
Zum wichtigsten Handwerkszeug bei der Suche in Texten und auf der Festplatte zählen Regular Expressions. Trotz ihrer scheinbar komplexen Struktur lassen sie sich schnell meistern.
Das Suchen von Dateien oder bestimmten Inhalten innerhalb von Dateien ist ein immer wiederkehrendes Vergnügen für jeden, der sich mit Datenverarbeitung im weitesten Sinne beschäftigt. Wie in nahezu allen Bereichen hält die Unix-Welt auch auf diesem Gebiet verschiedene Herausforderungen bereit, denen man sich stellen kann. Meisterschaft auf dem Gebiet der Datensuche hat erreicht, wer die so genannten “Regulären Ausdrücke”, oder Regex oder RE (von engl. “regular expressions”) beherrscht. Über die korrekte deutsche Pluralbildung von Regex gibt es unter den Benutzern Unstimmigkeiten. Im Deutschen hat sich der Ausdruck “Regexe” weitgehend eingebürgert, den wir auch im Folgenden verwenden.
Viele Programme in der Unix-Welt (aber auch darüber hinaus) ermöglichen die Verwendung von Regexen. Einige prominente Vertreter sind Sed, Awk, Mutt, Vi, Procmail, Emacs und diverse Shells. In der Gruppe der Programmiersprachen hat vor allem Perl auf dem Gebiet der Regexe Zeichen und Standards gesetzt. Mittlerweile gibt es aber Regex-Unterstützung auch für Python, Java, .NET und C.
Reguläre Ausdrücke wirken ein bisschen wie Schweizer Taschenmesser: Auf den ersten Blick nicht sehr elegant und auch nicht schön anzusehen. Außerdem scheinen sie viele Funktionen zu bieten, von denen man sich kaum vorstellen kann, sie jemals gebrauchen zu können. Auf den zweiten Blick aber sind sie ungemein nützlich. Hat man sich erstmal an sie gewöhnt, fragt man sich immer wieder, wie man jemals ohne sie auskommen konnte.
Larry Wall, der Erfinder von Perl, hat einmal gesagt, ein guter Programmierer brauche nur drei Tugenden: Faulheit, Ungeduld und Selbstüberschätzung [1]. Wenn Sie diese drei Tugenden mitbringen, dann werden Sie sich schnell mit den Regulären Ausdrücken anfreunden. Auch wenn die Regexe auf den ersten Blick genauso trocken aussehen, wie ihr Name klingt: Nach nur einer kurzen Gewöhnungszeit bereiten Ihnen auch komplizierte Ausdrücke keine Probleme mehr.
Alte Bekannte
Wenn Sie sich alle Dateien eines Verzeichnisses auflisten wollen, die auf den Suffix .txt enden, dann verwenden Sie bereits wie selbstverständlich einen Regex, indem Sie ls -l *.txt eingeben. Das Sternchen (*) bedeutet in diesem Zusammenhang (stark vereinfacht): eine beliebige Anzahl beliebiger Zeichen. Es werden also alle Dateien aufgelistet, deren Name aus einer beliebigen Zahl beliebiger Zeichen, gefolgt von ., t, x, t besteht.
Machen wir uns noch klar, dass nicht nach dem eigentlich Zeichen * als Teil des Dateinamens gesucht wird. Das Zeichen * steht hier für etwas anderes (eine beliebige Anzahl beliebiger Zeichen), daher bezeichnen wir es als Metazeichen. Von den kaum zählbaren existierenden Metazeichen stellen wir Ihnen in diesem Artikel einige wenige, aber grundlegende vor.
Reguläre Ausdrücke bestehen also aus Zeichen, die tatsächlich Teil des Musters sind, das erkannt werden soll, und aus Metazeichen, die etwas beschreiben: zum Beispiel mehrere Zeichen, Zeichengruppen und so fort. In anderen Regex-Dialekten kann das Sternchen andere Bedeutungen annehmen, wie wir später sehen werden. Der geläufigste Regex-Dialekt, den wir uns im Folgenden näher ansehen, ist das so genannte “Perl-kompatible” Regex.
Einfache Mustererkennung mit Egrep
Das Suchen von Inhalten innerhalb von Dateien bildet das Metier des Programms egrep, das unter jeder Linux-Installation zur Verfügung stehen sollte. Die einfachste Anwendung ist die Suche nach bestimmten, klar definierten Mustern, das so genannte Pattern Matching. Nähere Informationen zu Egrep erhalten Sie durch die Eingabe von man egrep oder unter [2].
