

Wer von MS Office auf Open- oder StarOffice umsteigt, vermisst Access. Doch mit PostgreSQL lassen sich die beiden Office-Suites problemlos um eine richtige Datenbank erweitern.
Ein Office-Komplettpaket ohne Desktop-Datenbank sorgt heutzutage eher für Stirnrunzeln. Ehe man jedoch an die Leistungsgrenzen dieser “Zugabe” stößt, lohnt sich die Überlegung, gleich ein richtiges und zukunftssicheres Datenbank-Management-System (DBMS) zu verwenden.
Unter Linux bietet sich die SQL-Datenbank PostgreSQL an, bei der mehrere Nutzer zeitgleich ein und dieselbe Tabelle bearbeiten können, solange sie zu einem Zeitpunkt verschiedene Einträge (alias Tabellen-Zeilen) manipulieren. Dieses DBMS ist eines der wenigen freien Systeme, die auch mit Fremdschlüsseln und Transaktionen umgehen können. Über die ODBC-(“Open Database Connectivity”-)Schnittstelle lässt es sich an StarOffice oder OpenOffice anpfropfen.
Benötigte Programmpakete
| postgresql | PostgreSQL-Client, zu installieren auf dem Server-Rechner sowie optional auf Linux-Clients, die für die Fernadministration des DBMS benutzt werden |
| postgresql-server | PostgreSQL-Datenbanksystem, der eigentliche Server |
| postgresql-odbc | ODBC-Treiber für PostgreSQL, benötigt auf dem Server- und jedem Linux-Client-Rechner, der via Star-/OpenOffice auf die Datenbank zugreifen soll |
| unixODBC | ODBC-Treiber-Manager für Linux, benötigt auf dem Server und jedem Linux-Client |
| postgresql-tcl | Schnittstelle zur Skriptsprache Tcl, benötigt auf dem Server sowie optional auf zur Fernadministration gedachten Linux-Clients |
| postgresql-tk | pgaccess-Client, eine grafische Benutzerschnittstelle, die auf dem Server sowie optional auf Linux-Clients für die Fernadministration gebraucht wird (Abbildung 1) |
| unixODBC-kde (Red Hat), qt-ODBC (Red Hat), unixODBC-gui-gtk (SuSE und Mandrake), unixODBC-gui-qt (SuSE und Mandrake), unixodbc-bin (Debian), godbcconfig (Debian) | Grafische Konfigurationstools für odbc.ini und odbcinst.ini |
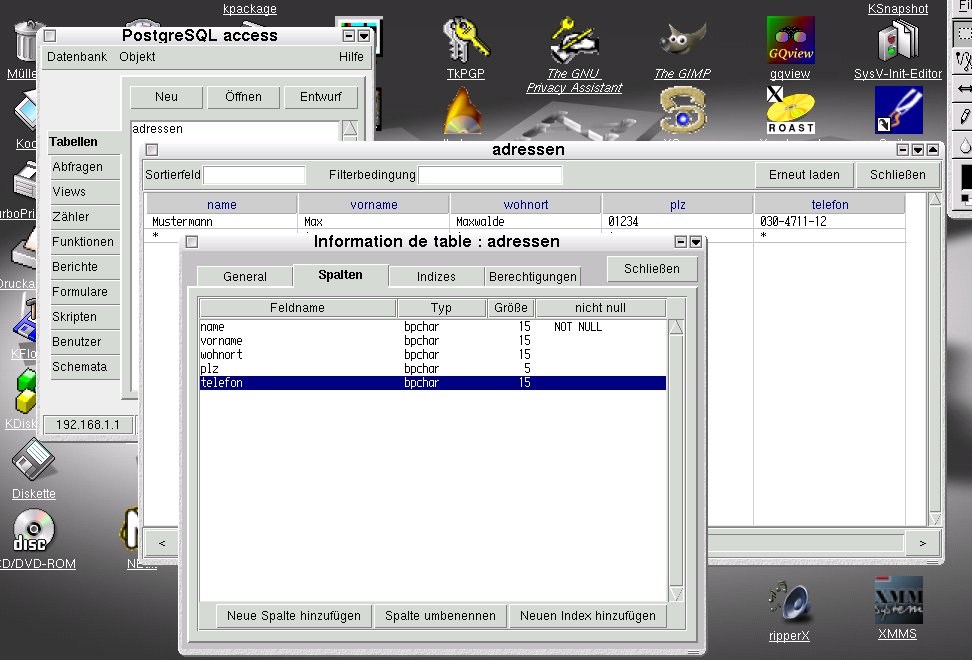
Abbildung 1: Mit pgaccess lassen sich auch ohne SQL-Kenntnisse Tabellen in der Datenbank anlegen
Am Anfang war PostgreSQL
Zu diesem Zweck gilt es zunächst, die Datenbank selbst und einige Hilfspakete zu installieren. Tabelle 1 gibt einen Überblick: Die Paketbezeichnungen sind bei den gängigen Distributionen nahezu identisch. Geringfügige Abweichungen gibt es bei den ODBC-Konfigurationstools. Platz sollte man nicht zu knapp einplanen: Die paar MByte PostgreSQL-Paket entpuppen sich nach dem Anlegen der ersten Datenbank schnell als Plattenplatzfresser von mehr als 50 MByte.
