
Die meisten E-Mail-Adressen finden Versender unerwünschter Werbung auf Homepages im WWW. Wie man seine Adresse so veröffentlicht, dass sie für automatische Sammelprogramme unsichtbar bleibt, erklärt dieser Artikel.
Spam ist eine Plage, der man nicht einfach Herr wird: Spamfilter trennen zwar anhand mehr oder minder geeigneter Heuristiken die Spreu vom Weizen, aber vergleichbar mit der Situation bei Computer-Viren sind die Spammer oft einen Schritt voraus und entwickeln immer neue Methoden, um die Filter zu überlisten.
Ursachenforschung
Nicht zuletzt übereifrige Administratoren helfen selbst, ihre eigenen Abwehrmaßnahmen auszuhebeln, indem sie dem Spammer aussortierte Mails inklusive Begründung, weshalb der Filter sie für Spam hält, zurücksenden. So oder so – Spammer finden immer wieder Wege durch die gängigen Spamfilter. Sie bieten also allenfalls eine Teillösung.
Andere Bemühungen zielen darauf, Spam schon im Ansatz zu stoppen; zum Beispiel die Forderung nach authentifiziertem SMTP als Standard. Damit müsste sich jeder Mail-Versender beispielsweise durch seine IP-Adresse oder ein Passwort beim Server identifizieren – einige Anbieter verwenden dieses Verfahren bereits.
Die Hauptquelle, aus denen Spammer ihr Zieladressen beziehen, bilden laut einer Studie des “Center for Democracy and Technology” (CDT) öffentliche Web-Seiten [1]. Im Rahmen ihrer Forschungsarbeit verbreitete das CDT eigens dafür angelegte E-Mail-Adressen gezielt auf Homepages, in Newsgroups und in verschiedenen Web-Diensten. 97,3% der 8842 daraufhin erhaltenen, als unerwünschte E-Mail-Werbung eingestuften Nachrichten richteten sich an die auf Web-Seiten veröffentlichten Mail-Adressen (Abbildung 1).
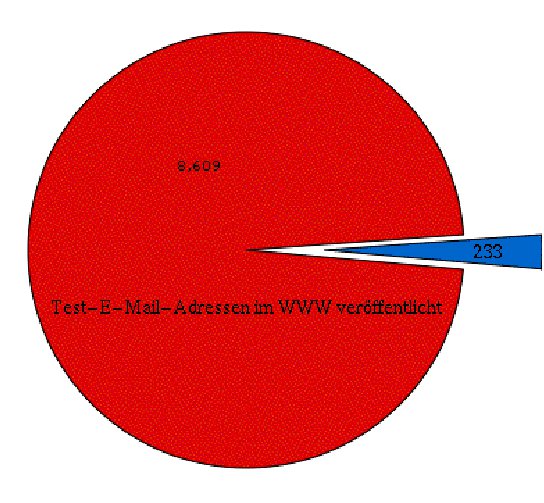
Abbildung 1: Der Großteil der Spammer findet Zieladressen im WWW.
Demnach lohnt es sich, beim Gestalten von Web-Seiten darauf zu achten, dass die darauf enthaltenen Mail-Adressen für Spammer nicht verwertbar sind. Laut der genannten Studie ist eine Verschleierung auch im Nachhinein sinnvoll, da die Zahl der Spam-Mails nach dem Entfernen der Adresse abnahm (Abbildung 2).