Nehmen wir an, wir verfügen über eine ausgesprochen umfangreiche Textdatei, die Kurzbeschreibungen verschiedener deutscher Städte beinhaltet, welche nicht alphabetisch sortiert sind. Als Beispiel dient uns die Aufstellung aus Listing 1. Um nachzusehen, ob die Liste auch die Stadt Hamburg umfasst, hilft die Eingabe von
egrep -i 'Hamburg' stadtliste.txt
weiter. Der Schalter -i ist ausgesprochen hilfreich, denn er veranlasst egrep, Groß- und Kleinschreibung zu ignorieren; den eigentlichen Reguläre Ausdruck (Hamburg) übergibt man in Hochkommata.
Listing 1
stadtliste.txt
Hamburg Berlin Frankfurt München Harburg Bad Homburg Bad Nauheim Idstedt Idstein Friedrichsbad Baden-Baden
Falls Ihnen das Verwenden der Kommandozeile größeres Unbehagen bereitet, können Sie selbstverständlich auch einen handelsüblichen Editor verwenden. Die Suchfunktion der KDE-Oberfläche beispielsweise unterstützt Regexe vorbehaltlos (Abbildung 1). egrep bietet aber immense Vorteile, unter anderem das Suchen in mehreren Verzeichnissen und Dateien.
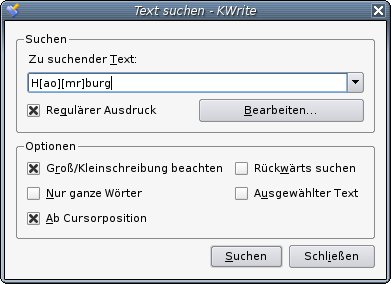
Abbildung 1: Suchfunktion mit Regex-Unterstützung bei KDE.
Zeichenklassen
Als erste Metazeichen untersuchen wir die eckigen Klammern: [...]. Innerhalb dieser Klammern können Sie eine Gruppe von Zeichen spezifizieren, die alle vorkommen dürfen. Nehmen Sie einmal an, Sie wollten die Städte Hamburg und Harburg finden, deren Namen recht ähnlich klingen. Mit der simplen Suchfunktion eines Editors müssten Sie die Suche zweimal vornehmen, einmal nach Hamburg und einmal nach Harburg. Mit egrep verwenden Sie stattdessen einfach den Regex Ha[mr]burg verwenden:
$ egrep -i 'Ha[mr]burg' stadtliste.txt Hamburg Harburg
Ausformuliert bedeutet dieser Regex: Die Zeichen H, a, gefolgt von einem m oder r, gefolgt von b, u, r, g. Wollem Sie nun auch noch Bad Homburg suchen, müssen Sie den Ausdruck etwas erweitern zu: H[ao][mr]burg. Dieser Regex würde zusätzlich einen weiteren Ort finden, wenn er in der Liste existierte. Erraten Sie, welchen? Kleiner Tipp: Er liegt in Niedersachsen.
Statt einzelner erlaubter Zeichen können Sie mit dem Minuszeichen (-) auch einen Zeichenbereich angeben. Dies stellt insbesondere dann eine Erleichterung dar, wenn aufeinander folgende Zeichen wie A-Z oder 0-9 gemeint sind. Stellen Sie sich vor, Sie müssten [ABCDEF...Z] tippen! [A-Z] sieht doch wesentlich entspannter aus.
Als Beispiel können Sie eine HTML-Datei betrachten, in der Sie nach allen Header-Tags suchen wollen (also <H1>, <H2>, <H3>, <H4>). Der Regex dazu lautet: H[1-4]. Das ist gleichbedeutend mit, aber wesentlich kürzer als H[1234].
Zeilenanfang und Zeilenende
Als nächstes wollen wir alle Städte auflisten, die den Titel “Bad” führen dürfen. Bei der Eingabe des naheliegenden Befehls erhalten wir aber:
<B>$ egrep -i 'Bad' stadtliste.txt<B> Bad Homburg Bad Nauheim Friedrichsbad Baden-Baden
Obwohl Friedrichsbad bestimmt wunderschön ist (falls es überhaupt existiert), erfüllt es doch nicht unsere strengen Bedingungen. Das Problem lässt sich auf zwei Arten lösen: Erstens könnten Sie auf den Schalter -i verzichten, dann würde Egrep explizit nach einem großen ‘B’ suchen. In dem Fall hätten Sie das Problem dann aber nicht mit einem Regex gelöst, sondern mit den Bordmitteln von egrep.