Kommen für die eigene Distribution gedachte Binärpakete zum Einsatz, legt der Paketmanager beim Einspielen des Server-Pakets den Unix-User postgres als Datenbank-Administrator sowie die Gruppe postgres an. Zudem erzeugt er das Home-Verzeichnis des Datenbank-Admin-Users unterhalb von /var/lib oder /etc, das die Konfiguration des DBMS enthält, und ein Arbeitsverzeichnis, in dem die Datenbanken selbst abgelegt werden. Dieses heißt pgsql oder postgres und befindet sich meist in /usr/lib. Die Datenbanken landen dann in /usr/lib/pgsql/data oder /usr/lib/postgres/data. Um die Verwirrung komplett zu machen, trennen manche Distributionen Arbeits- und Home-Verzeichnis gar nicht erst voneinander: SuSE 8.0 legt das data-Verzeichnis im postgres-Home-Verzeichnis /var/lib/pgsql ab.
Wer PostgreSQL aus dem Quellcode kompiliert oder ältere Binärpakete (vor Version 7) einspielt, muss selbst dafür Sorge tragen, dass User, Gruppe und Verzeichnisse angelegt werden. Nach der Installation bleiben noch einige Aufgaben für root übrig: So sollte der User postgres mit dem Kommandozeilen-Befehl
passwd postgres
ein Passwort zugewiesen bekommen. Zudem empfiehlt es sich, die Rechte am Home- und Arbeitsverzeichnis von postgres zu kontrollieren:
ls -l /var/lib | grep pgsql
Gibt dieser Befehl nichts aus, suchen Sie mit grep nach dem String postgres. In Ordnung ist das folgende Ergebnis:
drwx—— 4 postgres postgres 1024 Okt 16 21:34 pgsql
Sollte statt postgresroot stehen, passen Sie die Eigentumsverhältnisse an:
cd /var/lib chown -R postgres:postgres pgsql
Wenn es wie bei SuSE 8.0 keine extra postgres-Gruppe gibt, darf das Verzeichnis auch in Obhut der Gruppe daemon verbleiben. Benutzt Ihre Distribution ein separates Arbeitsverzeichnis /usr/lib/psql oder /etc/postgres, stellen Sie auf gleiche Weise sicher, dass es dem Datenbank-User postgres gehört. Bei Debian finden Sie an beiden Stellen Links vor, die auf das jeweils richtige Verzeichnis verweisen. Ist dies auf anderen Distributionen der Fall, müssen Sie zudem die Besitzverhältnisse des Ziel-Ordners überprüfen.
Start des Datenbanksystems
Mit der Installation landet in /etc/init.d (bzw. /etc/rc.d/init.d) ein Skript zum Starten und Beenden von PostgreSQL. Ruft man dieses (im Beispiel heißt es postgres, bei SuSE hingegen postgresql) mit der Option start auf, startet das DBMS (Kasten 1):
/etc/init.d/postgres start
Kasten 1: Das Kreuz mit dem Pfad
Prädestiniert zum Aufruf des PostgreSQL-Init-Skripts ist selbstverständlich der User postgres. Doch wenn dieser unter SuSE (getestete Version: 8.0) /etc/init.d/postgresql start aufruft, kommt er nicht weit:
Starting PostgreSQL /etc/init.d/postgresql: checkproc: command not found
done
Die Ursache: Der Suchpfad des Users postgres enthält das Verzeichnis mit dem im Skript benutzten Programm checkproc nicht. Fügt man ihn vor dem Aufruf des Init-Skripts mit
export PATH=$PATH:/sbin
hinzu, kann auch postgres (und nicht nur root) das DBMS über das Init-Skript starten. (Patricia Jung)
Vor dem Herunterfahren des Computers stoppt man es durch Aufruf des Skripts mit der Option stop. Sinnvollerweise passiert dieses Starten und Stoppen beim Wechsel des Runlevels [2] automatisch; viele Distributionen sehen das bereits ab Installation vor. Wenn nicht, setzen Sie die nötigen Links, bei SuSE 8.0 etwa wie in Listing 1, oder überlassen linuxconf oder ksysv diese Aufgabe.
Listing 1
Erweitern der Runlevel um das PostgreSQL-Startskript (SuSE 8.0)
ln -s /etc/init.d/postgresql /etc/init.d/rc3.d/S97postgresql
ln -s /etc/init.d/postgresql /etc/init.d/rc5.d/S97postgresql
ln -s /etc/init.d/postgresql /etc/init.d/rc1.d/K97postgresql
ln -s /etc/init.d/postgresql /etc/init.d/rc6.d/K97postgresql
@KE:
Bei Bedarf starten Sie die Datenbank manuell mit dem Befehl postmaster:
/usr/lib/postgresql/bin/postmaster -i -D /var/lib/postgres/data &
Der Pfad zum Programm variiert, bei SuSE findet man es beispielsweise unter /usr/bin/postmaster. Die Option -i schaltet den Zugang zur Datenbank über’s Netz an; dem -D folgt der Pfad zu data.