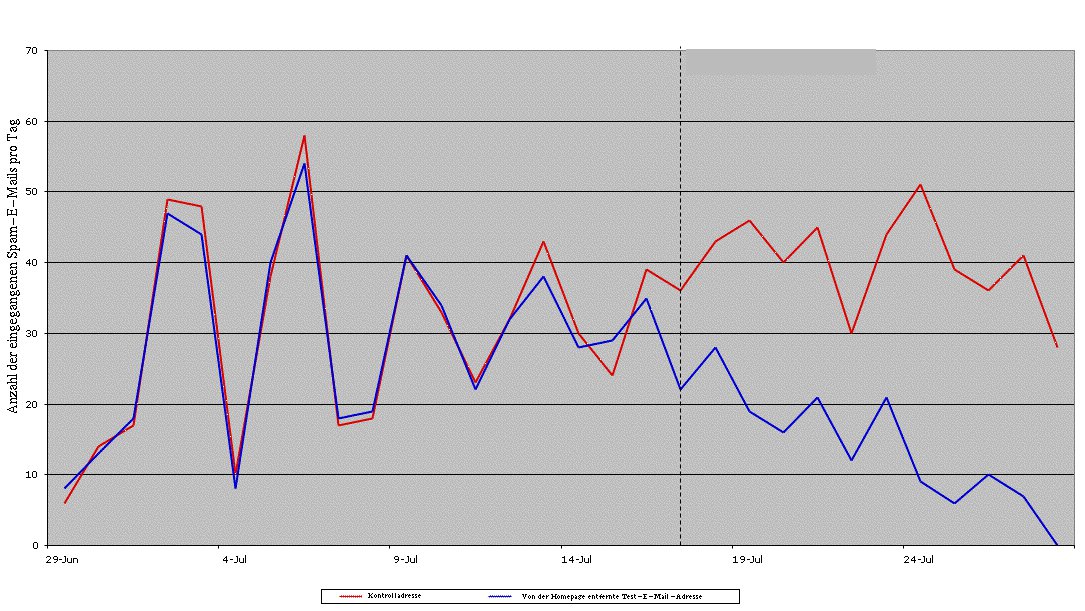
Abbildung 2: Auch Nachträgliches Entfernen der E-Mail-Adresse von einer Homepage hilft.
Automatische Adressensammler
Das Vorgehen der meisten Spammer ist denkbar primitiv: Auf einer beliebigen Web-Seite angefangen, speichern sie alle Links der Form mailto:, also die Verweise auf Mailadressen. Andere Links verfolgen sie weiter und verfahren mit den dort gefundenen Seiten ebenso.
Auf diese Art finden Spammer irgendwann jede Seite, auf die nur ein Link zeigt; mit demselben Verfahren wie erwünschte Suchmaschinen durchforsten sie das gesamte Web. Ein Programm zu schreiben, das dies automatisch erledigt – so genannte “Spider” (Spinne) oder “Harvester” (Erntemaschine) – ist nicht schwierig. Die gespeicherten Mailadressen befreit der Spammer anschließend von Mehrfacheinträgen und fertig ist eine Sammlung potentieller Spamopfer.
Diese Funktionalität lässt sich in einfacher Ausführung schon mit den Linux-Werkzeugen wget, sed, tr, sort und uniq nachbilden und erreicht auch in dieser Form erstaunliche Ergebnisse.
Dabei ist wget für das Durchwandern der Webseiten zuständig, sed durchsucht die gelesenen Seiten nach E-Mail-Adressen. tr verpasst den Ergebnissen eine einheitliche Groß- und Kleinschreibung, sort sortiert die gefundenen Mailadressen alphabetisch und uniq eliminiert alle doppelten Vorkommen.
Ein Testlauf mit der Homepage des Autors als Ausgangspunkt lieferte innerhalb von nur acht Minuten bereits über neunzig unterschiedliche E-Mail-Adressen. Wählt man eine Startseite mit mehr Links und ignoriert entgegen der Konvention die Datei robots.txt[3], erreicht man weitaus mehr Ergebnisse in derselben Zeit. Zudem ließe sich die Suche nach Mail-Adressen auf dort genannte, aber nicht verlinkte Bereiche ausdehnen.
Als Abwehr gegen Adressensammler überhaupt keine E-Mail-Adressen mehr anzugeben, ist für viele Homepage-Betreiber keine akzeptable Lösung; schließlich soll eine Web-Seite durchaus die Möglichkeit zur Kommunikation bieten. In Deutschland verpflichtet außerdem §6 des Teledienstegesetzes (TDG) [4] gewerbliche Anbieter zur Angabe einer “Adresse der elektronischen Post”; auch wenn Juristen darüber streiten, ob dies eine E-Mail-Adresse sein muss, oder ob beispielsweise Fax-Nummern oder Instant-Messenger-Kontakte ebenso gelten.
