsprechende Datenträger auch verfügbar ist. Dies entscheidet der Desktop anhand eines Identifikationsstrings für das Medium. Intern hilft hier KDEs Hardware-Framework Solid [6]. Benutzen sie Nepomuk für größere Datenmengen, empfiehlt es sich in den erweiterten Einstellungen Nepomuk etwas mehr Speicher zuzugestehen.
Das Indizieren geht recht flott, sodass es auch bei größeren Datenmengen kein Problem darstellt. Wie lange es genau dauert, hängt maßgeblich von der Anzahl und Art der Dateien ab, die Sie in den Suchindex aufnehmen wollen. Bei aktivem Indexer erscheint im Systemabschnitt der Kontrollleiste das Nepomuk-Icon, das automatisch wieder verschwindet, wenn der Indexer nicht arbeitet. Über das Kontextmenü können sie den Indexer auch zeitweise deaktivieren, falls er ihnen doch mal in den Weg kommen sollte.
Desktopsuche à la KDE
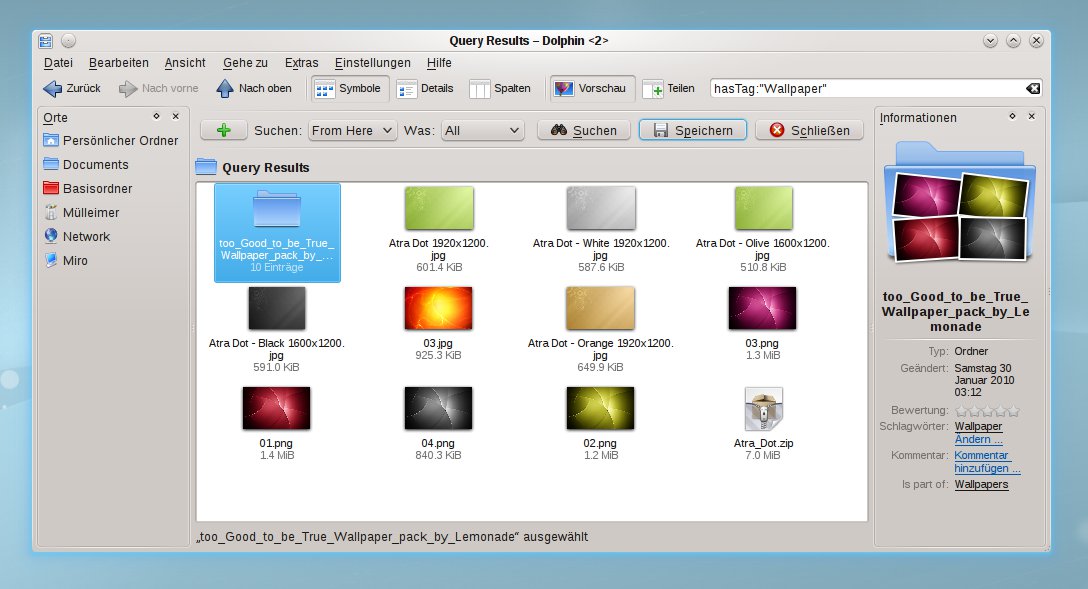
Starten Sie unter KDE SC 4.4 den Dateimanager Dolphin, so bemerken Sie im rechten oberen Teil die neue Suchzeile. Diese erweiterte Eingabezeile assistiert ihnen dabei, Suchaufgaben zu definieren. Tippen Sie hier einen Begriff ein, erhalten Sie hier Optionen angeboten – etwa, nach einem Tag zu suchen. Eine Vervollständigung vergleicht dabei die Eingabe bereits während des Eintippens mit vorhandenen Schlagworten. So genügt es beispielsweise schon, wall zu tippen, um Bilder zu finden, die sie vorher als Wallpaper markiert haben (Abbildung 2).
Wallpaper markiert haben.” width=”300″ height=”162″ />
Abbildung 2: Über die Schlagwortsuche finden Sie schnell alle Bilder, die Sie beispielsweise alsWallpaper markiert haben.Geben sie einen Begriff ein und bestätigen sie diesen mit der Eingabetaste, dann sucht Dolphin nach Dateien, in denen dieser Begriff vorkommt. Sofern Sie in den Systemeinstellungen die Volltextsuche aktiviert haben, erfolgt die Suche auch innerhalb von Dateien. Sie verfeinern die Suche weiter, indem Sie auf den Schalter mit dem Pluszeichen klicken, woraufhin Ihnen Nepomuk weitere Suchkriterien anbietet. Setzen Sie den Typ auf Text, findet die Suche nicht etwa nur Dateien des Typs plain/text, sondern beispielsweise auch ODF- und PDF-Dokumente.