Damit der Netzzugriff auch dann funktioniert, wenn das Init-Startskript die Datenbank startet, kontrollieren Sie, ob in der postmaster-Konfigurationsdatei postgresql.conf im data-Verzeichnis die Zeile tcpip_socket = 1 oder tcpip_socket = “true” (ohne Kommentarzeichen am Zeilenanfang) steht. Dann können Sie auch beim postmaster-Aufruf über die Kommandozeile den Parameter -i weglassen.
Sollte der Datenbankserver nach einem PC-Absturz mit der Behauptung
pg_ctl: Another postmaster may be running pg_ctl: cannot start postmaster
nicht mehr starten wollen, enthält das data-Verzeichnis eine Datei postmaster.pid mit der ProzessID des alten postmaster-Prozesses. Sie muss gelöscht werden, bevor der neue Datenbank-Server starten kann.
Neue Nutzer, neue Datenbank
Ein Datenbanksystem ist eine Welt in sich, und die will zunächst mit Datenbank-Usern bevölkert werden. Zum Anlegen kommt ein extra Kommando namens createuser zum Einsatz, das der für das DBMS zuständige Unix-User postgres ausführt (Listing 2).
Listing 2
Datenbank-Benutzer anlegen
pjung@linux:~> su - postgres Password: Passwort_fuer_User_postgrespostgres@linux:~> createuser joernShall the new user be allowed to create database ? (y/n) yShall the new user be allowed to create more new users ? (y/n) y CREATE USER
Der neue Datenbankbenutzer joern bekommt dank der beiden Ja-Antworten (y für “yes”) in diesem Beispiel das Recht, neue Datenbanken zu erstellen und weitere Datenbanknutzer anzulegen – er ist soeben zum Datenbank-Superuser geworden. Wenn joern von letzterer Fähigkeit Gebrauch macht, gibt er diese Berechtigungen natürlich nicht weiter – es sei denn, das System benötigt noch einen weiteren Administrator.
createuser erzeugt allerdings nur Datenbankbenutzer, keine Unix-Accounts. Existiert zusätzlich zum Datenbank-User joern auch ein Unix-User joern, kann dieser nun mit
joern@linux:~> createdb test_db CREATE DATABASE
eine neue Datenbank anlegen. Die Meldung CREATE DATABASE meldet, dass die Datenbank test_db nun existiert. Will ein anderer Unix-User als Datenbank-User joern die Datenbank erzeugen (etwa weil es joern nur als Datenbank-, nicht aber als Unix-Benutzer gibt), muss dies als Kommandozeilenoption mit vermerkt werden:
pjung@linux:~> createdb -U joern test_db
Jetzt haben Benutzer durch die Eingabe von psql in der Konsole die Möglichkeit, den Datenbank-Client aufzurufen (Listing 3). Auch hier kann die Angabe des Datenbank-User-Namens (im Beispiel joern) entfallen, wenn Unix- und Datenbank-Benutzername übereinstimmen. Der =#-Prompt signalisiert, dass der User sich in der SQL-Shell befindet.
Listing 3
Kommandozeilen-Interaktion mit dem DBMS
pjung@linux:~> psql test_db joern
Welcome to psql, the PostgreSQL interaktive terminal.
Type: \copyright for distributions terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
test_db=#
Zugang nicht für alle
Wird das DBMS so gestartet, dass es sich über Internet-Verbindungen ansprechen lässt, soll sich darauf natürlich nicht die ganze Welt vergnügen dürfen. Daher legt die Datei pg_hba.conf im data-Verzeichnis fest, welche Rechner Zugriff auf die Datenbank bekommen. Den größten Teil der Datei macht die durch #-Zeichen am Zeilenanfang auskommentierte Eigendokumentation aus. Fügt man am Datei-Ende Zeilen nach dem Muster
host all IP-Nummer Netzwerkmaske trust
an, werden alle Datenbanken auf dem PostgreSQL-Server für alle Computer aus dem angegebenen Netzwerksegment erreichbar. (Statt all lassen sich auch einzelne Datenbanknamen aufführen.) So erlaubt
host all 192.168.1.0 255.255.255.0 trust
aufgrund der Netzwerkmaske255.255.255.0 allen Maschinen mit einer auf 192.168.1. beginnenden IP-Adresse den Zugriff. Einen eventuellen Eintrag
host all 0.0.0.0 0.0.0.0 reject
kommentiert der Admin aus, denn damit verweigert (reject) sich das DBMS allen Fremdrechnern.
Nach einem Neustart des DBMS können Sie nun von einem anderen Rechner im LAN darauf zugreifen – vorausgesetzt, der PostgreSQL-Client psql ist dort installiert. Zu diesem Zweck geben Sie mit der Option -h die Adresse des Datenbank-Servers (im Beispiel 192.168.1.12) an:
psql -h 192.168.1.12 -d test_db
Ob Sie die Option -d vor dem Namen der Ziel-Datenbank dazuschreiben, ist reine Geschmacksfrage. Im Erfolgsfall sehen Sie jetzt das gleiche Bild der SQL-Shell wie in Listing 3.
Eine ODBC-Verbindung, bitte!
