
Unter Linux ist die Bandbreite der Verwendung von Textdateien groß: Systemkonfiguration, Systemüberwachung und Datenaustausch. Mit Awk steht ein mächtiges Werkzeug zur Verarbeitung und gezielten Veränderung dieser Dateien zur Verfügung.
Erste Schritte
Awk ist eine Skriptsprache, die speziell für die Bearbeitung und Auswertung von Textdateien konzipiert wurde. Sie stellt ein hilfreiches Tool für Systemadministratoren dar: Mit ihrer Hilfe kann zum Beispiel ein geänderter Dateipfad systemweit in einem Arbeitsschritt angepasst werden. Darüberhinaus gibt jedoch es viele weitere Einsatzmöglichkeiten. Ein Beispiel dafür ist die Auswertung von Textdateien, in denen Messdaten in tabulatorformatierten Tabellen aufgezeichnet wurden.
Ein Awk-Skript besteht aus einzelnen Befehlen oder Befehlsblöcken, die entweder nur unter bestimmten Bedingungen oder für alle Zeilen der Eingabe ausgeführt werden. Sie können die Awk-Befehle direkt von der Kommandozeile aufrufen oder in Dateien speichern.
Alle Beispieldaten zu diesem Artikel finden Sie sowohl auf der Heft-CD als auch online [1]. Um die Beispiele auszuprobieren sollten das Archiv in ein leeres Verzeichnis entpacken. Im Archiv sind zusätzliche Daten für eigene Übungen enthalten. Einige Beispiele nutzen außer Awk weitere Linux-Befehle.
Das erste Beispiel verwendet die Systemvariable $USER und begrüßt Sie zu einer kleinen Tour durch die Anwendungsmöglichkeiten von Awk:
echo $USER | awk '{print "Hallo " $1 "!"}'
Awk erhält den Inhalt von $USER als Befehlsparameter. Bei der Verarbeitung der Eingabezeile speichert Awk alle Datenfelder in den Variablen $1 bis $NF. Die Variable NF enthält die Anzahl der Datenfelder. Awk gibt den ersten übergebenen Parameter über den Befehl print zusammen mit dem Wort “Hallo” an der Standardausgabe aus. Wenn mehrere Befehle nacheinander folgen, werden sie durch ein Semikolon getrennt. Wenn Sie nur das dritte und vierte Feld einer Eingabezeile ausgeben möchten, dann schreiben Sie
echo "A B C D" | awk '{print $3 " " $4}'
Natürlich kann ein Werkzeug wie Awk auch mit mehreren Eingabezeilen umgehen. Zum Testen bietet sich das Unix-Programm Cal an. In Abbildung 1 gibt Awk die Zeilennummer, die Anzahl der Felder und zur Kontrolle die komplette Zeile ($0) aus. Die einzelnen Felder sind in den ersten Beispielen immer durch Leerzeichen oder Tabulatoren getrennt. Später werden wir auch andere Trennzeichen kennenlernen.
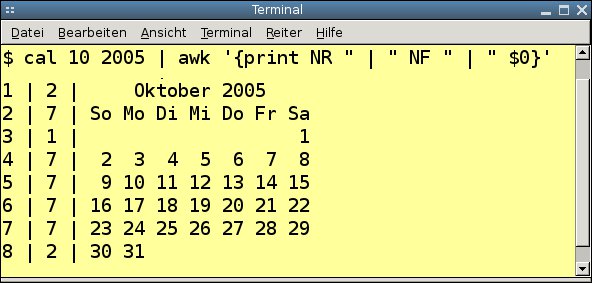
Abbildung 1: Awk kommt beim Separieren der Datenfelder auch mit mehrzeiligen Ausgaben zurecht.
Awk benutzt neben NF und NR viele weitere Variablen um die Eingabe auszuwerten und die Ausgabe zu steuern. Eine komplette Übersicht der Variablen finden Sie im Awk-Handbuch [2] sowie in der Manpage zum Programm. Mit der Option --dump-variables können Sie bei einem Awk-Aufruf die wichtigsten Variablen in eine Datei sichern und später auswerten.