In vielen Fällen wollen Sie Suchaufgaben mehr als einmal verwenden. Klicken Sie dazu auf Speichern, um diese Suchaufgabe in Ihre Orte aufzunehmen. Dieser Mechanismus ermöglicht es, Dokumente auch einfach aus anderen Programmen zu öffnen. Sie finden die als Ort gespeicherten Suchen in der Seitenleiste des Datei-Öffnen-Dialogs. Dabei speichert das System selbstverständlich nicht etwa die Ergebnisse, sondern vielmehr die Suchaufgabe: Das ermöglicht es, die Suche stets auf dem neusten Stand auszuführen.
Dabei handelt ein virtuelles KIO-Dateisystem die Suche unabhängig vom aufrufenden Programm ab. Der Desktop speichert Ihre Suchanfrage in den Orten in Form einer nepomuksearch:/-URL, die wiederum auf eine SPARQL-Query verweist. Ein interner Benachrichtigungsmechanismus aktualisiert dabei die Suchaufgabe während der Wiedergabe. Tippen Sie doch mal in die Adresszeile von Dolphin nepomuksearch://linux und schauen Sie sich an, was daraufhin passiert (Abbildung 3).
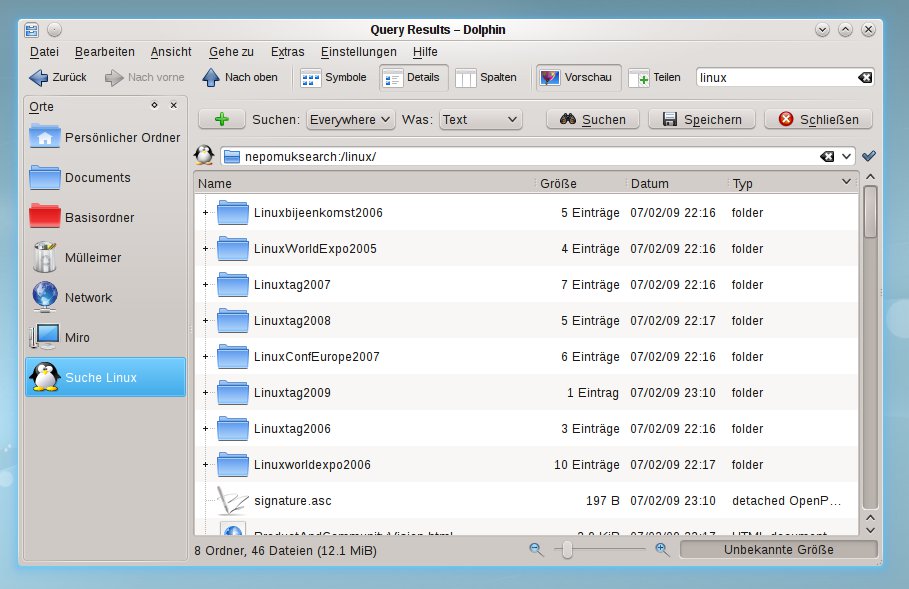
Abbildung 3: Eine Desktopsuche mit Nepomuk lässt sich über die entsprechende URL auch direkt in der Adresszeile des Dateimanagers anstoßen.
Die Integration der Desktopsuche auf Dateimanagementebene erweist sich dabei als besonders flexibel, wenn Sie bestimmte Dokumente in einem größeren Verzeichnisbaum suchen möchten. Während Sie mit Dolphin durch ihre Daten surfen, können sie von dort aus auch direkt eine Suche starten. In der Suchen-Ausklappbox beschränken Sie die Suche bei Bedarf auf ihre Position im Verzeichnisbaum. Weitere Suchkritierien, wie etwa den Dateityp, fügen Sie bequem über den Schalter mit dem Plus-Symbol hinzu. Auch das Datum der letzten Änderung können Sie hier genauer angeben, um so beispielsweise länger nicht bearbeitete Dateien aus den Resultaten auszuschließen. Daneben beschränken Sie hier auch die Suche auf Resultate, die einer minimale Bewertung entsprechen. Eine schicke Dreingabe bei der Wiedergabe stellt Dolphins Gruppierungsoption dar, die Sie über das Menü Ansicht erreichen.
In Dolphins Seitenleiste, die Sie mit [F11] anzeigen lassen, finden sie einige zur Datei gespeicherte Metadaten. Hier vergeben Sie auch bequem ein Schlagwort oder einen Kommentar für eine oder mehrere Dateien (Abbildung 4). Um die Bewertung zu ändern, klicken Sie auf die Reihe mit den fünf Sternen. Dabei dürfen Sie auch halbe Sterne vergeben, die Bewertung speichert Nepomuk intern als Wert zwischen Eins und Zehn.