Die Datenbank steht, nun muss lediglich noch das Office-Paket darauf zugreifen. Zu diesem Zweck kontaktiert es PostgreSQL plattformunabhängig über die ODBC-Schnittstelle, doch bevor dies gelingt, bleibt ein wenig Konfigurationsarbeit übrig. Um die passenden Konfigurationsdateien /etc/odbc.ini und /etc/odbcinst.ini zu erstellen, ruft root auf dem Datenbank-Server-Rechner sowie auf jedem Client, der auf das DBMS zugreifen soll, eines der ODBC-Konfigurationsfrontends, je nach Geschmack (und Installationsumfang) das Qt-basierte Tool ODBCConfig oder das GTK-Pendant gODBCConfig, auf; unter KDE am besten mit
kdesu ODBCConfig &
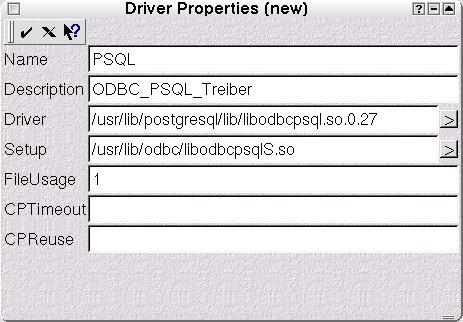
Abbildung 2: ODBC-Treiber hinzufügen mit ODBCConfig
Zunächst wählt der Admin in diesem ODBC Data Source Administrator den Reiter System DNS an. Ein Klick auf die Schaltfläche Add… führt zu einer Maske mit der Überschrift Select a Driver. Der Button Add… ruft nun endlich den gewünschten Dialog Driver Properties (new) auf den Plan, in den die ODBC-Bibliotheken libodbpsql.so und libodbcpsqlS.so als Driver bzw. Setup eingetragen werden (Abbildung 2). Sie befinden sich je nach Distribution an etwas unterschiedlichen Stellen des Dateisystems (bei SuSE 8.0 etwa /usr/lib), die man am besten mit locate ermittelt. Zum Bestätigen der Angaben dient bei ODBCConfig das “Save and Exit“- Häkchen oben links. Zudem markiert der Admin den Eintrag in der Maske Select a Driver, und klickt auf Ok.
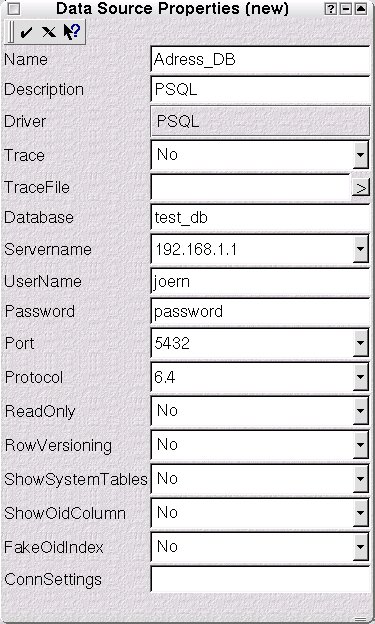
Abbildung 3: Die Eigenschaften der Datenquelle fein justiert
Im nun erscheinenden Dialog Data Source Properties (Abbildung 3) bleiben mit dem Namen der ODBC-Verbindung, dem Namen der zu verwendenden PostgreSQL-Datenbank (Database, im Beispiel test_db), der Server-Adresse (Servername), dem Datenbank-Benutzer-Namen (UserName) und dem Passwort noch ein paar Punkte auszufüllen. Das im Punkt Password gewählte Passwort wird bei jeder ODBC-Client-Verbindung abgefragt.
Und nun mit Office!
Damit ein auf den Linux-Desktop-Rechnern installiertes Office-Paket auf die ODBC-Verbindung zugreifen kann, muss dort die Bibliothek libodbc.so aus dem Paket unixODBC vorhanden sein. Gibt es keine Datei dieses Namens, sondern z. B. nur eine libodbc.so.1.0.0, legt root einen Link an:
ln -s /usr/lib/libodbc.so.1.0.0 /usr/lib/libodbc.so
Nun starten die Benutzer Star- bzw. OpenOffice (neu) und öffnen den Datenbank-Explorer durch Klick auf das Tabellen-Symbol Datenquellen auf der linken Symbolleiste (unterhalb des Fernglas-Icons). Im Explorer-Feld auf der linken Seite wählen sie aus dem Kontext-Menü der rechten Maustaste den Punkt Administrate Data Source bzw. Datenquellen verwalten … (Abbildung 4).