Tarnen und Täuschen
Weit verbreitet hat sich die Methode, für den Menschen erkennbare Einschübe wie remove_to_mail_me zu verwenden: z. B. someone@remove_to_mail_me.example.com statt someone@example.com. Doch nicht alle Anwender denken daran, die Adresse nach einem Klick auf Antworten manuell zu korrigieren, oder es ist für sie nicht ersichtlich, welchen Teil sie entfernen sollen. Gewerblichen Homepage-Betreibern verbietet das Teledienstegesetz derart verschleierte Adressen ohnehin.
In zunehmenden Maße arbeiten auch Spammer mit gefälschten Absenderadressen, Fehlermeldungen landen also nicht bei ihnen, sondern bei unbeteiligten Dritten. Das kann so weit führen, dass Mail-Server aufgrund der Überlastung zusammenbrechen.
Zum selben Problem führt die in Newsgroups verbreitete Methode, für den Menschen erkennbare Einschübe wie remove_to_mail_me zu verwenden; an Stelle von someone@example.com beispielsweise someone@remove_to_mail_me.example.com.
Nicht alle Anwender denken daran, die Adresse nach einem Klick auf Antworten manuell zu korrigieren, oder es ist für sie nicht ersichtlich, welchen Teil sie entfernen sollen. Gewerblichen Homepage-Betreibern verbietet das Teledienstegesetz derart verschleierte Adressen ohnehin.
Die bereits angesprochene Studie des CDT [1] schlägt vor, Mail-Adressen auf Homepages als HTML-Entity zu codieren. Aus user@example.com wird damit:
user@examplecom
Der Browser liest die Adresse problemlos, Harvester entdecken darin beim Durchsuchen des Quelltexts aber kein gesuchtes Muster.
Tatsächlich empfingen in der genannten Studie so kodierte Adressen keine Spammails. Unser Primitiv-Harvester fand im Testdurchlauf 10 Adressen dieser Art.
Mit zunehmender Verbreitung dieser Darstellung ist aber davon auszugehen, dass Spider-Programme die Rücktransformation in gültige E-Mail-Adressen künftig automatisch durchführen; deshalb stellt sie langfristig keinen Vorteil gegenüber der Angabe im Klartext dar.
JavaScript als Helfer?
Die meisten Spider-Programme verarbeiten JavaScript nicht, dadurch bietet diese Sprache die Möglichkeit, E-Mail-Adressen auf Homepages zu verschleiern.
Listing 1 zeigt, wie man eine Adresse im Kopf (Head) der HTML-Seite festlegt, und sie dann mit der JavaScript-Funktion document.write() ausgibt. Bei dieser Variante steht die Mail-Adresse jedoch immer noch im Klartext auf der Seite; eine speziell danach ausgerichtete Suche findet sie weiterhin.
Listing 1
Die Mail-Adresse ausgelagert in den HTML-Kopf
<HTML>
<HEAD>
<TITLE>Beispielseite</TITLE>
<SCRIPT LANGUAGE="JavaScript">
<!--
mailadresse = 'user@example.com';
//-->
</SCRIPT>
</HEAD>
<BODY>
[…]
<SCRIPT LANGUAGE=â??JavaScriptâ??>
<!--
document.write('<A HREF="mailto:'+mailadresse+'">'+mailadresse+'</A>');
//-->
</SCRIPT>
[…]
</BODY>
</HTML>
Beim Zuweisen des Wertes an die Variable stehen weitere Möglichkeiten offen. Bei der – auch im Hinblick auf die Pflege der Seite – einfachsten, enthält eine externe JavaScript-Datei die Adressen, die der Browser bei Bedarf lädt. Solche Dateien werten Harvester derzeit nicht aus.
Doch der Aufruf externer Dateien durch die document.write()-Funktion bereitet einigen Browsern Schwierigkeiten. Außerdem könnte ein findiger Spammer mit geringem Aufwand alle JavaScript-Dateien einer Seite ausfindig machen und auch diese nach E-Mail-Adressen durchforsten.
Die Probleme mancher Browser mit der document.write()-Funktion lassen sich lösen, indem man nicht mittels HTML-Link (<a href=”mailto:someone@example.com”>) direkt auf die Mailadresse verweist, sondern JavaScript auch diese Aufgabe übernehmen lässt. Statt der Ausgabe von HTML-Code per JavaScript verwendet Listing 2 die JavaScript-eigene Link-Funktion document.location.href.