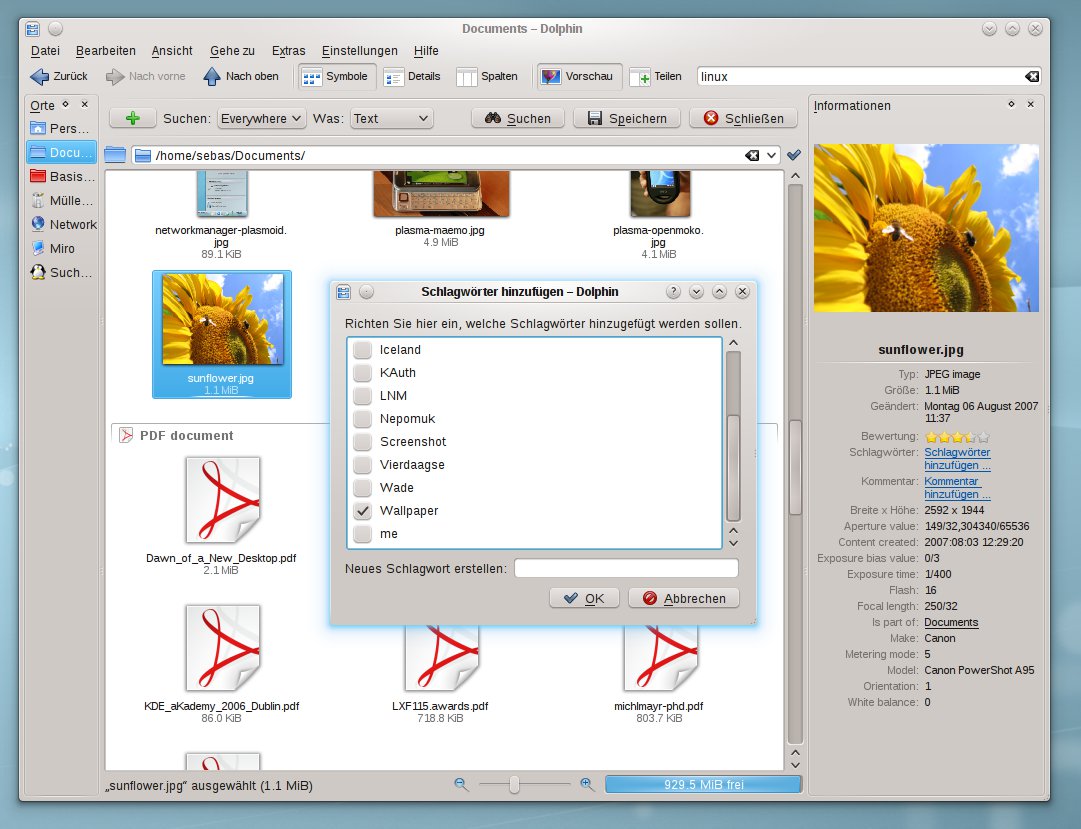
Abbildung 4: Über Dolphin greifen Sie direkt auf die Metadaten einer Datei zu und können diese bequem anzeigen und bearbeiten.
Der schnelle Zugriff auf die Suchergebnisse erweist sich auch im Dialog Datei öffnen als sehr praktisch. In der Seitenleiste finden sie hier die Orte – und damit auch die gespeicherten Suchanfragen. Statt sich zeitraubend durch Verzeichnisbäume zu hangeln, um bestimmte Dateien zu finden, nutzen Sie hier voreingestellte Suchanfragen (Abbildung 5). So öffnen Sie auch komfortabel mehrere zusammengehörende Dateien gleichzeitig, auch wenn diese aus verschiedenen Verzeichnissen stammen. Auf dieses Feature werden Sie schon bald nicht mehr verzichten wollen.