Zweitens könnten Sie angeben, dass das ‘B’ unmittelbar am Anfang der Zeile stehen muss. Damit würde Friedrichsbad nicht mehr angezeigt werden. Das hierfür verwendete Metazeichen ist das Hochzeichen ^. Der korrekte Regex für diese Aufgabe lautet demnach ^Bad.
Ein Versuch zeigt, dass bei einem Aufruf mit diesem Regex Friedrichsbad zwar aus der Ausgabe verschwindet, Baden-Baden aber noch immer erscheint. Der Reguläre Ausdruck arbeitet also noch nicht ausreichend präzise. Das Merkmal, das “Bad XXX” deutlich von “Baden-Baden” unterscheidet, ist das auf das d folgende Leerzeichen. Praktischerweise handelt es sich beim Leerzeichen ebenfalls um ein ganz normales Zeichen, das in einem Regex vorkommen darf. Erweitern Sie den Regulären Ausdruck also zu '^Bad ' (nun mit Leerzeichen hinter dem d), geht nichts mehr schief:
<B>$ egrep -i '^Bad ' stadtliste.txt<B> Bad Homburg Bad Nauheim
Auf ähnlichem Weg können Sie auch das Zeilenende näher spezifizieren. Möchten Sie also erreichen, dass Hamburg, nicht aber Burgwedel angezeigt wird, formulieren Sie: burg$. Das bedeutet soviel wie: Auf die Zeichen B, u, r, g muss das Zeilenende folgen.
Alles, nur nicht das!
Eine Sonderform der bisher besprochenen Metazeichen stellt die Ausschlussliste dar. Taucht das Hochzeichen (^) innerhalb einer Zeichenklasse auf, verneint es sie und gibt somit an, welche Zeichen nicht vorkommen dürfen. Wollen Sie beispielsweise keine Städte anzeigen, die mit B, H oder I beginnen, müssen Sie angeben, dass auf den Zeilenanfang keiner der drei Buchstaben folgen darf:
<B>$ egrep -i '^[^BHI]' stadtliste.txt<B> München Frankfurt Friedrichsbad
Noch einmal zum Mitdenken: Zeilenanfang ^, nicht gefolgt ([^) von B oder H oder I (BHI]).
Beliebige Zeichen
Ein sehr einfaches, aber dennoch nützliches Metazeichen ist der Punkt .. Er bezeichnet “irgendein Zeichen”. Sie wissen ja, dass in Deutschland Dezimalzahlen mit Komma dargestellt werden. Pi schreibt sich also hierzulande 3,1415. Im Englischen gilt allerdings die Notation: 3.1415. Um beide Fälle mit einer Zeichenklasse abzufangen, müssten Sie 3[.,]1415 formulieren. Sie können aber auch 3.1415 als Regex verwenden: Hier heißt das dann nicht: Die Zeichen 3, ".", 1, 4, 1, 5, sondern: Das Zeichen 3, gefolgt von irgendeinem Zeichen, gefolgt von 1, 4, 1, 5.
Die Alternation
Als Beispiel für die Alternation, die nicht mehr auf einzelnen Zeichen oder einem Zeichenbereich basiert, sondern feste Zeichenketten beliebiger Länge unterscheidet, sollen uns die beiden Orte Idstedt (in Schleswig-Holstein) und Idstein (in Hessen) dienen. Mittels einer Zeichenklasse können Sie zwar einenentsprechendenn Regex formulieren, der bei beiden Städten einen Treffer erzeugt: Idste[id][nt]. Doch gibt es hier ein Problem: Idste[id][nt] findet auch “Idstedn” und “Idsteit”. Dies ist bei der Alternation ausgeschlossen:
$ egrep -i 'Idste(in|dt)' stadtliste.txt Idstedt Idstein
Unser Regex lauten also in diesem Fall: I, d, s, t, e, gefolgt entweder von der Zeichenkette in oder (|) der Zeichenkette dt.