Dateien auswerten
In den meisten praktischen Anwendungen geht es darum, Daten aus Dateien einzulesen und zeilenweise zu verarbeiten. Dabei können auch mehrere Dateien gleichzeitig ausgewertet werden. Der Befehl awk '{print}' /etc/group gibt alle Zeilen der Datei /etc/group aus. Diese Datei enthält auf jeder Zeile die Datenfelder Gruppenname, Gruppenpasswort, Gruppen-ID und Benutzerliste. In der Benutzerliste stehen alle Nutzer, die zu dieser Gruppe gehören.
Allerdings sind die Datenfelder in dieser Datei nicht durch Leerzeichen oder Tabulatoren, sondern durch Doppelpunkte getrennt. Zum Auslesen der Gruppennamen oder anderer Datenfelder muss das Feldtrennzeichen mit der Variablen FS) übergeben werden. Diese Variable legt fest, an welchen Trennzeichen Awk die Zeile in Felder aufteilt. Sie kann auf der Kommandozeile gesetzt werden:
awk -F':' '{print $1}' /etc/group
Als Trennzeichen können Sie auch Posix-Zeichenklassen oder reguläre Ausdrücke verwenden. Wenn Sie also mit einer Datei arbeiten, in der die Datenfelder entweder durch Kommas, Tabulatoren oder Leerzeichen getrennt sind, dann geben Sie das Trennzeichen auf folgende Weise an:
awk -F'[,[:blank:]]' '{print $1 $2 $3}' daten2.txt
Mit Awk können Sie die Reihenfolge der Felder bei der Ausgabe verändern. Wenn Sie zuerst die ID, dann den Gruppennamen und dann die Nutzer ausgeben möchten, sieht der Aufruf so aus:
awk -F':' '{print $3 " " $1 " " $4}' /etc/group
Der Befehl print ist eignet sich nur für eine unformatierte Ausgabe. Eine wesentlich übersichtlichere Anzeige Ihrer Daten erhalten Sie mit dem Befehl printf(), der wie in C funktioniert. Die Formatierungsoptionen für Zahlen und Zeichenketten sind im Awk-Handbuch [2] ausführlich beschrieben. Im nächsten Beispiel werden ID und Nutzer formatiert aufgelistet:
awk -F':' '{printf("%5s %s\n",$3,$4)}' /etc/group
Oft sollen bestimmte Eingabefelder nicht mehr in der Ausgabe enthalten sein. Hierfür können Sie dem entsprechenden Feld eine leere Zeichenkette zuweisen:
awk -F':' '{$2=""; print}' /etc/group
In der Ausgabe dieses Beispiels sind die Felder nicht mehr durch Doppelpunkte getrennt. Das liegt daran, dass Awk nicht nur ein Trennzeichen für die Ausgabe, sondern auch ein Trennzeichen für die Eingabe kennt. Sie können das Trennzeichen für die Ausgabe als Wert der Variablen OFS separat festlegen.
Muster und Musterbereiche
Bisher wurden die Awk-Befehle stets auf alle Zeilen der Eingabe angewendet. In der Praxis sollen aber häufig nur bestimmte Zeilen verarbeitet werden. das folgende Beispiel findet in der Datei /etc/group die Namen der Gruppen, die keine Mitglieder haben. Für die entsprechenden Zeilen gilt die Bedingung: Das letzte Feld des eingelesenen Datensatzes muss leer sein. Nur dann soll der Datensatz ausgegeben werden.
awk -F':' '$NF=="" {print $0}' /etc/group
Ein Awk-Skript kann prinzipiell aus den drei Teilen BEGIN-Block, Hauptteil und END-Block bestehen. Einer der Teile muss mindestens vorhanden sein. Der Hauptteil besteht aus Paaren von Bedingungen und Aktionsblöcken. Die Aktionsblöcke werden jeweils abhängig von den Bedingungen auf alle Zeilen der zu verarbeitenden Datei angewandt.