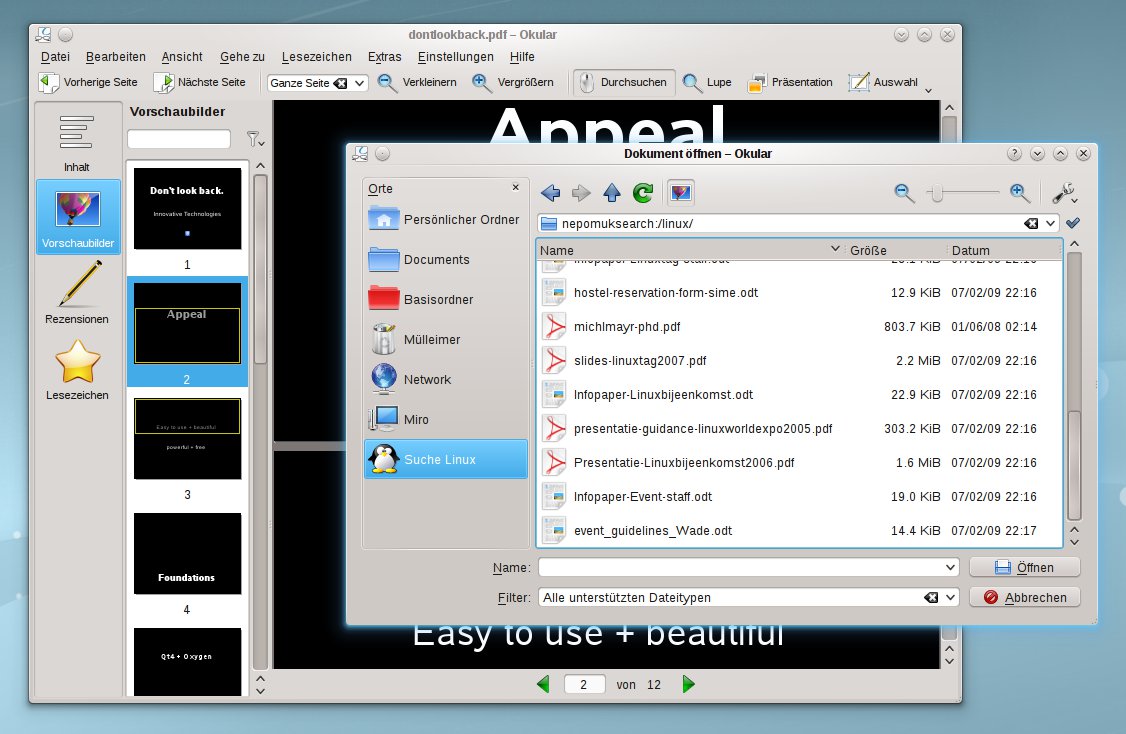
Datei öffnen heraus.” width=”300″ height=”196″ />
Abbildung 5: Die Desktopsuche lässt sich nicht nur im Dateimanager anstoßen, sondern auch in jeder Anwendung aus dem DialogDatei öffnen heraus.Kreativ mit Plasma
Diese tiefgreifende Integration des semantischen Desktops erlaubt Ihnen auch etwas kreativere Möglichkeiten im Umgang mit ihren Dateien. Legen Sie sich doch mal ein Ordneransicht-Miniprogramm auf den Desktop und richten Sie es auf eine nepomuksearch:/-URL – oder gleich auf eine ihrer als Ort gespeicherten Suchanfragen (Abbildung 6).
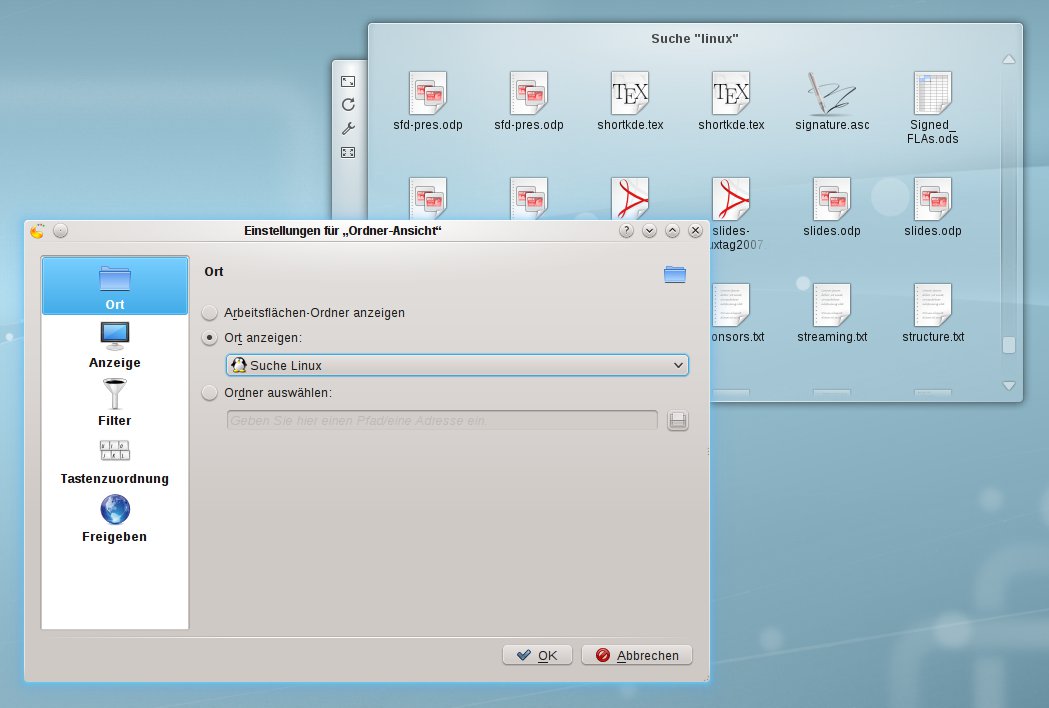
Abbildung 6: Nepomuk bringt bei Bedarf über Plasmoiden die semantische Suche auch direkt auf die Desktopoberfläche.