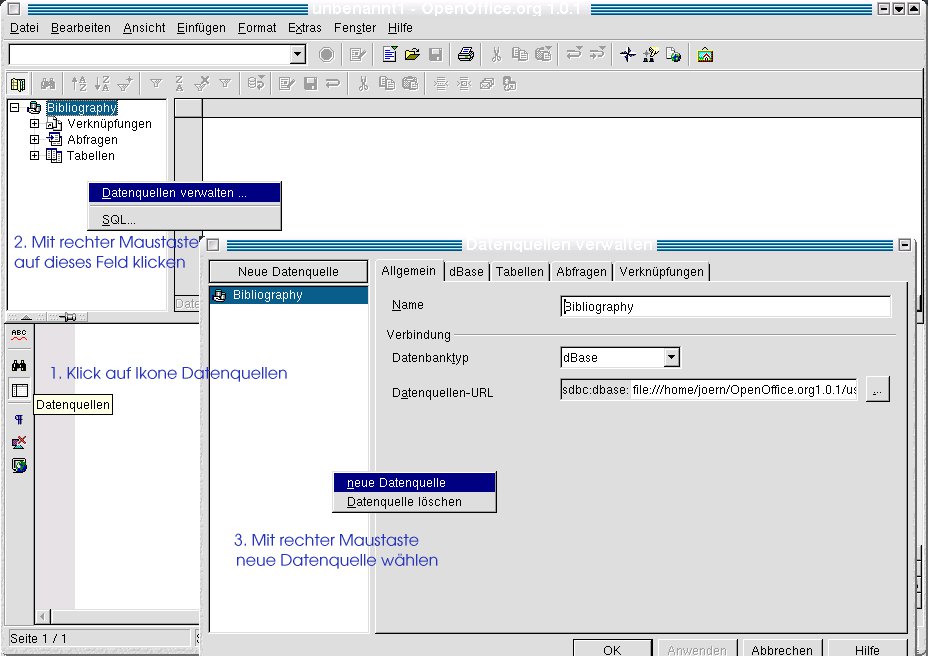
Abbildung 4: Schritte zum Anbinden der Datenbank an die Office-Software
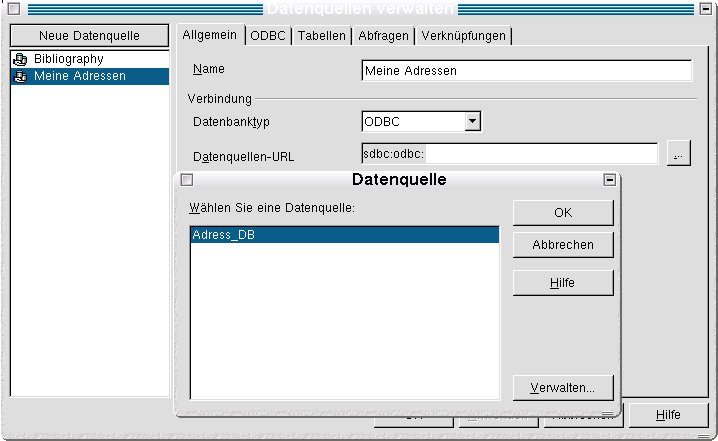
Abbildung 5: Welche Datenbank darf’s sein?
Das mit New Data Source (Neue Datenquelle) überschriebene Feld im neuen Dialog ermöglicht es über sein Kontextmenü, eine New Data Source bzw. neue Datenquelle einzurichten. In der Karteikarte General (in der deutschen Version Allgemein) vergeben Sie nun im Namensfeld den Namen, unter dem die Datenbank auf dem Client anzusprechen sein soll – wir wählen Meine Adressen. Im Feld Database type (Datenbanktyp) wählen Sie ODBC aus. Der Such-Knopf … hinter Data source URL (Datenquellen-URL) liefert die vorhin von root konfigurierten Datenquellen zur Auswahl zurück, in unserem Fall Adress_DB (Abbildung 5).
Tragen Sie in der Karteikarte ODBC den User-Namen ein, und kreuzen Sie Passwort erforderlich an (sofern der Admin im ODBC Data Source Administrator eines gesetzt hat). In der PostgreSQL-Grundeinstellung kann jeder Datenbank-Nutzer lesend auf die Datenbank zugreifen, wenn dies die pg_hba.conf nicht ausschließt.
Nun können Sie sich nach Anwahl der Karteikarte Tables bzw. Tabellen bei der Datenbank anmelden und die Tabellen auswählen, die sichtbar sein sollen. In unserem Fall gibt es mangels angelegter Tabellen in der test_db-Datenbank nur die Auswahl Alle Tabellen.
Sobald Sie jedoch im Datenbank-Explorer auf das Plus-Zeichen neben der Datenquelle Meine Adressen klicken, finden Sie im Kontextmenü zum Eintrag Tabellen den Punkt Neu / Tabelle / Tabellenentwurf (StarOffice 5.2) oder neuer Tabellenentwurf (OpenOffice, Abbildung 6). Auf seine Auswahl hin öffnet sich eine Maske zur Tabellenerstellung.
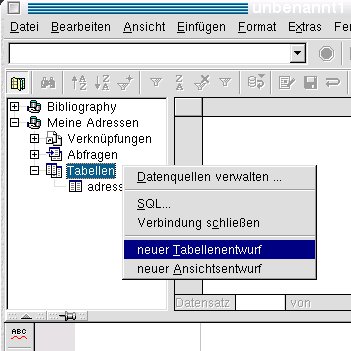
Abbildung 6: Neuer Tabellenentwurf gewünscht
Eine Tabelle für Adressen
Eine Tabelle besteht aus Feldern, die einen ihren späteren Inhalt beschreibenden Namen bekommen und lediglich Daten eines bestimmten Typs (z. B. Text, Fließkomma-Zahl oder Datum) aufnehmen. Damit sich ein Datenbankeintrag überhaupt eindeutig ansprechen lässt, braucht man einen Primärschlüssel: Leider kann es mehrere Müllers in einer Adressdatenbank geben, sogar mehrere Peter Müllers, so dass sich die naheliegenden Namen nicht als solcher eignen. Der Ausweg ist eine “laufende Nummer”.