Bedingung1 { Befehlsblock1 } Bedingung2 { Befehlsblock2 }
Die Bedingungen werden in Awk auch als Pattern (Muster) bezeichnet. Als Muster oder Bedingung können Zeichenketten, reguläre Ausdrücke, logische Ausdrücke und Musterbereiche dienen. Wenn Sie sich alle Gruppen ausgeben lassen wollen, in denen Sie selbst Mitglied sind, dann können Sie den Aufruf
awk -F':' '/'"$USER"'/ {print $1}' /etc/group
verwenden. Hier expandiert die Shell den Inhalt der Systemvariablen $USER und Awk nutzt ihn als Suchmuster. Anders als in unseren ersten Beipielen arbeitet Awk nun nicht mehr alle Zeilen ab, sondern nur noch die, für die das Suchmuster zutrifft.
Reguläre Ausdrücke sind Textmuster, die in Perl, Awk und in vielen anderen Programmen und Programmiersprachen zur Anwendung kommen. Eine kurze Einführung in das Thema finden Sie beispielsweise in Ausgabe 08/2005 des LinuxUser [3], als Standardwerk zum Thema empfiehlt sich das Buch von Jeffrey Friedl [4]. Reguläre Ausdrücke verwendet Awk in der Form /RegEx/ als Suchmuster. Suchen Sie alle Gruppen, die mit dem Ausdruck “post” beginnen? Dann verwenden Sie
awk -F':' '/^post/ {print $1}' /etc/group
Sie können mehrere reguläre Ausdrücke oder Textmuster miteinander kombinieren. Dazu dienen die logischen Operatoren && (logisches Und) und || (logisches Oder). Der Aufruf
awk -F':' '/^post/ || /^root/ {print $1}' /etc/group
findet alle Zeilen, die mit root oder post beginnen. Mit der Kombination /^ABC'/ && /DEF$/ finden Sie alle Zeilen einer Datei, die mit ABC beginnen und mit DEF enden.
Musterbereiche definieren Sie durch Anfangs- und Endbedingungen, die durch ein Komma getrennt sind. Mit den folgenden beiden Befehlen werden zuerst die Zeilen 5 bis 7 und dann alle Gruppen von root bis lp aus der Eingabedatei /etc/group ausgegeben:
awk -F':' 'NR==5,NR==7 {print $0}' /etc/group
awk -F':' '/root/,/lp/ {print $1}' /etc/group
Musterbereiche kommen zur Anwendung, wenn alle Zeilen einer Datei vom Auftreten eines bestimmten Ausdrucks bis zum Auftreten eines anderen Ausdrucks verarbeiten werden sollen. Die beiden Zeilen, auf die das Start- und Endkriterium passt, werden noch ausgewertet, alle anderen Zeilen ignoriert Awk. Eine weitere Anwendung für Musterbereiche ergibt sich, wenn die Datensätze blockweise in Zeilen stehen und durch Leerzeichen getrennt sind. Folgender Musterbereich löst diese Aufgabe:
awk '/Kopfkriterium/,/^$/ {Aktionen}
Der Bereich beginnt mit dem Kopfkriterium und endet mit einer leeren Zeile. Die Endbedingung nutzt den üblichen regulären Ausdruck für eine leere Zeile: ^ steht für den Zeilenbeginn, $ für das Zeilenende. Wenn beides direkt hintereinander steht, dann trifft dieser reguläre Ausdruck nur für leere Zeilen zu.
Eingebaute Funktionen
Awk beinhaltet viele nützliche Funktionen, die den bereits beschriebenen Funktionsumfang erweitern. Die wichtigsten dienen der Verarbeitung von Zeichenketten. Sie können mit Awk Zeichenketten beliebig zusammensetzen und aufsplitten, durchsuchen und ersetzen. Abbildung 2 stell einige wichtige Funktionen vor. Diese und weitere Beispiele sind auch in der Datei stringfunktionen.sh enthalten. Sie können die Beispiele von dort in die Shell kopieren und mit den Funktionen experimentieren, bevor Sie sie später in Skripten einsetzen.