In Plasma 4.4 griffen die KDE Entwickler nochmal in die Trickkiste und haben das Drag & Drop von Daten auf den Desktop erweitert. Schon in KDE 4.3 konnte man lokale Links auf den Desktop ziehen und dort ablegen, um damit ein Ordneransicht-Miniprogramm zu erstellen, oder eine Textdatei auf den Desktop legen, um einen Notizzettel mit dem Text der Datei zu erstellen. Dieser Mechanismus bietet eine sehr natürliche Umgangweise mit dem Desktop, da Sie nicht nachdenken müssen, welches Miniprogramm Sie gerade benutzen, sondern einfach Daten auf dem Desktop ablegen, wobei Plasma dazu ein passendes Miniprogramm erstellt.
Unter der Haube
Das Nepomuk-Framework in KDE bietet in erster Linie eine Programmierschnittstelle (API), die es Entwicklern erlaubt, bestimmte Einträge in der Nepomuk-Datenbank zu finden und neue Objekte anzulegen, um diese mit Metadaten zu bereichern. Diese Schnittstelle dient gleichzeitig als Abstraktionsschicht für Funktionen, die den semantischen Desktop ausmachen.
Intern abstrahiert die Nepomuk-API in KDE den Zugriff auf und das Suchen nach Metadaten. Über verschiedene Backends lässt sich dabei die Speichermethode kontrollieren oder auch komplett austauschen. Nepomuk benutzt dabei die Soprano-Bibliothek, die das Speicherinterface standardisiert und in einer für Qt-Entwickler bekannten Art anbietet. Darauf setzen auf höherem Niveau dann die Aufrufe und Manipulationen der Nepomuk-Datenbank auf, automatisiert von den Applikationen oder angestoßen durch Aktionen des Benutzers.
Einen interessanten Aspekt des semantischen Frameworks stellt die Desktopsuche dar. In der KDE-Softwaresammlung integriert sie sich in Nepomuk – bei den Index-Daten von Dateien handelt es sich schließlich auch um eine Art Metadaten, und gerade da soll Nepomuk ja eine Vereinheitlichung bieten. Die Indizierung übernimmt im KDE-Framework dabei die aus dem Strigi-Projekt stammende Libstreams.
Diese in C++ entwickelte Bibliothek bringt ein speicherfreundliches Indizierungstool mit, das durch seinen Aufbau auch in verschachtelten Dateien suchen kann. Speichert man also ein PDF-Dokument in einem ZIP-Container, indiziert Strigi sie genau so, als läge es ungepackt im Filesystem. Das erweist sich gerade für Dateien sehr hilfreich, die per E-Mail verschickt werden (mehr dazu später). Dieses “Eintauchen” in Dateien weicht gleichzeitig die Grenzen zwischen Dateiformaten zugunsten der Bedeutung von Daten auf – ein wichtiger Schritt.
Sehen Sie doch mithilfe des von Strigi mitgelieferten Kommandozeilenwerkzeugs xmlindexer einmal nach, welche Metadaten Strigi (und damit auch Nepomuk) so alles finden kann. Das kleine Programm scannt den Inhalt von Dateien und Ordnern und schreibt deren Metadaten im XML-Format heraus. Der Befehl xmlindexer meinphoto.jpg extrahiert so die bekannten Metadaten aus dem Photo und bindet diese an die Nepomuk-Ontologien.
Wie Sie in Listing 1 sehen, findet xmlindexer beim Indizieren des Photos viele nützliche Metadaten, den abstrakten Typ Photo, den zur Verarbeitung mit Programmen benötigten Datentyp image/jpeg, aber auch Einstellungen der Kamera, mit der das Foto geschossen wurde. Lassen sie xmlindexer ein ganzes Verzeichnis scannen, bekommen sie entsprechend mehrere file-Abschnitte mit darin enthaltenen Metadaten, sortiert nach Ontologien. Das Eintauchen in Daten können sie ausprobieren, indem sie xmlindexer auf eine ZIP-Datei loslassen: Die einzelnen Dateien im Archiv tauchen dann separat im XML-Resultat auf.
luna.sebas(~/Pictures)$ xmlindexer meinphoto.jpg <?xml version='1.0' encoding='UTF-8'?> <metadata> […] <file uri='meinphoto.jpg' mtime='1266193792'> <value name='http://www.semanticdesktop.org/ontologies/2007/01/19/nie#url'>meinphoto.jpg</value> <value name='http://www.w3.org/1999/02/22-rdf-syntax-ns#type'>http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#Photo</value> […] <value name='http://www.semanticdesktop.org/ontologies/2007/01/19/nie#mimeType'>image/jpeg</value> <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#isoSpeedRatings'>200</value> <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#orientation'>1</value> <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#flash'>16</value> <value name='http://www.semanticdesktop.org/ontologies/2007/05/10/nexif#model'>Canon EOS 450D</value> <value name='http://www.semanticdesktop.org/ontologies/2007/03/22/nfo#height'>4272</value> <value name='http://www.semanticdesktop.org/ontologies/2007/03/22/nfo#width'>2848</value> <value name='http://www.semanticdesktop.org/ontologies/2007/01/19/nie#contentCreated'>2009:08:30 14:58:33</value> […] </file> </metadata>
Ein separater Indizierungsdaemon setzt Soprano, Libstreams und die Nepomuk-Bibliothek im Rahmen des Plasma-Desktops ein, um auch tatsächlich Daten zu sammeln. Der Daemon stellt beim Start die Virtuoso-Datenbank bereit und sorgt für die Indizierung der Dateien auf dem Desktop. Der im Hintergrund laufende Nepomuk-Prozess tut dabei sein Möglichstes, um nicht aufzufallen, sondern seine Dienste weitgehend transparent zur Verfügung zu stellen. Meldet das System, dass der Benutzer gerade arbeitet, setzt er das CPU-intensive Indizieren der Daten auf der Festplatte aus. Auch im Batteriebetrieb wartet das System mit dem Erfassen möglicherweise geänderter Daten, damit die Akkulaufzeit nicht leidet.