Im echten Leben
Die bisherigen Beispiele fielen zwar etwas trivial aus, eignen sich jedoch doch zur Bewältigung einiger Herausforderungen des Alltagslebens. Vor allem haben Sie diese Fingerübungen mit den grundlegenden Metazeichen vertraut gemacht, so dass Sie nun Ihre Experimente mit Regulären Ausdrücken vertiefen können. Als erstes komplexeres Beispiel soll uns das Durchsuchen von Mailboxdateien dienen. Vielleicht möchten Sie von einer sehr umfangreichen Mailboxdatei eine Zusammenfassung erstellen, in der nur Absender und Betreffzeile der Nachrichten angezeigt werden. Dies erreichen Sie mit:
$ egrep -i '^(From|Subject): ' <I>Mailbox? datei<I>
Angezeigt werden soll jede Zeile, die folgendermaßen aufgebaut ist: Zeilenanfang (^) gefolgt von den Zeichenketten From oder Subject, gefolgt von den Zeichen : und . Hätten Sie nur (From|Subject) verwendet, würden auch Zeilen gefunden werden, in denen etwa “le fromage” (franz. “Käse”) vorkommt.
Schon etwas komplexer fällt das Zusammenspiel von Regular Expressions mit procmail aus. Das Programm dient zur Bearbeitung von E-Mail und ist unglaublich flexibel: Man kann automatische Antworten erstellen, E-Mail in bestimmte Ordner sortieren und viele andere Dinge mehr, die mit kaum einem normalen E-Mail-Programm möglich sind. procmail greift ebenfalls auf Regexe zurück.
Einen Auszug aus einer typischen procmail-Konfigurationsdatei finden Sie im unten stehenden Listing. Hier kommt ein weiteres Metazeichen zum Einsatz, der Stern *. Er bezieht sich immer auf das Zeichen, auf das er folgt, und bedeutet: Beliebig oft (auch null Mal). Der Ausdruck .* steht also für irgendein Zeichen (.) und zwar beliebig oft (*).
:0 * ^List-Id.*gnome-bugsquad.gnome.org in-ML-GNOME-dev-bugs/ :0 * ^List-Id.*b-greek in-ML-Altgriechisch/
Die Zeichenfolge :0 leitet für procmail eine neue Vorschrift ein. Auf das * folgt nun ein regulärer Ausdruck. procmail durchsucht nun jede E-Mail nach diesem Ausdruck. Erzeugt dieser einen Treffer, wird die E-Mail in den entsprechenden Ordner verschoben, der in der Zeile darunter steht. Die erste Vorschrift dient der Behandlung von Mails der Gnome-Bugsquad-Mailingliste. Jede E-Mail, die über diese Liste verschickt wird, enthält die folgende Zeile:
List-Id: List to discuss bug maintenance ? in GNOME <gnome-bugsquad.gnome.org>
Auf diese Zeile passt der erster Regex: ^List-Id.*gnome-bugsquad.gnome.org: Zeilenanfang ^, gefolgt von der Zeichenkette List-Id, gefolgt von einem beliebigen Zeichen . und zwar beliebig oft *, gefolgt von gnome-bugsquad.gnome.org. Entsprechende E-Mails verschiebt procmail in den Ordner in-ML-GNOME-dev-bugs/.
In diesem Zusammenhang spielt der Stern eine wichtige Rolle. Für die Auswertung ist zunächst nur von Bedeutung, dass die Zeile mit der Zeichenkette List-Id einsetzt. Dies signalisiert, dass es sich um eine E-Mail aus einer Mailingliste handelt. Alles folgende interessiert überhaupt nicht und kann mittels .* ignoriert werden. Erst der eindeutige Name gnome-bugsquad.gnome.org ist wieder wichtig, denn er zeigt, um welche Mailingliste es sich handelt.
Grafische Alternative
Falls Sie zu den notorischen Kommandozeilenmuffeln zählen: Für das Erstellen von Regexen gibt es auch ein grafisches Helferlein gibt, das Erleichterung verspricht. Das Programm heißt kregexpeditor, einen Screenshot sehen Sie in Abbildung 2.