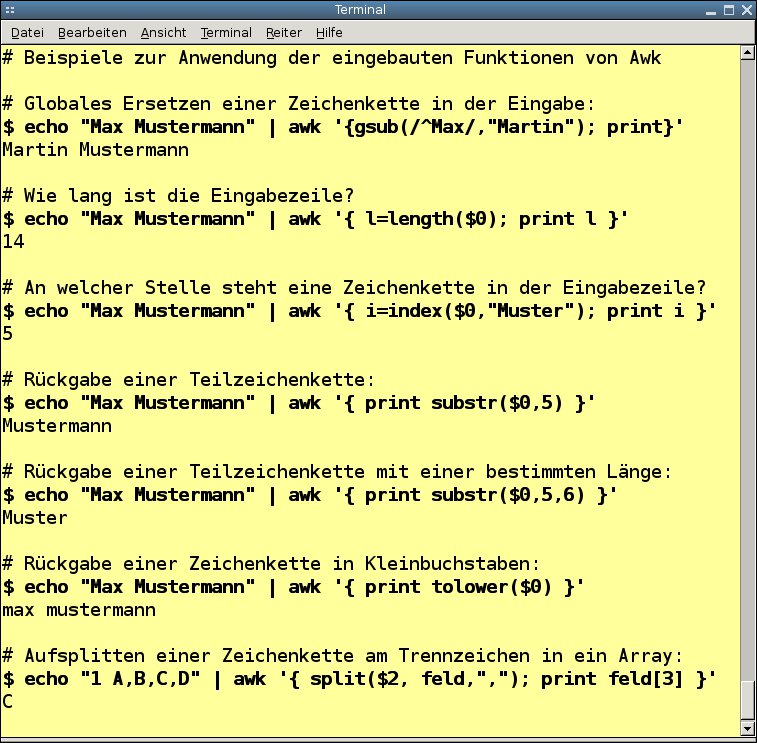
Abbildung 2: Awk bringt bereits eine ganze Reihe nützlicher Funktionen zur Verarbeitung von Zeichenketten mit.
Eine weitere wichtige Funktion ist getline. Die Ausgabe eines aufgerufenen Unix-Befehls kann damit durch eine Pipe an eine Awk-Variable übergeben werden (siehe systemaufrufe.awk, Listing 1).
Listing 1
# Einbinden von Unix-Befehlen
BEGIN {
"date +%x" | getline tag;
"date +%T" | getline zeit;
printf("\nHeute ist der %s und es ist %s Uhr.\n",
tag, zeit);
}
Mit getline können auch Daten aus Dateien eingelesen werden anstatt sie beim Aufruf direkt zu übergeben. Auf diese Weise kann Awk beispielsweise auf Daten zugreifen, die für die Formatierung oder für Vergleiche dienen.
Anfang und Ende
Zu den bereits vorgestellten Bedingungen im Hauptteil einer Awk-Skriptdatei kommen die beiden speziellen Muster BEGIN und END hinzu. Diese beiden Anweisungsblöcke sind für die Auswertung von Dateien sehr wichtig: Die Befehle im BEGIN-Block führt Awk vor dem Einlesen der ersten Datenzeile aus. Sie dienen zum Initialisieren des Skripts und zum Setzen von Variablen. Wenn Sie zum Beispiel das Trennzeichen für die Eingabe oder für die Ausgabe ändern möchten, können Sie dort die Variable OFS setzen. Der BEGIN-Block kann jedoch auch zur Ausgabe eines Tabellenkopfes dienen.
Die Befehle im END-Block werden nach dem Einlesen der letzten Datenzeile ausgeführt. Sie dienen oft der Auswertung der eingelesenen Daten. Dort können Sie beispielsweise Summen und Mittelwerte bilden oder einen Tabellenfuß an die Ausgabe anhängen.
Wenn beide Blöcke in einem Awk-Skript enthalten sind, lohnt es sich meist, das Skripts in einer separaten Datei zu speichern. Sie können diese Dateien mit jedem Texteditor (zum Beispiel Emacs oder Vi) erstellen. Die meisten Editoren bieten eine Syntaxhervorhebung und für Awk und eine Klammerkontrolle an.
Auswertung eines Logfiles
Viele größere Netzwerkdrucker und Printserver protokollieren alle Druckaufträge in einer Textdatei. Zu den protokollierten Daten gehören die Auftraggeber der Druckjobs, das Seitenformat, die Anzahl der Seiten und frei wählbare Datenfelder für Projektkostenstellen oder andere Angaben. Jede Zeile enthält den Datensatz eines Druckauftrags. Im Listing 2 sehen Sie den Tabellenkopf und einige Beispieldatensätze aus der Datei printlog.txt.