Dabei kommt KDEs Hardware-Interface Solid zum Einsatz. Auf diese Art lässt sich plattformunabhängig bestimmen, ob die Maschine Strom sparen sollte, also eher auf die Festplatten- und Prozessorlast verzichten sollte, die der Indexlauf verursacht. Zudem arbeitet der Indexer nur im Hintergrund, solange der Anwender den Rechner gerade nicht benutzt, der PC also idle läuft. Stört der Indexer dennoch, setzen Sie ihn über das Kontextmenü des Nepomuk-Prozesses im Systemabschnitt zeitweise aus oder schalten die Indizierung über die Systemeinstellungen permanent ab.
Applikationen
Je mehr Applikationen beim Sammeln der Metadaten zusammenarbeiten, also den selben Index zum Speichern ihrer Meta-Informationen benutzen, desto attraktiver wird es für andere Applikationen, ebenfalls auf diesen Speicher zuzugreifen. Das befördert den Austausch von Informationen zwischen Applikationen und ermöglicht damit auch ergonomischere Workflows.
Der Bildbetrachter Gwenview demonstriert, dass die Integration von Metadaten auch weiter gehen kann, als nur ähnliche Dateien zu öffnen. Sobald sie im Menü Ansicht unter Vorschaubilder die Bewertung einschalten, können sie Bilder direkt im Übersichtsmodus bewerten (Abbildung 7). Dafür gibt es übrigens auch Kurzbefehle: Drücken sie beim Betrachten eines Bildes eine Zifferntaste zwischen Eins und Fünf, erhält das Bild die entsprechenden Bewertung. Auf diese Art verleihen Sie der Masse von Bildern schnell Klasse. Im Übersichtsmodus, in dem Gwenview startet, greifen Sie zudem direkt auf Schlagworte zu, sodass sie ihre Bilder auch “semantisch” betrachten können (Abbildung 8).
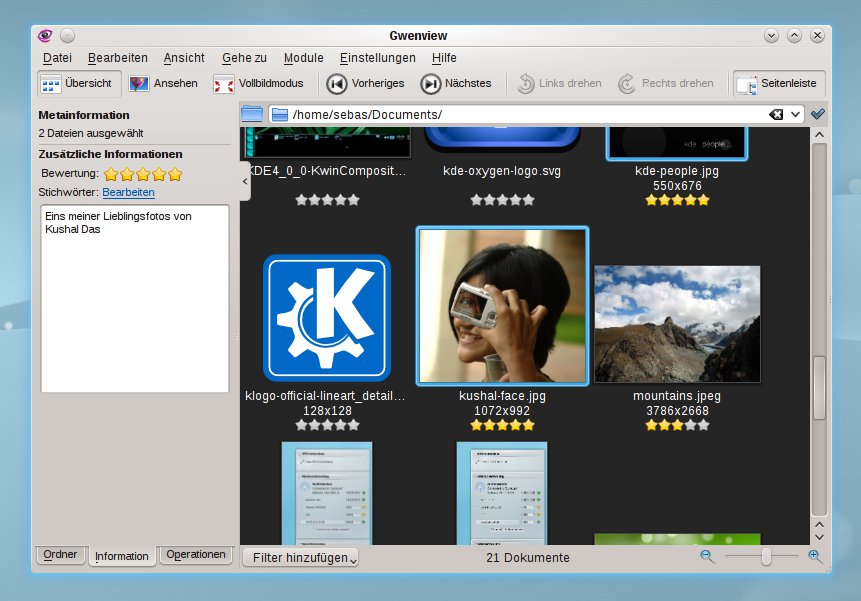
Abbildung 7: Metadaten im Bildbetrachter: In Gwenview bewerten Sie die Bilder direkt beim Betrachten.