Listing 2
JavaScript übernimmt den Link zur Mail-Adresse
<HTML>
<HEAD>
<TITLE>Beispielseite</TITLE>
<SCRIPT LANGUAGE="JavaScript">
<!--
mailadresse = 'user@example.com';
function mailMe()
{
document.location.href="mailto:"+mailadresse;
}
//-->
</SCRIPT>
</HEAD>
<BODY>
[…]
<A HREF="javascript:mailMe();">Mail senden</A>
[…]
</BODY>
</HTML>
Verschleierung
Eine primitive Verschlüsselung mit dem XOR-Algorithmus reicht aus, um zu verhindern, daß Suchprogramme die Mail-Adresse finden. Diese Verschlüsselungsmethode bietet aus kryptographischer Sicht wenig Schutz, aber gegen Spammer, die auf viele Ergebnisse in kurzer Zeit abzielen, wirkt sie. Denn nun erfährt der Adresssammler die Mail-Adresse aus dem HTML-Quelltext nur noch in dieser verschleierten Form. Er müsste jetzt die JavaScript-Befehle verstehen und ausführen, um die Adresse im Klartext zu erhalten.
Listing 3 verschlüsselt den Benutzernamen der Mail-Adresse, also den Teil vor dem @; den Rest ermittelt die JavaScript-Funktion document.location.hostname im Klartext aus der Adressleiste im Browser. Dieses Beispiel funktioniert so nur, wenn der Server-Name der Homepage dem der E-Mail-Adresse entspricht. Alternativ verschlüsselt man auch den hinteren Teil der Adresse mit demselbem Verfahren wie den Benutzernamen.
Listing 3
HTML-Seite mit verschlüsselter Mail-Adresse
<HTML>
<HEAD>
<TITLE>Beispielseite</TITLE>
<SCRIPT LANGUAGE="JavaScript">
<!--
local = new Array (194,196,210,197);
local_part = '';
for (i=0;
i<local.length;
local_part += String.fromCharCode(local[i] ^ 183), i++) ;
mailadresse = local_part + String.fromCharCode(64) + document.location.hostname;
//-->
</SCRIPT>
</HEAD>
<BODY>
[…]
<SCRIPT LANGUAGE="JavaScript">
<!--
document.write('<A HREF="mailto:'+mailadresse+'">'+mailadresse+'</A>');
//-->
</SCRIPT>
[…]
</BODY>
</HTML>
Das Verschlüsselungsverfahren lässt sich beliebig ausbauen. Jedoch ist zu beachten, dass sich sowohl das verwendete Verfahren als auch der Schlüssel aus dem Skript ergeben. Somit sieht jeder, der den JavaScript-Code ausführt, die Mail-Adresse im Klartext – das ist notwendig, um sie menschlichen Besuchern bekanntzugeben.
Der eigentliche Vorteil dieser Methode liegt darin, dass ein Client, der JavaScript nicht interpretiert, eine E-Mail-Adresse nicht erkennt. Derzeit – und vermutlich auch in absehbarer Zukunft – nehmen Spider-Programme diesen Aufwand nicht auf sich.
Die vorgestellten JavaScript-Ansätze lassen sich beliebig kombinieren, beispielsweise indem man die Verschlüsselung aus Listing 3 durch den JavaScript-Link aus Listing 2 ergänzt.
Leider haben nicht nur die Adresssammler Mühe mit JavaScript, auch Text-Browser wie Lynx sind überfordert. Zudem schalten viele Nutzer grafischer Browser JavaScript aus Sicherheitsgründen aus. Dass man diese mit solchen JavaScript-Seiten die Möglichkeit zur Kontaktaufnahme beraubt, sollte man im Kopf behalten.
Die beschriebenen Verschleierungsmethoden funktionieren nicht nur bei E-Mail-Adressen sondern auch bei Web-Links. Überall verwendet würde das Adresssammler gänzlich ausbremsen, allerdings ebenso Suchmaschinen wie Google und auch menschliche Surfer ohne JavaScript-Browser.