Vorab sei allerdings klargestellt, dass der zu investierende Lernaufwand sich durch kregexpeditor nicht vermindert: Ob Sie nun lernen, dass [...] eine Zeichenklasse ist, oder sich den entsprechenden Knopf im Editor einprägen, macht kaum einen Unterschied. Beide Informationen erfordern ähnlich viel Speicherplatz ihres Gehirns; die Kommandozeilen-Variante stellt zudem die kompatiblere Version dar. Wenn Sie aber auf einen Regulären Ausdruck treffen, den Sie nicht verstehen, hilft das Programm oft weiter: Es kann den Regex grafisch darstellen und macht ihn so wesentlich übersichtlicher.
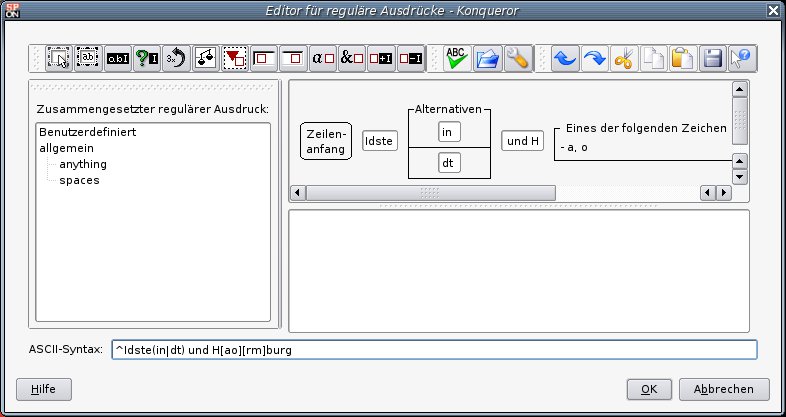
Abbildung 2: Der KDE Regex-Editor “kregexpeditor”.
Ausblick
Ein so kurzer Artikel wie der vorliegende kann das umfangreiche Feld der Regulären Ausdrücke nur am Rand streifen. Er hat Ihnen aber einen ersten Überblick über Reguläre Ausdrücke vermittelt, den Sie mit etwas Übung weiter ausbauen können. Eine kurze Zusammenfassung der wichtigsten Metazeichen finden Sie in Tabelle 1.
Tabelle 1: Grundlegende Regex-Metazeichen
| […] | beliebiges Zeichen aus der Liste |
| ^ | Position am Zeilenanfang |
| $ | Position am Zeilenende |
| [^…] | beliebiges Zeichen nicht aus der Liste |
| . | Irgendein Zeichen |
| | | oder in Alternationen |
| () | geben die Reichweite von | an |
| * | beliebige Anzahl (auch Null) |
Erste etwas umfangreichere Suchen mittels egrep sollten nun kein Problem mehr für Sie sein. Falls Sie also schon immer mal herausbekommen wollten, wie viele Verbalinjurien die Programmierer des Linux-Kernels in die Quelldateien geschrieben haben, wissen Sie nun, dass Sie
cd /usr/src/linux egrep -ir '(fuck|shit)' *
eingeben könnten. Wenn Sie bei der Ausgabe ein asiatischer Hardware-Hersteller stört, wissen Sie, dass Sie noch etwas am Regex feilen müssen.
Die Möglichkeiten der Regexe sind vielleicht nicht unbegrenzt, aber doch ziemlich weitreichend – insbesondere in Verbindung mit einer Programmiersprache. Entsprechende Beschreibungen können ganze Bücher füllen, so etwa auch das hervorragende Werk von Jeffrey Friedl[3]. Sehr gute Einführungen bekommen Sie aber auch in jedem besseren Buch zu Perl. Das könnte allein schon ein Grund sein, mit dem Erlernen dieser mächtigen Sprache anzufangen. Zu den besonders gut lesbaren Büchen zählt dieser Art zählt die Perl-Einführung von Schwartz und Phoenix [4]. Der Perl-Klassiker von Larry Wall [1] fand eingangs bereits Erwähnung. Falls Sie während der Lektüre unserer Einführung in die trockenen Regulären Ausdrücke etwas Begeisterung tanken konnten, w[üe]rden wir uns sehr darüber freuen.
Infos
[1] Larry Wall et al., Programmieren mit Perl (3. Aufl.), O’Reilly, Köln 2001
[2] Informationen zu Egrep: http://regex.info
[3] Jeffrey E. F. Friedl, Reguläre Ausdrücke (2. Aufl.), O’Reilly, Köln 2003
[4] Randal L. Schwarz, Tom Phoenix, Einführung in Perl (3. Aufl.), O’Reilly, Köln 2002