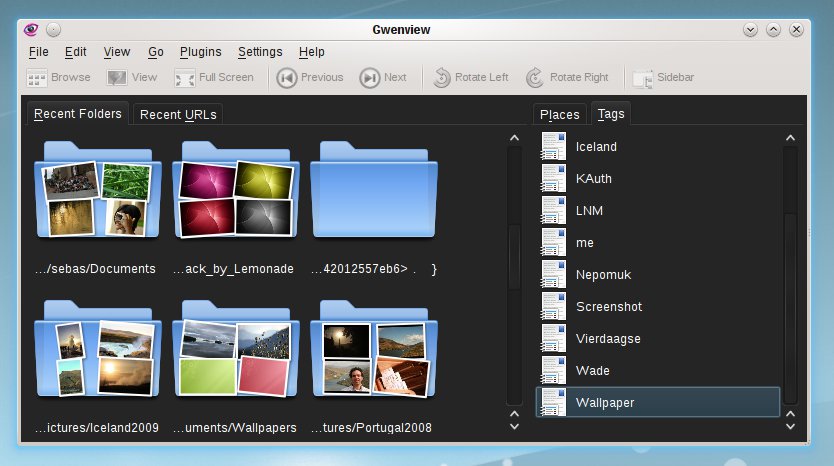
Abbildung 8: Im Übersichtsmodus präsentiert Gwenview die Bilder bei Bedarf nach Schlagworten sortiert.
Nachrichten
Die mit KDE SC 4.5 im kommenden Sommer erwartete Umstellung von Kontact auf Akonadi [7] wird die semantischen Features auch in den PIM-Bereich bringen. Akonadi übernimmt dann in der KDE Software Compilation die Rolle des Nachrichtenzentrums. Die KMail-Hacker benutzen dann die Nepomuk-Technologien zur Indizierung von E-Mails, und auch deren Attachments bleiben dabei nicht außen vor. Da die zur Datenindizierung verwendete Libstreams wie beschrieben auch die Suche in einem verschachtelten Dokument ermöglicht, untersucht sie auch Dokumente, die beispielsweise in einem gezippten Archiv einer E-Mail beiliegen. Die aus den Nachrichten extrahierten Metadaten speichert das System über Nepomuk verlinkt, sodass sich eine semantische Struktur über die Mailbox legen lässt. Das verkürzt nicht nur die Suche nach bestimmten Nachrichten, sondern ermöglicht auch die Wiedergabe von E-Mails im Kontext anderer Daten.
Sicherlich fragen Sie sich nun, ob sie dann alle Daten per Hand verlinken müssen. Diese Arbeit nehmen Ihnen die KDE-Entwickler mithilfe von Nepomuk ab – zumindest zum Teil. Die Indizierung von Daten stellt nur einen Weg dar, um Dokumente zu verlinken. Es gibt aber auch die Möglichkeit, Metadaten automatisch zu sammeln: Programme können zum Beispiel speichern, an welchen Dokumenten sie gleichzeitig arbeiten, und diese dann automatisch miteinander verbinden. Auch die Herkunft von Dokumenten lässt sich nutzen, um Dateien wertvolle Meta-Informationen zu verleihen. So werden Sie in Zukunft wohl auch sehr viel einfacher und schneller herausfinden, an wen Sie wann ein Dokument als E-Mail-Attachment verschickt haben.
Scribo natürlich
Das vom französischen Staat mitfinanziertes Forschungsprojekt NLP (“Natural Language Processing”) befasst sich mit der Analyse der menschlichen Sprache, also der Frage, wie man Texten semantische Informationen entlocken kann. Die ersten Ergebnisse, die man bereits in KDEs Quellcode-Repositories findet, erweisen sich dabei als vielversprechend. So zeigt die Testapplikation Scribo-Shell [8], wie man Texte automatisch analysieren und aus den Ergebnissen eine Liste mit sinnvollen Schlagworten und Themen generieren kann.
Zur Textanalyse kommt dabei ein Algorithmus des DERI-Instituts zum Einsatz, eines in Irland ansässigen wissenschaftlichen Partners im Nepomuk- und NLP-Projekt. Einen weiteren Ansatz bietet die Nutzung von Webservices zur Textanalyse. Die ebenfalls in Scribo Shell demonstrierte Schnittstelle OpenCalais bindet dabei einen Webservice eine umfangreiche Datenbank der Nachrichtenagentur Reuters ein und kann so Texte anhand eines großen Datenpools auseinanderpflücken. Scribo beschränkt sich jedoch nicht nur auf Text, sondern hat auch Bilder im Visier.
Hoch hinaus
Natürlich sind nicht nur Dateien interessant, sondern auch Daten, die man online speichert. Hier kommt der Groupware-Cache Akonadi ins Spiel, der mit dem KDE-Addressbuch in Version 4.4 seinen Einstand in der KDE Software Compilation feiert. Die PIM-Entwickler arbeiten derzeit hart an der Umstellung weiter Komponenten aus dem Kontact-Paket. Mit dem Release 4.5 steht für diesen Sommer wie bereits erwähnt ein auf Akonadi basierendes KMail auf dem Programm.