Listing 2
Document User Device Format Medium col b/w KstSt C2.sxw LAGO pr04 DIN_A4 Normal 1 10 P01 vortr.pdf LEHM pr03 DIN_A4 Normal 0 10 P01 angebot.doc LOHN pr01 DIN_A4 Normal 3 0 P02
Die Awk-Scripte für diese Aufgabe haben (je nach Formatierung) eine Länge von etwa sechs bis acht Zeilen. Sie sind in den Beispielen zu diesem Artikel enthalten. Wenn Ihnen diese nicht zur Verfügung stehen, erstellen Sie das in Listing 3 abgedruckte Skript bitte mit einem Texteditor und speichern es als auswertung1.awk ab.
Beginnen wir mit einer einfachen Auswertung der Anzahl aller schwarz-weiß oder bunt gedruckten Seiten. Dazu wird je eine Variable für die beiden Summen mitgeführt, die mit jeder gefundenen Zeile erhöht wird.
Listing 3
#Auswertung der Anzahl der gedruckten Seiten
NR==1 {
next;
}
{
summe_color+=$6;
summe_bw+=$7;
}
END {
print summe_color " Farbdrucke";
print summe_bw " Schwarz/Weiss-Drucke";
}
Rufen Sie das Script mit awk -f auswertung1.awk printlog.txt auf. Durch den Aufruf wird zuerst die Skriptdatei geladen. Dann wendet Awk die Befehle des Skripts auf printlog.txt an.
Der Befehl next überspringt eine Zeile, falls NR==1. So wird die erste Zeile, die den Tabellenkopfs enthält, ingnoriert. Es wäre auch möglich, diese Zeile in einer Variablen zu speichern und am Ende auszugeben.
Für jede weitere Zeile erhöht Awk die Variablen summe_color und summe_bw nun um die Anzahl der farbig (Feld $6) oder schwarzweiß (Feld $7) gedruckten Seiten. Am Ende werden beide Summen ausgegeben. Die Auswertung dieser Druckaufträge pro Kostenstelle ist eine etwas komplexere Aufgabe, die Awk jedoch ebenfalls sehr gut lösen kann (siehe Listing 4 und auswertung2.awk).
Listing 4
# Auswertung der Anzahl schwarz-weiss
# gedruckter Seiten pro Kostenstelle
NR==1 {
next;
}
{drucke[$8]+=$7}
END {
print "KstSt. Anzahl";
for (F in drucke) {print F " " drucke[F]}
}
Auch hier überspringt der next-Befehl die erste Zeile. Für alle anderen Zeilen soll die Anzahl der Schwarzweiß-Drucke pro Kostenstelle ausgewertet werden. Mit dem Befehl drucke[$8]+=$7 wird der Wert für die jeweilige Kostenstelle im Arrayfeld drucke[] um die Anzahl der Seiten im Feld $7 erhöht.
Wenn alle Datensätze gelesen sind, wertet eine Schleife das Datenfeld drucke im END-Block aus. Dabei wird die aufsummierte Anzahl der Druckseiten für jede Kostenstelle ausgegeben.
Das Array drucke[] ist in diesem Beispiel durch den Namen der Kostenstelle indiziert. In den Beispielen zu diesem Artikel finden Sie zusätzlich noch das Skript auswertung3.awk, mit dem alle Drucke der einzelnen Nutzer summiert werden. Dort werden zwei Datenfelder mitgeführt.
Auswertung einer Messwertdatei
Das folgende Beispiel bereitet eine einfache Messwertdatei (Listing 5) mit einer Zeitspalte und fünf Spalten mit Messwerten auf. Alle sechs Spalten enthalten Fließkommazahlen. Bitte setzen Sie in der Shell die Variable LC_ALL=C, bevor Sie dieses Beispiel ausprobieren.