Wer die Leser seiner Homepage nicht von JavaScript abhängig machen möchte, dem bleibt ein einfacher Trick, der allerdings ebenfalls die Nutzer von Text-Browsern ausschließt: Man stellt eine Grafikdatei auf die Seite, die die E-Mail-Adresse als Bild enthält. Da die Adresse nicht als Text auf der Seite steht, haben Sammler keine Chance; die Verwendung von Texterkennungs-Software, um solche Adressen automatisch auszuwerten, bleibt für Spammer utopisch – schließlich könnte jede Grafik im Web eine Mail-Adresse enthalten. Da das Teledienstegesetz keine anklickbare oder auf sich selbst verlinkte “Adresse der elektronischen Post” verlangt, steht es dieser Lösung nicht im Wege.
Auch eine solche Grafik kann man verlinken, ohne die E-Mail-Adresse preiszugeben: Ein Kontaktformular ohne sichtbare Zieladresse leitet erwünschte Mails vom Besucher zum Betreiber der Seite.
Eine Variante zur Bildlösung wäre eine Flash-Animation, die die Adresse auch anklickbar einbinden könnte, doch damit grenzt man noch mehr Benutzer aus als mit einer gewöhnlichen Grafikdatei.
Das Handwerk legen
Wer über eine eigene Internet-Domain verfügt, bekommt mit einer dynamischen Web-Seite heraus, woher adressensammelnde Suchmaschinen kommen: Auf der Seite gibt man einen E-Mail-Link an, der sich ständig ändert, beispielsweise zusammengesetzt aus Uhrzeit, Datum und der IP-Adresse des aktuellen Besuchers, die dieser beim Laden einer Homepage zwangsläufig übermittelt [2].
Enthält man später unerwünschte Werbung an eine so generierte Adresse, liest man daraus den Ursprung einer Spam-Mail ab – für den Rechtsweg ist dies wichtig.
Der Autor
Der Autor ist in München als freiberuflicher IT-Berater und Dozent tätig. Die Bekämpfung von Spam – nicht nur mit technischen Mitteln – zählt zu seinen Arbeitsschwerpunkten.
Glossar
-
Heuristiken
-
(griechisch “heuriskein”: finden, entdecken) Suche nach Mustern an Hand von Faustregeln, die mit hoher Wahrscheinlichkeit zum Erfolg führen. Die Ergebnisse sind damit theoretisch nicht zuverlässig, doch der Suchvorgang ist wesentlich schneller als eine exakte Berechnung.
-
SMTP
-
Das “Simple Mail Transfer Protocol” nimmt E-Mails entgegen und leitet sie weiter.
-
robots.txt
-
Dateien dieses Namens auf Web-Servern enthalten u.a. Informationen darüber, welche Seiten Suchmaschinen nicht automatisch durchsuchen sollen.
-
HTML-Entity
-
Diese HTML-Kodierung drückt Zeichen in Form einer Kombination aus dem Präfix &#, anschließendem ASCII-Code und am Ende einem Semikolon aus: “u” entspricht “u”.
-
ASCII
-
Der “American Standard Code for Information Interchange” weist allen Buchstaben, Ziffern und Sonderzeichen eine eigene Zahl, den ASCII-Code, zu.
-
JavaScript
-
Skriptsprache zum Einsatz in Web-Seiten. Ist JavaScript im Browser aktiviert, interpretiert er die Sprache und führt eingebettete Befehle aus.
-
XOR
-
Das “Exklusive Oder” ist eine Rechenmethode aus der binären Mathematik, das dazugehörige Verknüpfungssymbol lautet in JavaScript ^. Mit ihr lassen sich Daten symmetrisch verschlüsseln.
-
Flash
-
Mit diesem Format der Firma Macromedia lassen sich Animationen, Filme, Töne und Bilder kombinieren und auf Web-Seiten einbinden. Zum Betrachten benötigt der Browser ein Erweiterungs-Plugin.
Infos
[1] “Why am I getting all this spam?”: http://www.cdt.org/speech/spam/030319spamreport.html
[2] Adressensammler identifizieren: http://spamfang.rehbein.net/
[3] robots.txt: http://www.robotstxt.org/
[4] Gesetz über die Nutzung von Telediensten (TDG): http://bundesrecht.juris.de/bundesrecht/tdg/