Daher bekommt der erste Eintrag in der Tabellenentwurfstabelle den Feldnamen Nr, für den wir den Feldtyp Integer [int4] festlegen. Damit beschränkt sich die Größe der Adressdatenbank auf eine Milliarde Einträge, wie die Länge 10 bei den Feldeigenschaften zeigt. Zum Primärschlüssel wird diese zukünftige Tabellenspalte über das Kontextmenü, das man per rechtem Mausklick auf das kleine Dreieck in der Randspalte links neben dem Feldnamen erhält – ein kleines Schlüsselsymbol markiert sie anschließend als solchen (Abbildung 7).
Zudem fügen wir weitere Felder wie Name, Vorname und Wohnort ein. Will man sicherstellen, dass ein Feld, etwa der Name, unbedingt ausgefüllt wird, wählt man bei der Feldeigenschaft Eingabe erforderlich den Wert Ja aus. Als Feldtyp bietet sich meist Text variabler Länge (Text [ varchar ]) an – sogar für Postleitzahl- und Hausnummernfelder, damit es bei britischen Postleitzahlen, die Buchstaben enthalten, und der Hausnummer 2a keine Probleme gibt.
Beim Geburtstag empfiehlt sich hingegen der Datentyp Datum [ date ]. Diesen formatieren wir noch etwas spezieller über den Knopf mit den drei Punkten neben Format-Beispiel. Da das gewünschte Datumsformat a la 01.02.2003 nicht zur Auswahl steht, tragen wir in der unteren Zeile des Dialogs unter Format-CodeTT.MM.JJJJ ein und betätigen mit OK. Wichtig dabei ist, dass der Punkt Sprache auf Deutsch steht (Abbildung 7).
Ein Klick auf das Diskettensymbol speichert die neue Tabelle unter einem passenden Namen wie adressen. Im Explorer lässt sie sich nun mit Daten füllen (Abbildung 8). Mit dem Fernglas-Symbol durchsuchen Sie die im Client dargestellten Datensätze, das Trichter-Symbol führt Abfragen auf SQL-Basis aus.
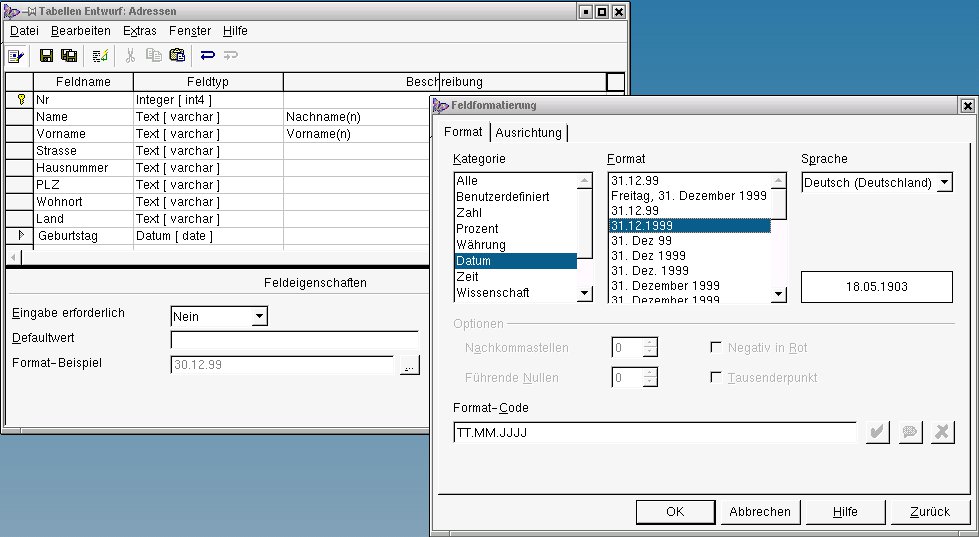
Abbildung 7: Entwurf der Adresstabelle
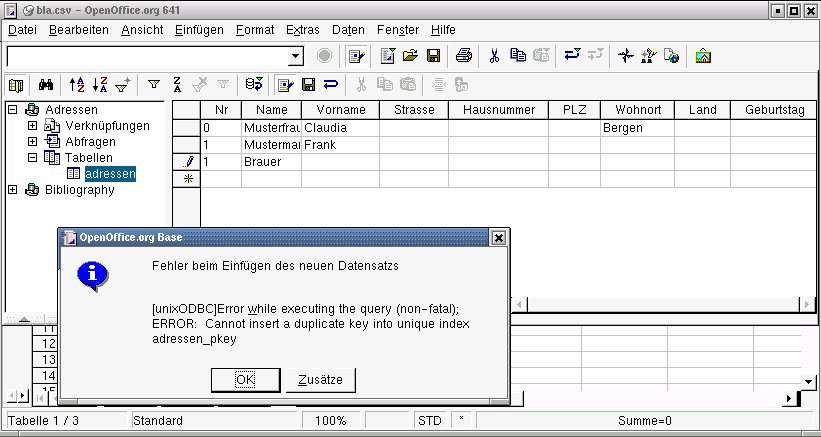
Abbildung 8: Ein Primärschlüssel darf nicht mehrfach verwendet werden
Kasten 2: ODBC-Konfiguration auf Windows-SQL-Clients
Der ODBC-PostgreSQL-Zugriff von Star- und OpenOffice auf einem Windows-Client lässt sich genau wie auf den Linux-Clients einrichten. Vorher muss lediglich der PostgreSQL-ODBC-Treiber für Windows von ftp://ftp.postgresql.org/pub/odbc eingespielt werden. Die zu Redaktionsschluss aktuelle Version heißt psqsqlodbc-07_02_0001.zip. Anschließend finden Sie ein ODBC-Icon in der Systemsteuerung; ein Klick darauf ruft den ODBC Data Source Administrator auf.