Listing 5
t Messwert1 Messwert2 Messwert3 Messwert4 Messwert5 0.100000 0.194000 0.166000 0.162000 0.155000 0.194200 0.200000 0.440000 0.388000 0.359000 0.392000 0.400000
Im Listing 5 sehen Sie den Kopf der Tabelle und die ersten Zeilen mit Beispieldaten. Den Mittelwert aus diesen Zahlen zu bilden ist mit Awk ziemlich einfach. Der Skript mittelwert.awk (Listing 6) bildet für jede Messdatenzeile die Summe der gemessenen Werte und teilt sie dann durch die Anzahl der Messwerte.
Listing 6
# Mittelwerte der Daten aus
# einer Messdatendatei
NR==1 {next;}
{summe = 0;
for (i=2; i<=NF; i++) {
summe+=$i;
}
mittelwert = summe/(NF-1)
printf("%6s %8.2f\n",$1,mittelwert);
}
In der Praxis sollen oft Minimal- und Maximalwerte ausgegeben werden. Dies lässt sich durch Sortieren der Spalten auf einer Zeile erreichen. Im Listing 7 ist das Skript messdaten1.awk dargestellt, das für jede Zeile das Maximum und Minimum bildet.
Listing 7
# Auswertung einer Messdatendatei
BEGIN { print(" t MIN MAX"); }
NR==1 { next; }
{
t=0; n=NF;
/* Schreibe die Messwerte in ein Datenfeld (Array): */
for (i=2; i<=n; i++) {
y[i-2] = $i;
}
/* Sortiere das Datenfeld: */
for (i = 0; i <= n-2; i++) {
for (j = i; j > 0 && y[j-1] > y[j]; j--) {
t = y[j]; y[j] = y[j-1]; y[j-1] = t;
}
}
/* Ausgabe: t, MIN, MAX */
printf("%6s %8.6f %8.6f ",$1, y[0], y[n-2]);
printf("\n");
}
Zunächst werden die Messwerte ($1 bis $NF) in ein Array geschrieben. Nach der Sortierung enthält der erste Wert das Minimum und der letzte Wert den Maximumwert.
Das Sortieren der Werte funktioniert hier über Ausschneiden und Einfügen (Insertion Sort). Dieser Algorithmus reicht für wenige Messwerte pro Zeile aus. Effizientere Varianten finden Sie zum Beispiel in Jon Bentleys exzellentem Buch [5]. Für komplexere Sortieralgorithmen bietet sich in Awk die Einbindung als Funktion an.
Zusammenfassung
Mit Awk lassen sich viele Aufgaben aus dem Alltag eines Nutzers oder Administrators schnell und effektiv lösen. Es ist einfacher zu erlernen und anzuwenden als viele andere Programmiersprachen. Dieser Artikel hat Sie mit den Grundlagen vertraut gemacht und einige komplexere Beispiele vorgestellt. In den Newsgruppen und auf vielen Webseiten finden Sie Unterstützung und unzählige weitere Beispiele.
Die frei verfügbare Dokumentation [2] erleichtert den Einstieg und beinhaltet auch viele Beispiele. Das Buch der drei Awk-Erfinder Alfred Aho, Peter Weinberger und Brian Kernighan [6] ist für Fortgeschrittene zu empfehlen. Die Beispiele zum Buch sind auch online unter [7] zu finden. (jlu/pkr)
Infos
[1] Beispiele: Stefan Lagotzki, awk-Beispiele, Version 1.0 (Sept. 2005) http://www.lagotzki.de/awk/
[2] GNU-Awk-Handbuch: Arnold Robbins, “The GNU Awk User’s Guide”, 2003, http://www.gnu.org/software/gawk/manual/gawk.html
[3] Regular Expressions: Martin Möller, “Strukturierte Suche”, LinuxUser 08/2005, S. 90 ff.
[4] Jeffrey E. F. Friedl: “Reguläre Ausdrücke”, O’Reilly, 2003
[5] Jon Bentley: “Perlen der Programmierkunst”, Addison-Wesley, 2000
[6] Aho, Weinberger, Kernighan: “The AWK Programming Language”, Addison-Wesley, 1988.
[7] Aho, Weinberger, Kernighan: “Examples from The AWK Programming Language”, 2005, http://cm.bell-labs.com/cm/cs/awkbook/