Die PIM-Hacker setzen dabei in Akonadi auf die Fähigkeiten Nepomuks, das die Volltextsuche in E-Mails und Attachments übernimmt. Akonadi benutzt derzeit noch eine eigene MySQL-Datenbank, doch die PIM-Entwickler denken bereits darüber nach, als Speicher-Backend ebenfalls Virtuoso zu benutzen, was sich günstig auf den Speicherverbrauch auswirken würde. Das Personal Information Management könnte dabei ganz besonders von den semantischen Funktionen profitieren – Kontakte und Identitäten lassen sich zum Beispiel hervorragend in der NCO-Ontologie normalisieren.
Akonadi spielt dabei die Rolle des Datenknechts: Es importiert und synchronisiert über Plugins verschiedene Datenquellen. Im einfachsten Fall handelt es sich bei so einer Datenquelle etwa um eine Kontakt-Visitenkarte auf der lokalen Festplatte. Es gibt aber auch Datenquellen – sogenannte Agents – die IMAP- oder Groupware-Server einbinden. Eintreffende E-Mails lassen sich so direkt indizieren. Dies ermöglicht es dann auch, virtuelle Folder anzulegen: also quasi voreingestellte Suchanfragen, die sich wie eine E-Mail-Mappe verhalten. Beim Indizieren von E-Mails bietet sich zudem die Möglichkeit, den Text auch inhaltlich zu analysieren und eventuell automatisch zu verschlagworten, oder mit anderen Nepomuk-Ressource zu verlinken.
Ausblicke
Da sich die Fähigkeiten Akonadis prinzipiell nicht auf bestimmte Datentypen beschränken, kann, man hier allerdings auch weiter denken. RSS-Feeds, Informationen aus sozialen Netzwerken oder auch Geoinformationen bieten sicherlich interessante weitere Ansatzpunkte.
Mandriva offeriert in Sachen Semantik bereits die Möglichkeit, besuchte Webseiten direkt aus dem Webbrowser heraus zu verschlagworten. Denkbar wäre hier aber auch eine Indizierung aufgerufener Websites: Wenn man sich schon die Zeit nimmt, eine Webseite zu lesen, kann sich der Computer auch die paar Millisekunden gönnen, um den Inhalt zu erfassen. Auf diese Art lassen sich die entsprechende Website später wesentlich einfacher wiederfinden.
Nepomuk bietet auf diese Weise also auch die Möglichkeit, das Web lokal semantisch einzubinden – ein Aspekt, der zu guter Letzt den Kreis zu Tim Berners-Lees Träumen vom semantischen Web schließt.
Der Autor
Sebastian Kügler (aka “sebas”) spielt gerne mit Technologie und dabei meist mit KDE, wo er an der Entwicklung des Plasma-Desktops mitarbeitet. Als Mitglied des KDE-e.V.-Vorstands, des KDE-Release-Teams und der Marketing Working Group zeichnet er auch für strategische Entscheidungen des Projekts verantwortlich.
Glossar
-
KDE Software Compilation
-
Kurz: KDE SC. Seit einen Rebranding Ende November 2009 steht der Begriff “KDE” nur noch für die KDE-Community, der von KDE herausgegebene Desktop heißt jetzt KDE SC [9].
-
KIO
-
KDE Input/Output. Virtuelles Dateisystem, das über KIO-Slaves den Anwendungen transparenten Zugriff auf verschiedenste Protokolle ermöglicht.
-
SPARQL
-
SPARQL Protocol and RDF Query Language. Vom W3C standardisierte Abfragesprache für das semantische Web.
Infos
[1] Nepomuk: http://nepomuk.semanticdesktop.org
[2] Nepomuk-Ontologien: http://www.semanticdesktop.org/ontologies/
[3] Nepomuk bei KDE: http://nepomuk.kde.org
[4] Virtuoso: http://virtuoso.openlinksw.com
[5] Strigi: http://strigi.sourceforge.net
[6] Solid: http://solid.kde.org
[7] Akonadi: http://pim.kde.org/akonadi/
[8] Scribo-Shell: http://www.scribo.ws/
[9] “Repositioning the KDE Brand”: http://dot.kde.org/2009/11/24/repositioning-kde-brand






Schade, dass im Artikel nicht auf die derzeitigen Probleme eingegangen wird.
Ich nutze die aktuelle KDE-Version 4.4.1.
Die Volltextindizierung funktioniert bei vielen PDF-Dokumenten nicht.
Der Indexer läuft fast permanent mit hoher CPU- und Speicherlast.
Obwohl sich in den meisten Verzeichnissen nichts ändert, werden diese neu indiziert und die Anzahl der indizierten Dateien schwankt zwichen 31000, 0 und 31000 .
Es gibt also noch viel zu tun.