Beim ersten Zugriff auf die PostgreSQL-Datenbank haben die Windows-User zunächst erstmal nur Leserechte. Um dieses Manko zu beheben, entfernen Sie im Reiter System DNS bei der ODBC-Konfiguration unter Options (Advanced) die beiden “Read Only“-Häkchen sowohl bei Driver als auch bei Data Source (Abbildung 9). (Jörn Eisenkrätzer)
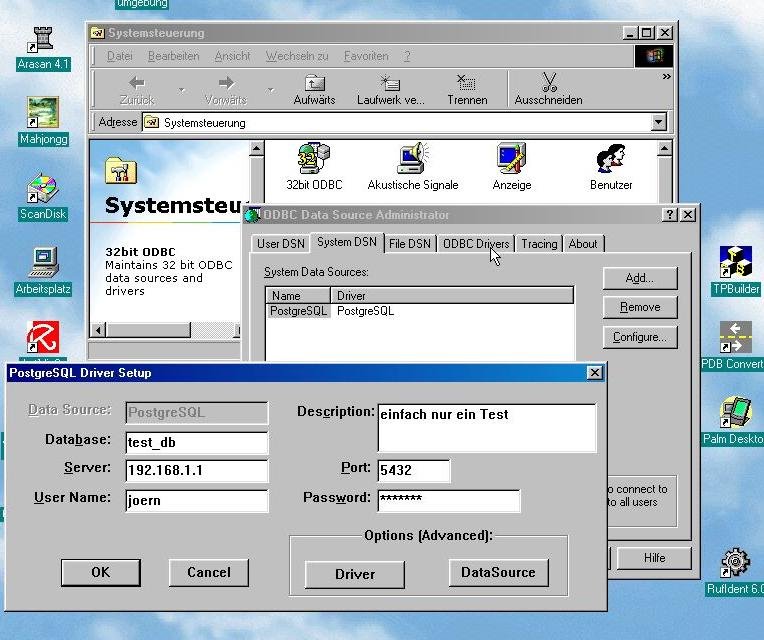
Abbildung 9: ODBC-Zugriff unter Windows
Wem die Datenbankdarstellung in Tabellenform nicht gefällt, kann – sobald die Tabellenstruktur angelegt ist – über Datei / AutoPilot / Formular … eine Datenbankmaske bauen. Der AutoPilot führt über einen Dialog mit Auswahlkriterien durch den Formular-Design-Prozess; nachträgliche Änderungen am Formular sind im Nachhinein immer möglich.
Her mit den alten Access-Daten!
Um Daten von anderen Systemen auf das neue PostgreSQL-Client-Server-System zu migrieren, muss zunächst deren Tabellenstruktur mit der exakten Spaltenanzahl und den richtigen Datentypen nachgebaut werden. Anschließend füllt man sie mit einer als CSV-Tabelle gespeicherten Datenkopie.
Die Daten einer Access-Datenbank lassen sich beispielsweise in der Tabellenansicht in die Zwischenablage kopieren, in eine leere Excel-Tabelle einfügen und im .xls-Format speichern. Diese Datei laden Sie in OpenOffice und wählen Datei / Speichern unter aus. Unter Dateityp entscheiden Sie sich für Text CSV, vergeben einen Dateinamen und drücken den Speichern-Knopf. Eine Maske (Abbildung 10) fragt nun nach dem Ziel-Zeichensatz, dem Feldtrenner und dem Texttrenner. Als Trennzeichen zwischen Feldern legen Sie zum Beispiel das Pipe-Zeichen fest. Zeichenketten sollen nicht wie vorgeschlagen in doppelte Anführungszeichen gesetzt werden, weshalb Sie ins Texttrenner-Feld ein Leerzeichen schreiben.
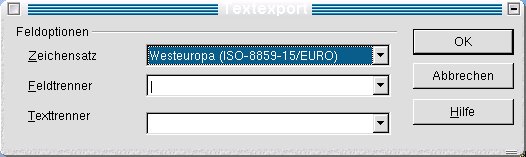
Abbildung 10: CSV-Trennzeichen festlegen
Diese so aufbereitete Datei kopieren Sie nun mit psql in die zuvor angelegte PostgreSQL-Tabelle:
> psql Datenbankname […]Datenbankname=# COPY Tabellenname FROM '/Pfad/Datenkopie.csv' DELIMITERS '|';
Der Pfad und der Dateiname sowie das Trennzeichen werden in einfache Hochkommas gesetzt. Geht alles glatt, quittiert PostgreSQL dies mit der Meldung COPY. Im Fehlerfall macht sich das DBMS entsprechend bemerkbar, indem es auf die Zeilennummer der Import-Datei hinweist, in der der Konflikt auftrat.
So gibt es Probleme, wenn die Länge eines Datenfelds in der neuen Tabelle kürzer definiert ist als die eines importierten Zelleninhalts oder gar die Datentypen nicht übereinstimmen. Oft enthält die neue Tabelle aus Versehen auch mehr oder weniger Spalten als die alte. Eine weitere Fehlerquelle sind leere Feldeinträge in der CSV-Datei, die in der neuen Tabelle nicht erlaubt sind, z. B. bei einer “NOT NULL“-Deklaration im Tabellenentwurf oder bei einem Datum.
Glossar
- Fremdschlüssel
- Eine Datenbank besteht aus Tabellen. Jede Tabelle hat einen Primärschlüssel, das ist eine Spalte oder eine Spaltenkombination, über die sich ein Datensatz eindeutig ansprechen lässt (z. B. die Kunden-, Artikel- oder Bestellnummer). Wenn der Primärschlüssel einer Tabelle gleichzeitig als Primärschlüssel einer anderen Tabelle fungiert, haben wir es mit einem Fremdschlüssel zu tun: Angenommen, ein Kunde aus der Tabelle “Kunden” bestellt einen Artikel aus der Tabelle “Artikel”. Dient die Kombination der Primärschlüssel von “Kunden” und “Artikel” als Primär- (und somit Fremd-) Schlüssel für die Tabelle “Bestellung”, so kann man vom Bestellungsdatensatz sowohl auf die Daten des Kunden als auch auf die Eigenschaften des Artikels zurückgreifen, ohne dass in “Bestellung” alle Kunden- und Artikeldaten mehrfach aufgeführt werden müssen.
- Transaktionen
- Eine Gruppe logisch zusammenhängender SQL-Anweisungen, die nur gemeinsam ausgeführt werden können. Wenn aus dieser Gruppe eine einzige Anweisung nicht korrekt abgewickelt werden kann, muss das DBMS auch alle anderen verwerfen. Ein Beispiel: Ein Mitarbeiter wechselt von einer Kostenstelle zu einer anderen. In Tabelle “Kostenstelle_A” wird er gelöscht und soll in Tabelle “Kostenstelle_B” eingefügt werden. Passiert nach dem Löschen und vor dem Wiedereinfügen eine Havarie, die zu zwei Tagen Rechnerausfall führt, bekommt der arme Mitarbeiter bei einer Datenbank, der der Transaktionsmechanismus fehlt, für zwei Tage weniger Geld, weil er keiner Kostenstelle zuzuordnen ist.
- Link
- Ein symbolischer Link ist eine Verknüpfung auf eine Datei, die, wenn er angesprochen wird, alle Dateibefehle an die verlinkte Zieldatei weiterleitet.
- Netzwerkmaske
- Gibt an, welche Stellen einer IP-Adresse das Netzwerk und welche den Rechner spezifizieren. Zu diesem Zweck rechnet man die vier Stellen der IP-Nummer und der Netzwerkmaske ins binäre Zahlensystem um: 255=2^7+2^6+2^5+2^4+2^3+2^2+2^1+2^0=11111111 (binär); 255.255.255.0 entspricht daher 11111111.11111111.11111111.00000000. Alle Stellen, an denen die binäre Netmask eine 1 zeigt, bilden in einer zum Netz gehörenden IP-Adresse die Netzwerkkennung, die mit Nullen aufgefüllten Stellen rechts daneben die Rechnerkennung. Damit ist 192.168.1. im Beispiel der Netzwerkanteil an der IP-Adresse und die Adressen 192.168.1.1 bis 192.168.1.254 können an Rechner des Netzes vergeben werden. (192.168.1.0 dient per Default als Netzwerkadresse, 192.168.1.255 als sogenannte Broadcast-Adresse; beide stehen daher nicht zum Verteilen zur Verfügung.)
- 192.168.x.x
- Die IP-Adressen 192.168.0.0 bis 192.168.255.255 (und damit auch das Netz 192.168.1.0 mit der Netzwerkmaske 255.255.255.0) sind für private Netze reserviert, deren Datenverkehr nicht ins Internet geroutet werden darf. (Da viele LANs diese Adressen verwenden, wäre nicht mehr klar, zu welchem privaten Netz die Pakete gehören.) Sollen solche Netze Zugang zum Internet bekommen, geht das nur über IP-Masquerading.
- CSV
- “Comma” oder “character separated values”, ein Datenformat, bei dem der Inhalt von Tabellen als ASCII-Text abgespeichert wird. Als Trennzeichen (“Delimiter”) zwischen Spalteneinträgen (“Feldtrenner”) dienen Kommata oder andere dedizierte Zeichen.
Infos
[1] Jens Hartwig: “PostgreSQL”, Addison-Wesley, ISBN 3-8273-1860-2
[2] Marc André Selig: “Von init an”, LinuxUser 12/2002, S. 26 ff.
[3] Andreas Bauer: “Daten fest im Griff”, LinuxUser 12/2001, S. 68 ff., http://www.linux-user.de/ausgabe/2001/12/068-datenbank/datenbank.html



